Y . K;Z I . What Is the Difference between Electronic and Electrical Devices?

When the field of electronics was invented in 1883, electrical devices had already been around for at least 100 years. For example:
- The first electric batteries were invented by a fellow named Alessandro Volta in 1800. Volta’s contribution is so important that the common volt is named for him. (There is some archeological evidence that the ancient Parthian Empire may have invented the electric battery in the second century BC, but if so we don’t know what they used their batteries for, and their invention was forgotten for 2,000 years.)
- The electric telegraph was invented in the 1830s and popularized in America by Samuel Morse, who invented the famous Morse code used to encode the alphabet and numerals into a series of short and long clicks that could be transmitted via telegraph. In 1866, a telegraph cable was laid across the Atlantic Ocean allowing instantaneous communication between the United States and Europe.
The answer lies in how devices manipulate electricity to do their work. Electrical devices take the energy of electric current and transform it in simple ways into some other form of energy — most likely light, heat, or motion. The heating elements in a toaster turn electrical energy into heat so you can burn your toast. And the motor in your vacuum cleaner turns electrical energy into motion that drives a pump that sucks the burnt toast crumbs out of your carpet.
In contrast, electronic devices do much more. Instead of just converting electrical energy into heat, light, or motion, electronic devices are designed to manipulate the electrical current itself to coax it into doing interesting and useful things.
That very first electronic device invented in 1883 by Thomas Edison manipulated the electric current passing through a light bulb in a way that let Edison create a device that could monitor the voltage being provided to an electrical circuit and automatically increase or decrease the voltage if it became too low or too high.
One of the most common things that electronic devices do is manipulate electric current in a way that adds meaningful information to the current. For example, audio electronic devices add sound information to an electric current so that you can listen to music or talk on a cellphone. And video devices add images to an electric current so you can watch great movies until you know every line by heart.
Keep in mind that the distinction between electric and electronic devices is a bit blurry. What used to be simple electrical devices now often include some electronic components in them. For example, your toaster may contain an electronic thermostat that attempts to keep the heat at just the right temperature to make perfect toast.
And even the most complicated electronic devices have simple electrical components in them. For example, although your TV set’s remote control is a pretty complicated little electronic device, it contains batteries, which are simple electrical devices.
Y . I/O Electronics
They store your money. They monitor your heartbeat. They carry the sound of your voice into other people's homes. They bring airplanes into land and guide cars safely to their destination—they even fire off the airbags if we get into trouble. It's amazing to think just how many things "they" actually do. "They" are electrons: tiny particles within atoms that march around defined paths known as circuits carrying electrical energy. One of the greatest things people learned to do in the 20th century was to use electrons to control machines and process information. The electronics revolution, as this is known, accelerated the computer revolution and both these things have transformed many areas of our lives. But how exactly do nanoscopically small particles, far too small to see, achieve things that are so big and dramatic? Let's take a closer look and find out!
What's the difference between electricity and electronics?

Electronics is a much more subtle kind of electricity in which tiny electric currents (and, in theory, single electrons) are carefully directed around much more complex circuits to process signals (such as those that carry radio and television programs) or store and process information. Think of something like a microwave oven and it's easy to see the difference between ordinary electricity and electronics. In a microwave, electricity provides the power that generates high-energy waves that cook your food; electronics controls the electrical circuit that does the cooking.
Photo: The 2500-watt heating element inside this electric kettle operates on a current of about 10 amps. By contrast, electronic components use currents likely to be measured in fractions of milliamps (which are thousandths of amps). In other words, a typical electric appliance is likely to be using currents tens, hundreds, or thousands of times bigger than a typical electronic one.
Analog and digital electronics

Photo: Digital technology: Large digital clocks like this are quick and easy for runners to read. Photo by Jhi L. Scott courtesy of US Navy.
There are two very different ways of storing information—known as analog and digital. It sounds like quite an abstract idea, but it's really very simple. Suppose you take an old-fashioned photograph of someone with a film camera. The camera captures light streaming in through the shutter at the front as a pattern of light and dark areas on chemically treated plastic. The scene you're photographing is converted into a kind of instant, chemical painting—an "analogy" of what you're looking at. That's why we say this is an analog way of storing information. But if you take a photograph of exactly the same scene with a digital camera, the camera stores a very different record. Instead of saving a recognizable pattern of light and dark, it converts the light and dark areas into numbers and stores those instead. Storing a numerical, coded version of something is known as digital.
Electronic equipment generally works on information in either analog or digital format. In an old-fashioned transistor radio, broadcast signals enter the radio's circuitry via the antenna sticking out of the case. These are analog signals: they are radio waves, traveling through the air from a distant radio transmitter, that vibrate up and down in a pattern that corresponds exactly to the words and music they carry. So loud rock music means bigger signals than quiet classical music. The radio keeps the signals in analog form as it receives them, boosts them, and turns them back into sounds you can hear. But in a modern digital radio, things happen in a different way. First, the signals travel in digital format—as coded numbers. When they arrive at your radio, the numbers are converted back into sound signals. It's a very different way of processing information and it has both advantages and disadvantages. Generally, most modern forms of electronic equipment (including computers, cell phones, digital cameras, digital radios, hearing aids, and televisions) use digital electronics.
Electronic components
If you've ever looked down on a city from a skyscraper window, you'll have marveled at all the tiny little buildings beneath you and the streets linking them together in all sorts of intricate ways. Every building has a function and the streets, which allow people to travel from one part of a city to another or visit different buildings in turn, make all the buildings work together. The collection of buildings, the way they're arranged, and the many connections between them is what makes a vibrant city so much more than the sum of its individual parts.The circuits inside pieces of electronic equipment are a bit like cities too: they're packed with components (similar to buildings) that do different jobs and the components are linked together by cables or printed metal connections (similar to streets). Unlike in a city, where virtually every building is unique and even two supposedly identical homes or office blocks may be subtly different, electronic circuits are built up from a small number of standard components. But, just like LEGO®, you can put these components together in an infinite number of different places so they do an infinite number of different jobs.
These are some of the most important components you'll encounter:
Resistors
These are the simplest components in any circuit. Their job is to restrict the flow of electrons and reduce the current or voltage flowing by converting electrical energy into heat. Resistors come in many different shapes and sizes. Variable resistors (also known as potentiometers) have a dial control on them so they change the amount of resistance when you turn them. Volume controls in audio equipment use variable resistors like these.Read more in our main article about resistors
Photo: A typical resistor on the circuit board from a radio.

Diodes
The electronic equivalents of one-way streets, diodes allow an electric current to flow through them in only one direction. They are also known as rectifiers. Diodes can be used to change alternating currents (ones flowing back and forth round a circuit, constantly swapping direction) into direct currents (ones that always flow in the same direction).Read more in our main article about diodes.
Photo: Diodes look similar to resistors but work in a different way and do a completely different job. Unlike a resistor, which can be inserted into a circuit either way around, a diode has to be wired in the right direction (corresponding to the arrow on this circuit board).

Capacitors
These relatively simple components consist of two pieces of conducting material (such as metal) separated by a non-conducting (insulating) material called a dielectric. They are often used as timing devices, but they can transform electrical currents in other ways too. In a radio, one of the most important jobs, tuning into the station you want to listen to, is done by a capacitor.Read more in our main article about capacitors.

Transistors
Easily the most important components in computers, transistors can switch tiny electric currents on and off or amplify them (transform small electric currents into much larger ones). Transistors that work as switches act as the memories in computers, while transistors working as amplifiers boost the volume of sounds in hearing aids. When transistors are connected together, they make devices called logic gates that can carry out very basic forms of decision making. (Thyristors are a little bit like transistors, but work in a different way.)Read more in our main article about transistors.
Photo: A typical field-effect transistor (FET) on an electronic circuit board.

Opto-electronic (optical electronic) components
There are various components that can turn light into electricity or vice-versa. Photocells (also known as photoelectric cells) generate tiny electric currents when light falls on them and they're used as "magic eye" beams in various types of sensing equipment, including some kinds of smoke detector. Light-emitting diodes (LEDs) work in the opposite way, converting small electric currents into light. LEDs are typically used on the instrument panels of stereo equipment. Liquid crystal displays (LCDs), such as those used in flatscreen LCD televisions and laptop computers, are more sophisticated examples of opto-electronics.Photo: An LED mounted in an electronic circuit. This is one of the LEDs that makes red light inside an optical computer mouse.

Electronic components have something very important in common. Whatever job they do, they work by controlling the flow of electrons through their structure in a very precise way. Most of these components are made of solid pieces of partly conducting, partly insulating materials called semiconductors (described in more detail in our article about transistors). Because electronics involves understanding the precise mechanisms of how solids let electrons pass through them, it's sometimes known as solid-state physics. That's why you'll often see pieces of electronic equipment described as "solid-state."
Electronic circuits
The key to an electronic device is not just the components it contains, but the way they are arranged in circuits. The simplest possible circuit is a continuous loop connecting two components, like two beads fastened on the same necklace. Analog electronic appliances tend to have far simpler circuits than digital ones. A basic transistor radio might have a few dozen different components and a circuit board probably no bigger than the cover of a paperback book. But in something like a computer, which uses digital technology, circuits are much more dense and complex and include hundreds, thousands, or even millions of separate pathways. Generally speaking, the more complex the circuit, the more intricate the operations it can perform.If you've experimented with simple electronics, you'll know that the easiest way to build a circuit is simply to connect components together with short lengths of copper cable. But the more components you have to connect, the harder this becomes. That's why electronics designers usually opt for a more systematic way of arranging components on what's called a circuit board. A basic circuit board is simply a rectangle of plastic with copper connecting tracks on one side and lots of holes drilled through it. You can easily connect components together by poking them through the holes and using the copper to link them together, removing bits of copper as necessary, and adding extra wires to make additional connections. This type of circuit board is often called "breadboard".
Electronic equipment that you buy in stores takes this idea a step further using circuit boards that are made automatically in factories. The exact layout of the circuit is printed chemically onto a plastic board, with all the copper tracks created automatically during the manufacturing process. Components are then simply pushed through pre-drilled holes and fastened into place with a kind of electrically conducting adhesive known as solder. A circuit manufactured in this way is known as a printed circuit board (PCB).

Photo: Soldering components into an electronic circuit. The smoke you can see comes from the solder melting and turning to a vapor. The blue plastic rectangle I'm soldering onto here is a typical printed circuit board—and you see various components sticking up from it, including a bunch of resistors at the front and a large integrated circuit at the top.
Although PCBs are a great advance on hand-wired circuit boards, they're still quite difficult to use when you need to connect hundreds, thousands, or even millions of components together. The reason early computers were so big, power hungry, slow, expensive, and unreliable is because their components were wired together manually in this old-fashioned way. In the late 1950s, however, engineers Jack Kilby and Robert Noyce independently developed a way of creating electronic components in miniature form on the surface of pieces of silicon. Using these integrated circuits, it rapidly became possible to squeeze hundreds, thousands, millions, and then hundreds of millions of miniaturized components onto chips of silicon about the size of a finger nail. That's how computers became smaller, cheaper, and much more reliable from the 1960s onward.

Photo: Miniaturization. There's more computing power in the processing chip resting on my finger here than you would have found in a room-sized computer from the 1940s!
Electronics around us
Electronics is now so pervasive that it's almost easier to think of things that don't use it than of things that do.Entertainment was one of the first areas to benefit, with radio (and later television) both critically dependent on the arrival of electronic components. Although the telephone was invented before electronics was properly developed, modern telephone systems, cellphone networks, and the computers networks at the heart of the Internet all benefit from sophisticated, digital electronics.
Try to think of something you do that doesn't involve electronics and you may struggle. Your car engine probably has electronic circuits in it—and what about the GPS satellite navigation device that tells you where to go? Even the airbag in your steering wheel is triggered by an electronic circuit that detects when you need some extra protection.
Electronic equipment saves our lives in other ways too. Hospitals are packed with all kinds of electronic gadgets, from heart-rate monitors and ultrasound scanners to complex brain scanners and X-ray machines. Hearing aids were among the first gadgets to benefit from the development of tiny transistors in the mid-20th century, and ever-smaller integrated circuits have allowed hearing aids to become smaller and more powerful in the decades ever since.
Who'd have thought have electrons—just about the smallest things you could ever imagine—would change people's lives in so many important ways?
A brief history of electronics
- 1874: Irish scientist George Johnstone Stoney (1826–1911) suggests electricity must be "built" out of tiny electrical charges. He coins the name "electron" about 20 years later.
- 1875: American scientist George R. Carey builds a photoelectric cell that makes electricity when light shines on it.
- 1879: Englishman Sir William Crookes (1832–1919) develops his cathode-ray tube (similar to an old-style, "tube"-based television) to study electrons (which were then known as "cathode rays").
- 1883: Prolific American inventor Thomas Edison (1847–1931) discovers thermionic emission (also known as the Edison effect), where electrons are given off by a heated filament.
- 1887: German physicist Heinrich Hertz (1857–1894) finds out more about the photoelectric effect, the connection between light and electricity that Carey had stumbled on the previous decade.
- 1897: British physicist J.J. Thomson (1856–1940) shows that cathode rays are negatively charged particles. They are soon renamed electrons.
- 1904: John Ambrose Fleming (1849–1945), an English scientist, produces the Fleming valve (later renamed the diode). It becomes an indispensable component in radios.
- 1906: American inventor Lee De Forest (1873–1961), goes one better and develops an improved valve known as the triode (or audion), greatly improving the design of radios. De Forest is often credited as a father of modern radio.
- 1947: Americans John Bardeen (1908–1991), Walter Brattain (1902–1987), and William Shockley (1910–1989) develop the transistor at Bell Laboratories. It revolutionizes electronics and digital computers in the second half of the 20th century.
- 1958: Working independently, American engineers Jack Kilby (1923–2005) of Texas Instruments and Robert Noyce (1927–1990) of Fairchild Semiconductor (and later of Intel) develop integrated circuits.
- 1971: Marcian Edward (Ted) Hoff (1937–) and Federico Faggin (1941–) manage to squeeze all the key components of a computer onto a single chip, producing the world's first general-purpose microprocessor, the Intel 4004.
- 1987: American scientists Theodore Fulton and Gerald Dolan of Bell Laboratories develop the first single-electron transistor.
- 2008: Hewlett-Packard researcher Stanley Williams builds the first working memristor, a new kind of magnetic circuit component that works like a resistor with a memory, first imagined by American physicist Leon Chua almost four decades earlier (in 1971).
Y . I/O I . Computers

It was probably the worst prediction in history. Back in the 1940s, Thomas Watson, boss of the giant IBM Corporation, reputedly forecast that the world would need no more than "about five computers." Six decades later and the global population of computers has now risen to something like one billion machines!
To be fair to Watson, computers have changed enormously in that time. In the 1940s, they were giant scientific and military behemoths commissioned by the government at a cost of millions of dollars apiece; today, most computers are not even recognizable as such: they are embedded in everything from microwave ovens to cellphones and digital radios. What makes computers flexible enough to work in all these different appliances? How come they are so phenomenally useful? And how exactly do they work? Let's take a closer look!
Photo: The IBM Blue Gene/P supercomputer at Argonne National Laboratory is one of the world's most powerful computers—but really it's just a super-scaled up version of the computer sitting right next to you. Picture courtesy of Argonne National Laboratory published on Flickr in 2009 under a Creative Commons Licence.
What is a computer?
Photo: Computers that used to take up a huge room now fit comfortably on your finger!.
A computer is an electronic machine that processes information—in other words, an information processor: it takes in raw information (or data) at one end, stores it until it's ready to work on it, chews and crunches it for a bit, then spits out the results at the other end. All these processes have a name. Taking in information is called input, storing information is better known as memory (or storage), chewing information is also known as processing, and spitting out results is called output.
Imagine if a computer were a person. Suppose you have a friend who's really good at math. She is so good that everyone she knows posts their math problems to her. Each morning, she goes to her letterbox and finds a pile of new math problems waiting for her attention. She piles them up on her desk until she gets around to looking at them. Each afternoon, she takes a letter off the top of the pile, studies the problem, works out the solution, and scribbles the answer on the back. She puts this in an envelope addressed to the person who sent her the original problem and sticks it in her out tray, ready to post. Then she moves to the next letter in the pile. You can see that your friend is working just like a computer. Her letterbox is her input; the pile on her desk is her memory; her brain is the processor that works out the solutions to the problems; and the out tray on her desk is her output.
Once you understand that computers are about input, memory, processing, and output, all the junk on your desk makes a lot more sense:
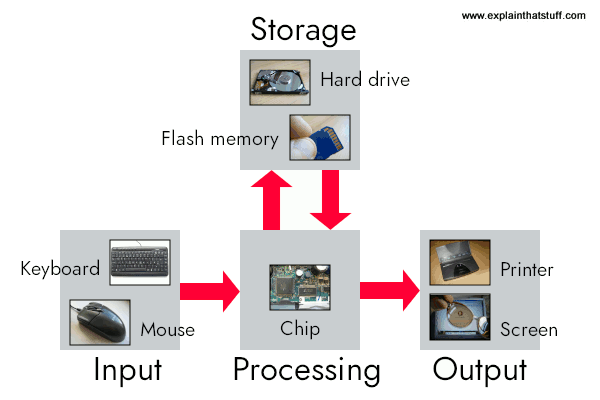
Artwork: A computer works by combining input, storage, processing, and output. All the main parts of a computer system are involved in one of these four processes.
- Input: Your keyboard and mouse, for example, are just input units—ways of getting information into your computer that it can process. If you use a microphone and voice recognition software, that's another form of input.
- Memory/storage: Your computer probably stores all your documents and files on a hard-drive: a huge magnetic memory. But smaller, computer-based devices like digital cameras and cellphones use other kinds of storage such as flash memory cards.
- Processing: Your computer's processor (sometimes known as the central processing unit) is a microchip buried deep inside. It works amazingly hard and gets incredibly hot in the process. That's why your computer has a little fan blowing away—to stop its brain from overheating!
- Output: Your computer probably has an LCD screen capable of displaying high-resolution (very detailed) graphics, and probably also stereo loudspeakers. You may have an inkjet printer on your desk too to make a more permanent form of output.
What is a computer program?
As you can read in our long article on computer history, the first computers were gigantic calculating machines and all they ever really did was "crunch numbers": solve lengthy, difficult, or tedious mathematical problems. Today, computers work on a much wider variety of problems—but they are all still, essentially, calculations. Everything a computer does, from helping you to edit a photograph you've taken with a digital camera to displaying a web page, involves manipulating numbers in one way or another.
Photo: Calculators and computers are very similar, because both work by processing numbers. However, a calculator simply figures out the results of calculations; and that's all it ever does. A computer stores complex sets of instructions called programs and uses them to do much more interesting things.
Suppose you're looking at a digital photo you just taken in a paint or photo-editing program and you decide you want a mirror image of it (in other words, flip it from left to right). You probably know that the photo is made up of millions of individual pixels (colored squares) arranged in a grid pattern. The computer stores each pixel as a number, so taking a digital photo is really like an instant, orderly exercise in painting by numbers! To flip a digital photo, the computer simply reverses the sequence of numbers so they run from right to left instead of left to right. Or suppose you want to make the photograph brighter. All you have to do is slide the little "brightness" icon. The computer then works through all the pixels, increasing the brightness value for each one by, say, 10 percent to make the entire image brighter. So, once again, the problem boils down to numbers and calculations.
What makes a computer different from a calculator is that it can work all by itself. You just give it your instructions (called a program) and off it goes, performing a long and complex series of operations all by itself. Back in the 1970s and 1980s, if you wanted a home computer to do almost anything at all, you had to write your own little program to do it. For example, before you could write a letter on a computer, you had to write a program that would read the letters you typed on the keyboard, store them in the memory, and display them on the screen. Writing the program usually took more time than doing whatever it was that you had originally wanted to do (writing the letter). Pretty soon, people started selling programs like word processors to save you the need to write programs yourself.
Today, most computer users rely on prewritten programs like Microsoft Word and Excel or download apps for their tablets and smartphones without caring much how they got there. Hardly anyone writes programs any more, which is a shame, because it's great fun and a really useful skill. Most people see their computers as tools that help them do jobs, rather than complex electronic machines they have to pre-program. Some would say that's just as well, because most of us have better things to do than computer programming. Then again, if we all rely on computer programs and apps, someone has to write them, and those skills need to survive. Thankfully, there's been a recent resurgence of interest in computer programming. "Coding" (an informal name for programming, since programs are sometimes referred to as "code") is being taught in schools again with the help of easy-to-use programming languages like Scratch. There's a growing hobbyist movement, linked to build-it yourself gadgets like the Raspberry Pi and Arduino. And Code Clubs, where volunteers teach kids programming, are springing up all over the world.
What's the difference between hardware and software?
The beauty of a computer is that it can run a word-processing program one minute—and then a photo-editing program five seconds later. In other words, although we don't really think of it this way, the computer can be reprogrammed as many times as you like. This is why programs are also called software. They're "soft" in the sense that they are not fixed: they can be changed easily. By contrast, a computer's hardware—the bits and pieces from which it is made (and the peripherals, like the mouse and printer, you plug into it)—is pretty much fixed when you buy it off the shelf. The hardware is what makes your computer powerful; the ability to run different software is what makes it flexible. That computers can do so many different jobs is what makes them so useful—and that's why millions of us can no longer live without them!What is an operating system?
Suppose you're back in the late 1970s, before off-the-shelf computer programs have really been invented. You want to program your computer to work as a word processor so you can bash out your first novel—which is relatively easy but will take you a few days of work. A few weeks later, you tire of writing things and decide to reprogram your machine so it'll play chess. Later still, you decide to program it to store your photo collection. Every one of these programs does different things, but they also do quite a lot of similar things too. For example, they all need to be able to read the keys pressed down on the keyboard, store things in memory and retrieve them, and display characters (or pictures) on the screen. If you were writing lots of different programs, you'd find yourself writing the same bits of programming to do these same basic operations every time. That's a bit of a programming chore, so why not simply collect together all the bits of program that do these basic functions and reuse them each time?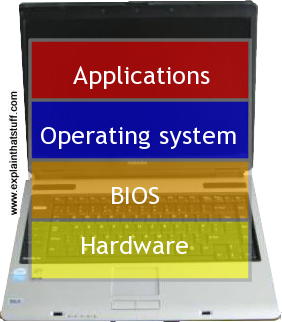
Photo: Typical computer architecture: You can think of a computer as a series of layers, with the hardware at the bottom, the BIOS connecting the hardware to the operating system, and the applications you actually use (such as word processors, Web browsers, and so on) running on top of that. Each of these layers is relatively independent so, for example, the same Windows operating system might run on laptops running a different BIOS, while a computer running Windows (or another operating system) can run any number of different applications.
That's the basic idea behind an operating system: it's the core software in a computer that (essentially) controls the basic chores of input, output, storage, and processing. You can think of an operating system as the "foundations" of the software in a computer that other programs (called applications) are built on top of. So a word processor and a chess game are two different applications that both rely on the operating system to carry out their basic input, output, and so on. The operating system relies on an even more fundamental piece of programming called the BIOS (Basic Input Output System), which is the link between the operating system software and the hardware. Unlike the operating system, which is the same from one computer to another, the BIOS does vary from machine to machine according to the precise hardware configuration and is usually written by the hardware manufacturer. The BIOS is not, strictly speaking, software: it's a program semi-permanently stored into one of the computer's main chips, so it's known as firmware (it is usually designed so it can be updated occasionally, however).
Operating systems have another big benefit. Back in the 1970s (and early 1980s), virtually all computers were maddeningly different. They all ran in their own, idiosyncratic ways with fairly unique hardware (different processor chips, memory addresses, screen sizes and all the rest). Programs written for one machine (such as an Apple) usually wouldn't run on any other machine (such as an IBM) without quite extensive conversion. That was a big problem for programmers because it meant they had to rewrite all their programs each time they wanted to run them on different machines. How did operating systems help? If you have a standard operating system and you tweak it so it will work on any machine, all you have to do is write applications that work on the operating system. Then any application will work on any machine. The operating system that definitively made this breakthrough was, of course, Microsoft Windows, spawned by Bill Gates. (It's important to note that there were earlier operating systems too. You can read more of that story in our article on the history of computers.)
Computers for everyone?

Photo: The original OLPC computer, courtesy of One Laptop Per Child, licensed under a Creative Commons License.
What should we do about the digital divide—the gap between people who use computers and those who don't? Most people have chosen just to ignore it, but US computer pioneer Nicholas Negroponte and his team have taken a much more practical approach. Over the last few years, they've worked to create a trimmed-down, low-cost laptop suitable for people who live in developing countries where electricity and telephone access are harder to find. Their project is known as OLPC: One Laptop Per Child.
What's different about the OLPC?
In essence, an OLPC computer is no different from any other laptop: it's a machine with input, output, memory storage, and a processor—the key components of any computer. But in OLPC, these parts have been designed especially for developing countries.Here are some of the key features:
- Low cost: OLPC was originally designed to cost just $100. Although it failed to meet that target, it is still cheaper than most traditional laptops.
- Inexpensive LCD screen: The hi-tech screen is designed to work outdoors in bright sunlight, but costs only $35 to make—a fraction of the cost of a normal LCD flat panel display.
- Trimmed down operating system: The operating system is like the conductor of an orchestra: the part of a computer that makes all the other parts (from the processor chip to the buttons on the mouse) work in harmony. Originally, OLPC used only Linux (an efficient and low-cost operating system developed by thousands of volunteers), but it began offering Microsoft Windows versions as an alternative in 2008.
- Wireless broadband: In some parts of Africa, fewer than one person in a hundred has access to a wired, landline telephone, so dialup Internet access via telephone would be no use for OLPC users. Each machine's wireless chip will allow it to create an ad-hoc network with other machines nearby—so OLPC users will be able to talk to one another and exchange information effortlessly.
- Flash memory: Instead of an expensive and relatively unreliable hard drive, OLPC uses a huge lump of flash memory—like the memory used in USB flash memory sticks and digital camera memory cards.
- Own power: Home electricity supplies are scarce in many developing countries, so OLPC has a hand crank and built-in generator. One minute of cranking generates up to 10 minutes of power.
Is OLPC a good idea?
Anything that closes the digital divide, helping poorer children gain access to education and opportunity, must be a good thing. However, some critics have questioned whether projects like this are really meeting the most immediate needs of people in developing countries. According to the World Health Organization, around 1.1 billion people (18 percent of the world's population) have no access to safe drinking water, while 2.7 billion (a staggering 42 percent of the world's population) lack basic sanitation. During the 1990s, around 2 billion people were affected by major natural disasters such as floods and droughts. Every single day, 5000 children die because of dirty water—that's more people dying each day than were killed in the 9/11 terrorist attacks.With basic problems on this scale, it could be argued that providing access to computers and the Internet is not a high priority for most of the world's poorer people. Then again, education is one of the most important weapons in the fight against poverty. Perhaps computers could provide young people with the knowledge they need to help themselves, their families, and communities escape a life sentence of hardship?
Y . I/O II . Integrated circuits

Have you ever heard of a 1940s computer called the ENIAC? It was about the same length and weight as three to four double-decker buses and contained 18,000 buzzing electronic switches known as vacuum tubes. Despite its gargantuan size, it was thousands of times less powerful than a modern laptop—a machine about 100 times smaller.
If the history of computing sounds like a magic trick—squeezing more and more power into less and less space—it is! What made it possible was the invention of the integrated circuit (IC) in 1958. It's a neat way of cramming hundreds, thousands, millions, or even billions of electronic components onto tiny chips of silicon no bigger than a fingernail. Let's take a closer look at ICs and how they work!
Photo: An integrated circuit from the outside. This is what an IC looks like when it's conveniently packaged inside a flash memory chip. Inside the black protective case, there's a tiny integrated circuit, with millions of transistors capable of storing millions of binary digits of information. You can see what the circuit itself looks like in the photograph below.
What is an integrated circuit?

Photo: An integrated circuit from the inside. If you could lift the cover off a typical microchip like the one in the top photo (and you can't very easily—believe me, I've tried!), this is what you'd find inside. The integrated circuit is the tiny square in the center. Connections run out from it to the terminals (metal pins or legs) around the edge. When you hook up something to one of these terminals, you're actually connecting into the circuit itself. You can just about see the pattern of electronic components on the surface of the chip itself. Photo by courtesy of NASA Glenn Research Center (NASA-GRC).
Open up a television or a radio and you'll see it's built around a printed circuit board (PCB): a bit like an electric street-map with small electronic components (such as resistors and capacitors) in place of the buildings and printed copper connections linking them together like miniature metal streets. Circuit boards are fine in small appliances like this, but if you try to use the same technique to build a complex electronic machine, such as a computer, you quickly hit a snag. Even the simplest computer needs eight electronic switches to store a single byte (character) of information. So if you want to build a computer with just enough memory to store this paragraph, you're looking at about 750 characters times 8 or about 6000 switches—for a single paragraph! If you plump for switches like they had in the ENIAC—vacuum tubes about the size of an adult thumb—you soon end up with a whopping great big, power-hungry machine that needs its own mini electricity plant to keep it running.
When three American physicists invented transistors in 1947, things improved somewhat. Transistors were a fraction the size of vacuum tubes and relays (the electromagnetic switches that had started to replace vacuum tubes in the mid-1940s), used much less power, and were far more reliable. But there was still the problem of linking all those transistors together in complex circuits. Even after transistors were invented, computers were still a tangled mass of wires.
Photo: A typical modern transistor mounted on a printed circuit board. Imagine having to wire hundreds of millions of these things onto a PCB!
Integrated circuits changed all that. The basic idea was to take a complete circuit, with all its many components and the connections between them, and recreate the whole thing in microscopically tiny form on the surface of a piece of silicon. It was an amazingly clever idea and it's made possible all kinds of "microelectronic" gadgets we now take for granted, from digital watches and pocket calculators to Moon-landing rockets and missiles with built-in satellite navigation.
Integrated circuits revolutionized electronics and computing during the 1960s and 1970s. First, engineers were putting dozens of components on a chip in what was called Small-Scale Integration (SSI). Medium-Scale Integration (MSI) soon followed, with hundreds of components in an area the same size. Predictably, around 1970, Large-Scale Integration (LSI) brought thousands of components, Very-Large-Scale Integration (VLSI) gave us tens of thousands, and Ultra Large Scale (ULSI) millions—and all on chips no bigger than they'd been before. In 1965, Gordon Moore of the Intel Company, a leading chip maker, noticed that the number of components on a chip was doubling roughly every one to two years. Moore's Law, as this is known, has continued to hold ever since. Interviewed by The New York Times 50 years later, in 2015, Moore revealed his astonishment that the law has continued to hold: "The original prediction was to look at 10 years, which I thought was a stretch. This was going from about 60 elements on an integrated circuit to 60,000—a thousandfold extrapolation over 10 years. I thought that was pretty wild. The fact that something similar is going on for 50 years is truly amazing."
How are integrated circuits made?
How do we make something like a memory or processor chip for a computer? It all starts with a raw chemical element such as silicon, which is chemically treated or doped to make it have different electrical properties...Doping semiconductors

Photo: A traditional printed circuit board (PCB) like this has tracks linking together the terminals (metal connecting legs) from different electronic components. Think of the tracks as "streets" making paths between "buildings" where useful things are done (the components themselves). There's a miniaturized version of a circuit board inside an integrated circuit: the tracks are created in microscopic form on the surface of a silicon wafer. This is the reverse side of the flash memory chip in our top photo.
If you've read our articles on diodes and transistors, you'll be familiar with the idea of semiconductors. Traditionally, people thought of materials fitting into two neat categories: those that allow electricity to flow through them quite readily (conductors) and those that don't (insulators). Metals make up most of the conductors, while nonmetals such as plastics, wood, and glass are the insulators. In fact, things are far more complex than this—especially when it comes to certain elements in the middle of the periodic table (in groups 14 and 15), notably silicon and germanium. Normally insulators, these elements can be made to behave more like conductors if we add small quantities of impurities to them in a process known as doping. If you add antimony to silicon, you give it slightly more electrons than it would normally have—and the power to conduct electricity. Silicon "doped" that way is called n-type. Add boron instead of antimony and you remove some of silicon's electrons, leaving behind "holes" that work as "negative electrons," carrying a positive electric current in the opposite way. That kind of silicon is called p-type. Putting areas of n-type and p-type silicon side by side creates junctions where electrons behave in very interesting ways—and that's how we create electronic, semiconductor-based components like diodes, transistors, and memories.
Inside a chip plant

Photo: A silicon wafer. Photo by courtesy of NASA Glenn Research Center (NASA-GRC).
The process of making an integrated circuit starts off with a big single crystal of silicon, shaped like a long solid pipe, which is "salami sliced" into thin discs (about the dimensions of a compact disc) called wafers. The wafers are marked out into many identical square or rectangular areas, each of which will make up a single silicon chip (sometimes called a microchip). Thousands, millions, or billions of components are then created on each chip by doping different areas of the surface to turn them into n-type or p-type silicon. Doping is done by a variety of different processes. In one of them, known as sputtering, ions of the doping material are fired at the silicon wafer like bullets from a gun. Another process called vapor deposition involves introducing the doping material as a gas and letting it condense so the impurity atoms create a thin film on the surface of the silicon wafer. Molecular beam epitaxy is a much more precise form of deposition.
Of course, making integrated circuits that pack hundreds, millions, or billions of components onto a fingernail-sized chip of silicon is all a bit more complex and involved than it sounds. Imagine the havoc even a speck of dirt could cause when you're working at the microscopic (or sometimes even the nanoscopic) scale. That's why semiconductors are made in spotless laboratory environments called clean rooms, where the air is meticulously filtered and workers have to pass in and out through airlocks wearing all kinds of protective clothing.
How you make a microchip - a quick summary
Although making a chip is very intricate and complex, there are really only six separate steps (some of them are repeated more than once). Greatly simplified, here's how the process works: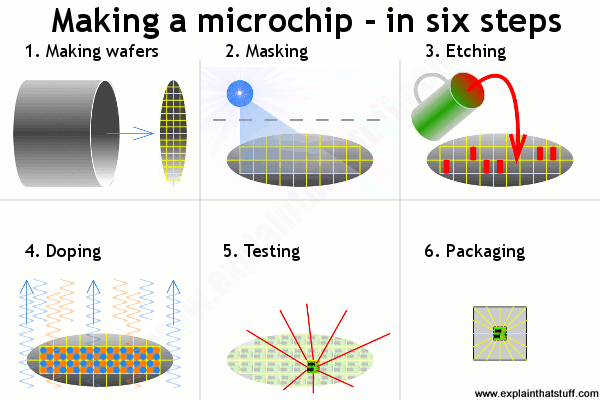
- Making wafers: We grow pure silicon crystals into long cylinders and slice them (like salami) into thin wafers, each of which will ultimately be cut up into many chips.
- Masking: We heat the wafers to coat them in silicon dioxide and use ultraviolet light (blue) to add a hard, protective layer called photoresist.
- Etching: We use a chemical to remove some of the photoresist, making a kind of template pattern showing where we want areas of n-type and p-type silicon.
- Doping: We heat the etched wafers with gases containing impurities to make the areas of n-type and p-type silicon. More masking and etching may follow.
- Testing: Long metal connection leads run from a computer-controlled testing machine to the terminals on each chip. Any chips that don't work are marked and rejected.
- Packaging: All the chips that work OK are cut out of the wafer and packaged into protective lumps of plastic, ready for use in computers and other electronic equipment.
Who invented the integrated circuit?
You've probably read in books that ICs were developed jointly by Jack Kilby (1923–2005) and Robert Noyce (1927–1990), as though these two men happily collaborated on their brilliant invention! In fact, Kilby and Noyce came up with the idea independently, at more or less exactly the same time, prompting a furious battle for the rights to the invention that was anything but happy.
Photo: Computer microchips like these—and all the appliances and gadgets that use them—owe their existence to Jack Kilby and Robert Noyce. Photo by Warren Gretz courtesy of US Department of Energy/National Renewable Energy Laboratory (US DOE/NREL).
How could two people invent the same thing at exactly the same time? Easy: integrated circuits were an idea waiting to happen. By the mid-1950s, the world (and the military, in particular) had discovered the amazing potential of electronic computers and it was blindingly apparent to visionaries like Kilby and Noyce that there needed to be a better way of building and connecting transistors in large quantities. Kilby was working at Texas Instruments when he came upon the idea he called the monolithic principle: trying to build all the different parts of an electronic circuit on a silicon chip. On September 12, 1958, he hand-built the world's first, crude integrated circuit using a chip of germanium (a semiconducting element similar to silicon) and Texas Instruments applied for a patent on the idea the following year.
Meanwhile, at another company called Fairchild Semiconductor (formed by a small group of associates who had originally worked for the transistor pioneer William Shockley) the equally brilliant Robert Noyce was experimenting with miniature circuits of his own. In 1959, he used a series of photographic and chemical techniques known as the planar process (which had just been developed by a colleague, Jean Hoerni) to produce the first, practical, integrated circuit, a method that Fairchild then tried to patent.
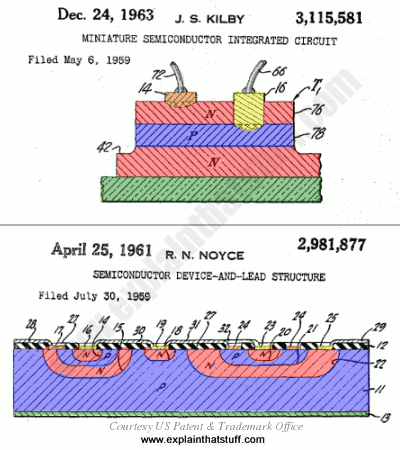
Artwork: Snap! Two great electrical engineers, Jack Kilby and Robert Noyce, came up with the same idea at almost exactly the same time in 1959. Although Kilby filed his patent first, Noyce's patent was granted earlier. Here are drawings from their original patent applications. You can see that we have essentially the same idea in both, with electronic components formed from junctions between layers of p-type (blue) and n-type (red) semiconductors. Connections to the p-type and n-type regions are shown in orange and yellow and the base layers (substrates) are shown in green. Artworks courtesy of US Patent and Trademark Office with our own added coloring to improve clarity and highlight the similarities. You can find links to the patents themselves in the references down below.
There was considerable overlap between the two men's work and Texas Instruments and Fairchild battled in the courts for much of the 1960s over who had really developed the integrated circuit. Finally, in 1969, the companies agreed to share the idea.
Kilby and Noyce are now rightly regarded as joint-inventors of arguably the most important and far-reaching technology developed in the 20th century. Both men were inducted into the National Inventors Hall of Fame (Kilby in 1982, Noyce the following year) and Kilby's breakthrough was also recognized with the award of a half-share in the Nobel Prize in Physics in 2000 (as Kilby very generously noted in his acceptance speech, Noyce would surely have shared in the prize too had he not died of a heart attack a decade earlier).
While Kilby is remembered as a brilliant scientist, Noyce's legacy has an added dimension. In 1968, he co-founded the Intel Electronics company with Gordon Moore (1929–), which went on to develop the microprocessor (single-chip computer) in 1974. With IBM, Microsoft, Apple, and other pioneering companies, Intel is credited with helping to bring affordable personal computers to our homes and workplaces. Thanks to Noyce and Kilby, and brilliant engineers who subsequently built on their work, there are now something like two billion computers in use throughout the world, many of them incorporated into cellphones, portable satellite navigation devices, and other electronic gadgets.
Y . I/O III Molecular beam epitaxy

Growing crystals is easy. Fill a plastic bottle almost to the top with cold water and place it in a freezer for a couple of hours. Take it out again at just the right time and the water will still be a liquid but, if you tilt the bottle very gently, it will snap into an amazing snow forest of ice crystals right before your eyes! Growing single crystals for scientific or industrial use in such things as integrated circuits is somewhat harder because you need to combine atoms of different chemical elements much more precisely. At the opposite end of the spectrum from growing random ice crystals in your freezer, one of the most exacting methods of making a crystal is a technique called molecular beam epitaxy (MBE). It sounds horribly complex, but it's fairly easy to understand. Let's take a closer look!
Photo: Molecular beam epitaxy (MBE) being used to make photovoltaic solar cells: You can see the beams around the edge that fire molecules onto the substrate in the center. Photo by Jim Yost courtesy of US DOE/NREL (U.S. Department of Energy/National Renewable Energy Laboratory).
What is molecular beam epitaxy?

Photo: Molecular beam epitaxy (MBE) in action. MBE takes place in ultra-high vacuum (UHV) chambers like this, at temperatures of around 500°C (932°F), to ensure a totally clean, dust-free environment; the slightest contamination could ruin the crystal. Photo by Jim Yost courtesy of US DOE/NREL (U.S. Department of Energy/National Renewable Energy Laboratory).
To make an interesting new crystal using MBE, you start off with a base material called a substrate, which could be a familiar semiconductor material such as silicon, germanium, or gallium arsenide. First, you heat the substrate, typically to some hundreds of degrees (for example, 500–600°C or about 900–1100°F in the case of gallium arsenide). Then you fire relatively precise beams of atoms or molecules (heated up so they're in gas form) at the substrate from "guns" called effusion cells. You need one "gun" for each different beam, shooting a different kind of molecule at the substrate, depending on the nature of the crystal you're trying to create. The molecules land on the surface of the substrate, condense, and build up very slowly and systematically in ultra-thin layers, so the complex, single crystal you're after grows one atomic layer at a time. That's why MBE is an example of what's called thin-film deposition. Since it involves building up materials by manipulating atoms and molecules, it's also a perfect example of what we mean by nanotechnology.
One reason that MBE is such a precise way of making a crystal is that it happens in highly controlled conditions: extreme cleanliness and what's called an ultra-high vacuum (UHV), so no dirt particles or unwanted gas molecules can interfere with or contaminate the crystal growth. "Extreme cleanliness" means even cleaner than the conditions used in normal semiconductor manufacture; an "ultra-high vacuum" means the pressure is so low that it's at the limit of what's easily measurable.
That's pretty much MBE in a nutshell. If you want a really simply analogy, it's a little bit like the way an inkjet printer makes layers of colored print on a page by firing jets of ink from hot guns. In an inkjet printer, you have four separate guns firing different colored inks (one for cyan ink, one for magenta, one for yellow, and one for black), which slowly build up a complex colored image on the paper. In MBE, separate beams fire different molecules and they build up on the surface of the substrate, albeit more slowly than in inkjet printing—MBE can take hours! Epitaxially simply means "arranged on top of," so all molecular beam epitaxy really means is using beams of molecules to build up layers on top of a substrate.
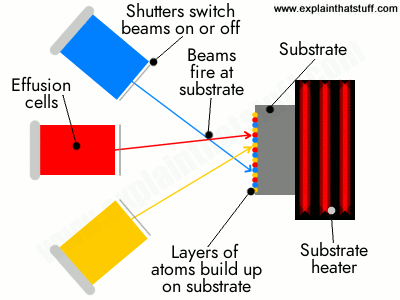
Typical uses
You might want to create a semiconductor laser for a CD player, or an advanced computer chip, or a low-temperature superconductor. Or maybe you want to build a solar-cell by depositing a thin film of a photovoltaic material (something that creates electricity when light falls on it) onto a substrate. In short, if you're designing a really precise thin-film device for computing, optics, or photonics (using light beams to carry and process signals in a similar way to electronics), MBE is one of the techniques you'll probably consider using. Apart from industrial processes, it's also used in all kinds of advanced nanotechnology research.Advantages and disadvantages
Why use MBE rather than some other method making a crystal? It's particularly good for making high-quality (low-defect, highly uniform) semiconductor crystals from compounds (based on elements in groups III(a)–V(a) of the periodic table), or from a number of different elements, instead of from a single element. It also allows extremely thin films to be fabricated in a very precise, carefully controlled way. Unfortunately, it does have some drawbacks too. It's a slow and laborious method (crystal growth rate is typically a few microns per hour), which means it's more suited for scientific research laboratories than high-volume production, and the equipment involved is complex and very expensive (partly because of the difficulty of achieving such clean, high-vacuum conditions).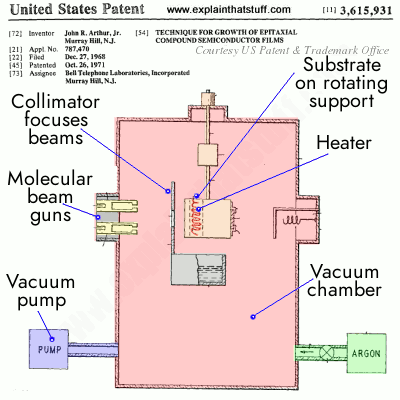
Who invented molecular beam epitaxy?
The basic MBE technique was developed around 1968 at Bell Laboratories by two American physicists, Chinese-born Alfred Y. Cho and John R. Arthur, Jr. Important contributions were also made by other scientists, such as Japanese-born physicist Leo Esaki (who won the 1973 Nobel Prize in Physics for his work on semiconductor electronics) and Ray Tsu, working at IBM. Since then, many other researchers have developed and refined the process. Alfred Cho was awarded the inaugural Nanotechnology International Prize, RUSNANOPRIZE-2009, for his work in developing MBE.Photo: A drawing taken from John R. Arthur, Jr.'s original molecular beam epitaxy patent, filed in 1968 and granted in 1971. Artwork courtesy of US Patent and Trademark office.
Y . I/O IIII The Internet
When you chat to somebody on the Net or send them an e-mail, do you ever stop to think how many different computers you are using in the process? There's the computer on your own desk, of course, and another one at the other end where the other person is sitting, ready to communicate with you. But in between your two machines, making communication between them possible, there are probably about a dozen other computers bridging the gap. Collectively, all the world's linked-up computers are called the Internet. How do they talk to one another? Let's take a closer look!
Photo: What most of us think of as the Internet—Google, eBay, and all the rest of it—is actually the World Wide Web. The Internet is the underlying telecommunication network that makes the Web possible. If you use broadband, your computer is probably connected to the Internet all the time it's on.
What is the Internet?
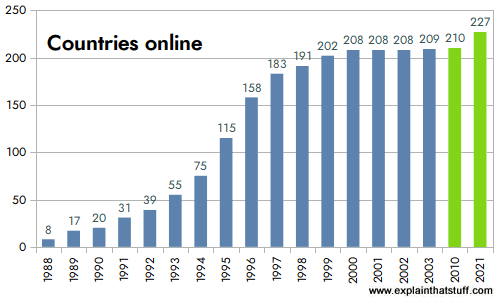
Global communication is easy now thanks to an intricately linked worldwide computer network that we call the Internet. In less than 20 years, the Internet has expanded to link up around 210 different nations. Even some of the world's poorest developing nations are now connected.
Lots of people use the word "Internet" to mean going online. Actually, the "Internet" is nothing more than the basic computer network. Think of it like the telephone network or the network of highways that criss-cross the world. Telephones and highways are networks, just like the Internet. The things you say on the telephone and the traffic that travels down roads run on "top" of the basic network. In much the same way, things like the World Wide Web (the information pages we can browse online), instant messaging chat programs, MP3 music downloading, and file sharing are all things that run on top of the basic computer network that we call the Internet.
The Internet is a collection of standalone computers (and computer networks in companies, schools, and colleges) all loosely linked together, mostly using the telephone network. The connections between the computers are a mixture of old-fashioned copper cables, fiber-optic cables (which send messages in pulses of light), wireless radio connections (which transmit information by radio. waves), and satellite links.
Photo: Countries online: Between 1988 and 2003, virtually every country in the world went online. Although most countries are now "wired," that doesn't mean everyone is online in all those countries, as you can see from the next chart, below. Source: Redrawn by Explainthatstuff.com from ITU World Telecommunication Development Report: Access Indicators for the Information Society: Summary, 2003. I've not updated this figure because the message is pretty clear: virtually all countries now have at least some Internet access.
What does the Internet do?
The Internet has one very simple job: to move computerized information (known as data) from one place to another. That's it! The machines that make up the Internet treat all the information they handle in exactly the same way. In this respect, the Internet works a bit like the postal service. Letters are simply passed from one place to another, no matter who they are from or what messages they contain. The job of the mail service is to move letters from place to place, not to worry about why people are writing letters in the first place; the same applies to the Internet.
Just like the mail service, the Internet's simplicity means it can handle many different kinds of information helping people to do many different jobs. It's not specialized to handle emails, Web pages, chat messages, or anything else: all information is handled equally and passed on in exactly the same way. Because the Internet is so simply designed, people can easily use it to run new "applications"—new things that run on top of the basic computer network. That's why, when two European inventors developed Skype, a way of making telephone calls over the Net, they just had to write a program that could turn speech into Internet data and back again. No-one had to rebuild the entire Internet to make Skype possible.
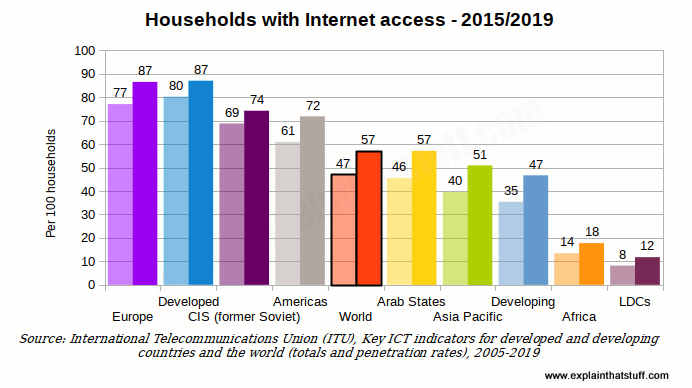
Photo: Internet use around the world: This chart compares the estimated percentage of households with Internet access for different world regions and economic groupings. Although there have been dramatic improvements in all regions, there are still great disparities between the "richer" nations and the "poorer" ones. The world average, shown by the black-outlined orange center bar, is still only 46.4 out of 100 (less than half). Not surprisingly, richer nations are to the left of the average and poorer ones to the right. Source: Redrawn from Chart 1.5 of the Executive Summary of Measuring the Information Society 2015, International Telecommunication Union (ITU).
How does Internet data move?
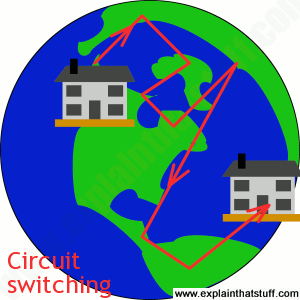
Circuit switching
Much of the Internet runs on the ordinary public telephone network—but there's a big difference between how a telephone call works and how the Internet carries data. If you ring a friend, your telephone opens a direct connection (or circuit) between your home and theirs. If you had a big map of the worldwide telephone system (and it would be a really big map!), you could theoretically mark a direct line, running along lots of miles of cable, all the way from your phone to the phone in your friend's house. For as long as you're on the phone, that circuit stays permanently open between your two phones. This way of linking phones together is called circuit switching. In the old days, when you made a call, someone sitting at a "switchboard" (literally, a board made of wood with wires and sockets all over it) pulled wires in and out to make a temporary circuits that connected one home to another. Now the circuit switching is done automatically by an electronic telephone exchange.If you think about it, circuit switching is a really inefficient way to use a network. All the time you're connected to your friend's house, no-one else can get through to either of you by phone. (Imagine being on your computer, typing an email for an hour or more—and no-one being able to email you while you were doing so.) Suppose you talk very slowly on the phone, leave long gaps of silence, or go off to make a cup of coffee. Even though you're not actually sending information down the line, the circuit is still connected—and still blocking other people from using it.
Packet switching
The Internet could, theoretically, work by circuit switching—and some parts of it still do. If you have a traditional "dialup" connection to the Net (where your computer dials a telephone number to reach your Internet service provider in what's effectively an ordinary phone call), you're using circuit switching to go online. You'll know how maddeningly inefficient this can be. No-one can phone you while you're online; you'll be billed for every second you stay on the Net; and your Net connection will work relatively slowly.Most data moves over the Internet in a completely different way called packet switching. Suppose you send an email to someone in China. Instead of opening up a long and convoluted circuit between your home and China and sending your email down it all in one go, the email is broken up into tiny pieces called packets. Each one is tagged with its ultimate destination and allowed to travel separately. In theory, all the packets could travel by totally different routes. When they reach their ultimate destination, they are reassembled to make an email again.
Packet switching is much more efficient than circuit switching. You don't have to have a permanent connection between the two places that are communicating, for a start, so you're not blocking an entire chunk of the network each time you send a message. Many people can use the network at the same time and since the packets can flow by many different routes, depending on which ones are quietest or busiest, the whole network is used more evenly—which makes for quicker and more efficient communication all round.
How packet switching works
What is circuit switching?
Suppose you want to move home from the United States to Africa and you decide to take your whole house with you—not just the contents, but the building too! Imagine the nightmare of trying to haul a house from one side of the world to the other. You'd need to plan a route very carefully in advance. You'd need roads to be closed so your house could squeeze down them on the back of a gigantic truck. You'd also need to book a special ship to cross the ocean. The whole thing would be slow and difficult and the slightest problem en-route could slow you down for days. You'd also be slowing down all the other people trying to travel at the same time. Circuit switching is a bit like this. It's how a phone call works.Picture: Circuit switching is like moving your house slowly, all in one go, along a fixed route between two places.
What is packet switching?
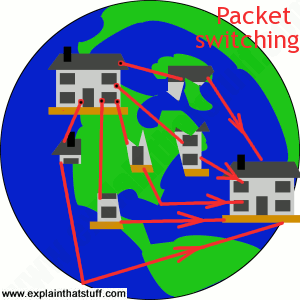
Is there a better way? Well, what if you dismantled your home instead, numbered all the bricks, put each one in an envelope, and mailed them separately to Africa? All those bricks could travel by separate routes. Some might go by ship; some might go by air. Some might travel quickly; others slowly. But you don't actually care. All that matters to you is that the bricks arrive at the other end, one way or another. Then you can simply put them back together again to recreate your house. Mailing the bricks wouldn't stop other people mailing things and wouldn't clog up the roads, seas, or airways. Because the bricks could be traveling "in parallel," over many separate routes at the same time, they'd probably arrive much quicker. This is how packet switching works. When you send an email or browse the Web, the data you send is split up into lots of packets that travel separately over the Internet.
Picture: Packet switching is like breaking your house into lots of bits and mailing them in separate packets. Because the pieces travel separately, in parallel, they usually go more quickly and make better overall use of the network.
How computers do different jobs on the Internet

Photo: The Internet is really nothing more than a load of wires! Much of the Internet's traffic moves along ethernet networking cables like this one.
There are hundreds of millions of computers on the Net, but they don't all do exactly the same thing. Some of them are like electronic filing cabinets that simply store information and pass it on when requested. These machines are called servers. Machines that hold ordinary documents are called file servers; ones that hold people's mail are called mail servers; and the ones that hold Web pages are Web servers. There are tens of millions of servers on the Internet.
A computer that gets information from a server is called a client. When your computer connects over the Internet to a mail server at your ISP (Internet Service Provider) so you can read your messages, your computer is the client and the ISP computer is the server. There are far more clients on the Internet than servers—probably getting on for a billion by now!
When two computers on the Internet swap information back and forth on a more-or-less equal basis, they are known as peers. If you use an instant messaging program to chat to a friend, and you start swapping party photos back and forth, you're taking part in what's called peer-to-peer (P2P) communication. In P2P, the machines involved sometimes act as clients and sometimes as servers. For example, if you send a photo to your friend, your computer is the server (supplying the photo) and the friend's computer is the client (accessing the photo). If your friend sends you a photo in return, the two computers swap over roles.
Apart from clients and servers, the Internet is also made up of intermediate computers called routers, whose job is really just to make connections between different systems. If you have several computers at home or school, you probably have a single router that connects them all to the Internet. The router is like the mailbox on the end of your street: it's your single point of entry to the worldwide network.
How the Net really works: TCP/IP and DNS
The real Internet doesn't involving moving home with the help of envelopes—and the information that flows back and forth can't be controlled by people like you or me. That's probably just as well given how much data flows over the Net each day—roughly 3 billion emails and a huge amount of traffic downloaded from the world's 250 million websites by its 2 billion users. If everything is sent by packet-sharing, and no-one really controls it, how does that vast mass of data ever reach its destination without getting lost?The answer is called TCP/IP, which stands for Transmission Control Protocol/Internet Protocol. It's the Internet's fundamental "control system" and it's really two systems in one. In the computer world, a "protocol" is simply a standard way of doing things—a tried and trusted method that everybody follows to ensure things get done properly. So what do TCP and IP actually do?
Internet Protocol (IP) is simply the Internet's addressing system. All the machines on the Internet—yours, mine, and everyone else's—are identified by an Internet Protocol (IP) address that takes the form of a series of digits separated by dots or colons. If all the machines have numeric addresses, every machine knows exactly how (and where) to contact every other machine. When it comes to websites, we usually refer to them by easy-to-remember names (like www.explainthatstuff.com) rather than their actual IP addresses—and there's a relatively simple system called DNS (Domain Name System) that enables a computer to look up the IP address for any given website. In the original version of IP, known as IPv4, addresses consisted of four pairs of digits, such as 12.34.56.78 or 123.255.212.55, but the rapid growth in Internet use meant that all possible addresses were used up by January 2011. That has prompted the introduction of a new IP system with more addresses, which is known as IPv6, where each address is much longer and looks something like this: 123a:b716:7291:0da2:912c:0321:0ffe:1da2.
The other part of the control system, Transmission Control Protocol (TCP), sorts out how packets of data move back and forth between one computer (in other words, one IP address) and another. It's TCP that figures out how to get the data from the source to the destination, arranging for it to be broken into packets, transmitted, resent if they get lost, and reassembled into the correct order at the other end.
A brief history of the Internet
- 1844: Samuel Morse transmits the first electric telegraph message, eventually making it possible for people to send messages around the world in a matter of minutes.
- 1876: Alexander Graham Bell (and various rivals) develop the telephone.
- 1940: George Stibitz accesses a computer in New York using a teletype (remote terminal) in New Hampshire, connected over a telephone line.
- 1945: Vannevar Bush, a US government scientist, publishes a paper called As We May Think, anticipating the development of the World Wide Web by half a century.
- 1958: Modern modems are developed at Bell Labs. Within a few years, AT&T and Bell begin selling them commercially for use on the public telephone system.
- 1964: Paul Baran, a researcher at RAND, invents the basic concept of computers communicating by sending "message blocks" (small packets of data); Welsh physicist Donald Davies has a very similar idea and coins the name "packet switching," which sticks.
- 1963: J.C.R. Licklider envisages a network that can link people and user-friendly computers together.
- 1964: Larry Roberts, a US computer scientist, experiments with connecting computers over long distances.
- 1960s: Ted Nelson invents hypertext, a way of linking together separate documents that eventually becomes a key part of the World Wide Web.
- 1966: Inspired by the work of Licklider, Bob Taylor of the US government's Advanced Research Projects Agency (ARPA) hires Larry Roberts to begin developing a national computer network.
- 1969: The ARPANET computer network is launched, initially linking together four scientific institutions in California and Utah.
- 1971: Ray Tomlinson sends the first email, introducing the @ sign as a way of separating a user's name from the name of the computer where their mail is stored.
- 1973: Bob Metcalfe invents Ethernet, a convenient way of linking computers and peripherals (things like printers) on a local network.
- 1974: Vinton Cerf and Bob Kahn write an influential paper describing how computers linked on a network they called an "internet" could send messages via packet switching, using a protocol (set of formal rules) called TCP (Transmission Control Protocol).
- 1978: TCP is improved by adding the concept of computer addresses (Internet Protocol or IP addresses) to which Internet traffic can be routed. This lays the foundation of TCP/IP, the basis of the modern Internet.
- 1978: Ward Christensen sets up Computerized Bulletin Board System (a forerunner of topic-based Internet forums, groups, and chat rooms) so computer hobbyists can swap information.
- 1983: TCP/IP is officially adopted as the standard way in which Internet computers will communicate.
- 1982–1984: DNS (Domain Name System) is developed, allowing people to refer to unfriendly IP addresses (12.34.56.78) with friendly and memorable names (like google.com).
- 1986: The US National Science Foundation (NSF) creates its own network, NSFnet, allowing universities to piggyback onto the ARPANET's growing infrastructure.
- 1988: Finish computer scientist Jarkko Oikarinen invents IRC (Internet Relay Chat), which allows people to create "rooms" where they can talk about topics in real-time with like-minded online friends.
- 1989: The Peapod grocery store pioneers online grocery shopping and e-commerce.
- 1989: Tim Berners-Lee invents the World Wide Web at CERN, the European particle physics laboratory in Switzerland. It owes a considerable debt to the earlier work of Ted Nelson and Vannevar Bush.
- 1993: Marc Andreessen writes Mosaic, the first user-friendly web browser, which later evolves into Netscape and Mozilla.
- 1993: Oliver McBryan develops the World Wide Web Worm, one of the first search engines.
- 1994: People soon find they need help navigating the fast-growing World Wide Web. Brian Pinkerton writes WebCrawler, a more sophisticated search engine and Jerry Yang and David Filo launch Yahoo!, a directory of websites organized in an easy-to-use, tree-like hierarchy.
- 1995: E-commerce properly begins when Jeff Bezos founds Amazon.com and Pierre Omidyar sets up eBay.
- 1996: ICQ becomes the first user-friendly instant messaging (IM) system on the Internet.
- 1997: Jorn Barger publishes the first blog (web-log).
- 1998: Larry Page and Sergey Brin develop a search engine called BackRub that they quickly decide to rename Google.
- 2004: Harvard student Mark Zuckerberg revolutionizes social networking with Facebook, an easy-to-use website that connects people with their friends.
- 2006: Jack Dorsey and Evan Williams found Twitter, an even simpler "microblogging" site where people share their thoughts and observations in off-the-cuff, 140-character status messages.
Y . I/O IIIII Wireless Internet

Imagine for a moment if all the wireless connections in the world were instantly replaced by cables. You'd have cables stretching through the air from every radio in every home hundreds of miles back to the transmitters. You'd have wires reaching from every cellphone to every phone mast. Radio-controlled cars would disappear too, replaced by yet more cables. You couldn't step out of the door without tripping over cables. You couldn't fly a plane through the sky without getting tangled up. If you peered through your window, you'd see nothing at all but a cats-cradle of wires. That, then, is the brilliance of wireless: it does away with all those cables, leaving our lives simple, uncluttered, and free! Let's take a closer look at how it works.
Photo: A typical wireless router. This one, made by Netgear, can connect up to four different computers to the Internet at once using wired connections, because it has four ethernet sockets. But—in theory—it can connect far more machines using wireless. The white bar sticking out of the back is the wireless antenna.From wireless to radio
Wireless started out as a way of sending audio programs through the air. Pretty soon we started calling it radio and, when pictures were added to the signal, TV was born. The word "wireless" had become pretty old-fashioned by the mid-20th century, but over the last few years it's made a comeback. Now it's hip to be wireless once again thanks to the Internet. By 2007, approximately half of all the world's Internet users were expected to be using some kind of wireless access—many of them in developing countries where traditional wired forms of access, based on telephone networks, are not available. Wireless Internet, commonly used in systems called Wi-Fi®, WAP, and i-mode, has made the Internet more convenient than ever before. But what makes it different from ordinary Internet access?From radio to Wi-Fi

Artwork: The basic concept of radio: sending messages from a transmitter to a receiver at the speed of light using radio waves. In wireless Internet, the communication is two-way: there's a transmitter and receiver in both your computer (or handheld device) and the piece of equipment (such as a router) that connects you to the Internet.
Radio is an invisible game of throw-and-catch. Instead of throwing a ball from one person to another, you send information, coded as a pattern of electricity and magnetism, from a transmitter (the thrower) to a receiver (the catcher)—both of which are kinds of antennas. The transmitter is a piece of equipment that turns electrical signals (such as the sound of someone speaking, in radio, or a picture, in TV) into an oscillating electromagnetic wave that beams through the air, in a straight line, at the speed of light (300,000 km 186,000 miles per second). The receiver is a mirror-image piece of equipment that catches the waves and turns them back into electrical signals—so we can recreate the radio sounds or TV pictures. The more powerful the transmitter and receiver, the further apart they can be spaced. Radio stations use gigantic transmitters, and that's why we can pick up radio signals from thousands of miles away on the opposite side of Earth. Wireless Internet is simply a way of using radio waves to send and receive Internet data instead of radio sounds or TV pictures. But, unlike radio and TV, it is typically used to send signals only over relatively short distances with low-power transmitters.
Wi-Fi
If you have wireless Internet access at home, you probably have a little box called a router that plugs into your telephone socket. This kind of router is a bit like a sophisticated modem: it's a standalone computer whose job is to relay connections to and from the Internet. At home, you might use a router to connect several computers to the Internet at once (saving on the need for several separate modems). In other words, the router does two jobs: it creates a wireless computer network, linking all your computers together, and it also gives all your machines a shared gateway to the Internet.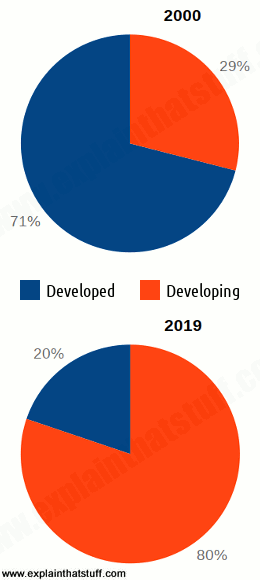
Charts: There's been huge worldwide growth in cellphones (mobile phones) and wireless Internet access over the last couple of decades, particularly in developing countries. In 2000, there were 0.7 billion cellphone subscriptions worldwide and 71 percent of them were in high-income (developed) countries. By 2015, the position had almost reversed: there were 10 times more subscriptions (roughly 7 billion) and 78 percent of them were in developing countries. The implications for Internet access are obvious: more and more people are going online from wireless mobile devices, especially in the developing world. Sources: 2012 Information and Communications for Development: Maximizing Mobile, World Bank, 2012; United Nations ITU-T, May 2014.
You can connect a router to all your different computers using ordinary network-connecting cables (for the technically minded, these are called RJ-45, Cat 5, or Ethernet cables). This creates what's called a LAN (local area network) linking the machines together. A computer network is a very orderly affair, more like an organized committee meeting, with carefully agreed rules of behavior, than a free-for-all cocktail party. The machines on the network have to be hooked up in a standard way and they communicate in a very orderly fashion. The rules that govern the network setup and the communication are based on an international standard called Ethernet (also known as IEEE 802.3).
A wireless router is simply a router that connects to your computer (or computers) using radio waves instead of cables. It contains a very low-power radio transmitter and receiver, with a maximum range of about 90 meters or 300 ft, depending on what your walls are made of and what other electrical equipment is nearby. The router can send and receive Internet data to any computer in your home that is also equipped with wireless access (so each computer on the wireless network has to have a radio transmitter and receiver in it too). Most new laptops come with wireless cards built in. For older laptops, you can usually plug a wireless adapter card into the PCMCIA or USB socket. In effect, the router becomes an informal access point for the Internet, creating an invisible "cloud" of wireless connectivity all around it, known as a hotspot. Any computer inside this cloud can connect into the network, forming a wireless LAN.

Photo: If your laptop doesn't have a built-in Wi-Fi card, you can plug in a PCMCIA adapter card like this one. They're relatively inexpensive, especially if you get them on eBay. But beware: older PCMCIA cards may not support newer forms of wireless security such as WPA.
Just as computers connected to a wired LAN use Ethernet, machines on a wireless LAN use the wireless equivalent, which is called Wi-Fi (or, more technically, IEEE 802.11). Wireless Internet is improving all the time, so better forms of Wi-Fi are constantly evolving. You may see wireless equipment marked 802.11a, 802.11b, 802.11g or 802.11n: these are all broadly compatible variants of 802.11, with 802.11n, 802.11g and 802.11a somewhat faster than 802.11b. Other more recent variants are named 802.11a with an extra letter added on the end (such as 802.11ax, 802.11ay, and so on). For example, 802.11ah is designed to work with the so-called Internet of Things, 802.11ax is for high-efficiency LANs, and 802.11az is concerned with "location services" (finding the accurate position of mobile devices).
Wi-Fi is where the expression Wi-Fi hotspot comes from. A Wi-Fi hotspot is simply a public place where you can connect your computer wirelessly to the Internet. The hotspots you find in airports, coffee bars, bookshops, and college campuses use one or more wireless routers to create wireless Net access over a large area. The University of Twente in the Netherlands has one of the world's biggest hotspots. Using 650 separate access points, it has created a seamless hotspot that covers the entire 140 hectare (350 acre) campus. Cities like Philadelphia have also announced ambitious plans to turn huge areas into hotspots. Wi-Fi hotspots are now popping up all over the world and the number is growing at an astonishing rate. By 2007, there were estimated to be around 180,000 in the United States alone; a decade later, according to Wi-Fi specialist called iPass, the worldwide total is over 214 million.
Wi-Fi Direct®: Let's cut out the middleman!
People sometimes confuse Wi-Fi and Bluetooth. Both are methods of connecting gadgets without wires, so what exactly is the difference? Broadly speaking, Bluetooth is a way of connecting two relatively nearby gadgets without the hassle of using a cable, whereas Wi-Fi is a method of linking wireless computers (and particularly mobile ones, such as laptops, tablets, and smartphones) to the Internet through a shared connection point—your router—which typically makes a wired connection to a telephone or cable line. At least, that's how things used to be.Ad-hoc networks
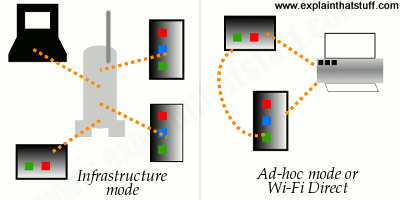
Artwork: Wi-Fi modes: Left: In infrastructure mode, all your devices communicate wirelessly with a central router that talks (usually via a wired connection) to the Internet. Here, three tablets and a laptop are talking to a router in the middle. Right: In ad-hoc mode (or with Wi-Fi Direct), devices communicate directly over a temporary network without any kind of central router. In this example, two tablets are talking to one another and to a shared printer using Wi-Fi Direct.
But nothing says Wi-Fi can't also link two laptops or smartphones directly instead of Bluetooth. Normally, Wi-Fi uses infrastructure mode, in which various gadgets and devices communicate through a router or central access point. But Wi-Fi also has what's called an ad-hoc mode, which allows gadgets to communicate directly without a router. Typically, an ad-hoc network is created as a temporary form of communication—as the name ad-hoc suggests—whereas infrastructure-mode is a more permanent thing. (The Wi-Fi network I'm using at the moment, for example, is one I set up about a decade ago using infrastructure mode and a central router as the access point.) Ad-hoc networks tend to be hard to set up, slower, and less reliable because the various devices using them all have to communicate with each other and manage the networking (unlike infrastructure networks, which are managed by the router that also handles the communications between them).
Wi-Fi Direct®
Some household gadgetry relies on a mixture of Wi-Fi and Bluetooth, which can be a bit confusing—and prompts the question "Why can't Wi-Fi do the short-range, ad-hoc bit as well?" With a bolt-on addition to the basic Wi-Fi spec known as Wi-Fi Direct®, it can. The basic idea is to use secure, encrypted Wi-Fi in a much more informal way for things like printing from a tablet or sharing photos with someone else's smartphone. Putting it a bit more technically, Wi-Fi Direct is an ad-hoc, peer-to-peer form of networking between pairs of nearby devices (sometimes multiple devices) that doesn't rely on an Internet connection. It works in a similar way to traditional Wi-Fi: each device lets others nearby know that you can connect to it (much like the way access points let you know about available Wi-Fi networks nearby). Some devices can connect both to Wi-Fi Direct and a Wi-Fi network at the same time; others can only do one or the other at a time.Wi-Fi or Bluetooth?
How does Wi-Fi Direct compare to Bluetooth? It's up to 10 times faster at transferring data (250mbps compared to 25mbps) and has a range several times longer (up to 200m or 650ft compared to a maximum of about 60m or 200ft for Bluetooth). Although both are secure, Wi-Fi Direct uses Wi-Fi's WPA-2 encryption, which uses twice as many bits (256) as Bluetooth's (128 bit) and is theoretically much more secure. In Bluetooth's favor, it allows more devices to connect at once, and while its shorter range might seem like a drawback, it means it uses less power than Wi-Fi (an extremely important consideration for mobile devices).WAP and i-mode

Photo: State-of-the-art Web browsing c.2002 on an old-fashioned cellphone! This phone is using WAP to browse breaking news on a website called Ananova. Note the crude, monochrome text-only screen. What you can't see here is the grindingly slow speed, which was about 5 times slower even than old-fashioned, dialup Internet access.

Photo: Mobile broadband with a USB modem is the fastest growing form of wireless Internet. According to the ITU-T, the worldwide market grew 12-fold between 2007 and 2015.
Wi-Fi isn't the only way to access the Internet wirelessly. If you have a reasonably new smartphone (an advanced kind of cellphone), such as an iPhone or an Android, it'll have a miniature Web browser that works in exactly the same way as the one you'd find on a laptop (albeit using a much smaller screen). In the late 1990s and early 2000s, some cellphones had very crude built-in web browsers that could haul up simplified, text-versions of web pages using a system called WAP (technically known as Wireless Application Protocol, though no-one ever called it that). WAP was very slow to take off and has now been rendered obsolete by faster cellphone networks and smartphones.
While Europe and North America were struggling with WAP, Japan's cellphone users already had a much better version of cellphone Internet called i-mode that offered fast access to web pages and emails. i-mode was always more popular than WAP and was gradually exported to a number of other countries. However, it too has now been superseded by better technologies based on faster 3G and 4G (third- and fourth-generation) cellphone networks. Effectively, mobile and desktop Internet have now converged: thanks to wireless, it's almost as easy to do things on your cellphone or tablet computer as it is on your desktop PC.
Mobile broadband
If you want to find out more about high-speed mobile, wireless broadband (broadband Internet access using a USB modem to connect to a cellphone network), please see our separate article on mobile broadband.How to secure a home wireless network
If you've set up your home wireless network, you've probably noticed something: your neighbors have all got them too! Not only that, you could quite easily connect to someone else's network if it weren't secured properly—and by the same token, they could connect to your network too. So how do you secure a network? We suggest:
- Make sure you secure your network (with what's called a pre-shared key or PSK). Use the strongest form of security your hardware supports: use WPA2 rather than WPA and use WPA in preference to WEP.
- Choose a nontrivial password (and certainly not something your neighbors could easily guess, like your surname). At the very least, if you're going to use an easy-to-remember password, put a special character ($, %, and so on) at the beginning or the end of it—you'll make it vastly more secure.
- Set up your network to use an access control list (ACL). This is a list of specific, trusted computers that will be allowed to connect to your network. For each computer on the list, you'll need to specify what's called its MAC address (or LAN MAC address). You'll find the MAC address written on the bottom of a laptop computer, round the back of a desktop, or on the bottom of a plug-in PCMCIA network card.
- If you have only one computer and it never moves from your desktop, which is reasonably close to your router, don't use wireless at all. Connect with an Ethernet cable instead and use your network in wired mode. It'll be faster as well as more secure.
- You could make your network a "hidden" one (in other words, so the network name (SSID) is not broadcast). Only people who know the network name can connect by typing in the correct SSID and password. Hidden networks can sometimes be a bit erratic if you use Windows XP and Microsoft's default networking software, but they work fine with most other systems. Opinions vary on whether hidden networks do anything for security. Some people claim they are more secure; others say they have security risks.
A brief history of wireless

Photo: One of the original pioneers of wireless, Guglielmo Marconi. Photo courtesy of US Library of Congress
- 1888: German physicist Heinrich Hertz (1857–1894) makes the first electromagnetic radio waves in his lab.
- 1894: British physicist Sir Oliver Lodge (1851–1940) sends the first message using radio waves in Oxford, England.
- 1899: Italian inventor Guglielmo Marconi (1874–1937) sends radio waves across the English Channel. By 1901. Marconi has sent radio waves across the Atlantic, from Cornwall in England to Newfoundland.
- 1940s: Taxi firms begin using two-way radios.
- 1944: Hedy Kiesler Markey (better known as the actress Hedy Lamarr) and George Antheil patent spread spectrum frequency hopping, a way of making wireless communication more reliable and secure by transmitting and receiving on different radio frequencies.
- 1970s: First analog cellphones appear, developed in Chicago by Illinois Bell and AT&T.
- 1980s: GSM (Global System for Mobile communications) digital cellphones appears in Europe, followed by PCS (Personal Communications Services) phones in the United States.
- 1990: A working group of wireless experts begins work drafting the standard that will become Wi-Fi.
- 1994: Nokia, Finnish cellphone maker, sends data over a cellphone network.
- 1994: Phone.com develops WAP in the United States.
- 1997: Wi-Fi standard (IEEE 802.11) is agreed internationally.
- 1998: The name "Bluetooth" is officially adopted for a proposed new kind of short-distance wireless link.
- 1999: Japanese telecommunications company NTT DoCoMo develops i-mode.
- 1999: Steve Jobs of Apple Computer decides to incorporate a version of Wi-Fi called AirPort into the iBook laptop, effectively making it the first mass-market Wi-Fi product.
- 2000: The first Bluetooth headset goes on sale.
- 2005: Wi-Fi is officially added to Webster's Dictionary by Merriam-Webster.
- 2007: Apple Computer releases its iPhone—tilting the balance of power from desktop PCs and wired Internet to mobile devices and wireless Internet.
- 2010: Apple releases the iPad tablet, giving users all the convenience of a wireless smartphone with a bigger display closer to that of a desktop PC.
- 2015: Google announces its Mobile-Friendly algorithm update, rewarding websites that reformat themselves appropriately for smartphones.
- 2015: Wi-Fi celebrates its 25th birthday! By the end of 2015, there are 7 billion wireless cellphone subscriptions.cellphone subscriptions.
Y . I/O IIIIII How the World Wide Web (WWW) works

Twenty or thirty years ago, there was something you could take for granted: you could walk into a public library, open up a reference book, and find information on almost any subject you wanted. What we take for granted nowadays is that we can sit down at practically any computer, almost anywhere on the planet, and access an online information library far more powerful than any public library on Earth: the World Wide Web. Twenty-first century life is so dependent on the Web that it seems remarkable we ever lived without it. Yet the Web was invented less than 20 years ago and has been a huge popular success for only about half that time. One of the greatest inventions of all time... is also one of the newest!
Photo: Our gateway to the world: the World Wide Web (WWW). Websites like this arrive at your computer when remote computer send data to you over the Internet. The Web is just one of many things that uses the Internet.
What's the difference between the Web and the Net?

Photo: Imagine this little computer network scaled up several hundred million times... and you have a picture of the Internet. Photo courtesy of NASA Glenn Research Center (NASA-GRC).
Let's get one thing straight before we go any further: the Web and the Internet are two totally different things:
- The Internet is a worldwide network of computers, linked mostly by telephone lines; the Web is just one of many things (called applications) that can run on the Internet. When you send an email, you're using the Internet: the Net sends the words you write over telephone lines to your friends. When you chat to someone online, you're most likely using the Internet too—because it's the Net that swaps your messages back and forth. But when you update a blog or Google for information to help you write a report, you're using the Web over the Net. You can read more in our article about how the Internet works.
- The Web is the worldwide collection of text pages, digital photographs, music files, videos, and animations you can access over the Internet. What makes the Web so special (and, indeed, gives it its name) is the way all this information is connected together. The basic building blocks of the Web are pages of text, like this one—Web pages as we call them. A collection of Web pages on the same computer is called a website. Every web page (including this one) has highlighted phrases called links (or hypertext links) all over it. Clicking one of these takes you to another page on this website or another website entirely. So far, so simple.
How computers can talk the same language
The really clever thing about the Internet is that it allows practically every computer on the planet to exchange information. That's a much bigger deal than it sounds. Back in the earlier days of computers, in the 1960s, 1970s, and 1980s, it was rare for computers to be able to exchange information at all. The machines made by one manufacturer were often totally incompatible with those made by everyone else. In the 1970s, early personal computers (which were called microcomputers) could not even run the same programs. Instead, each type of computer had to have programs written specially for it. Hooking computers up together was possible, but tricky. So most computers were used as standalone machines, like gigantic pocket calculators. Things like email and chat were all but impossible, except for a handful of scientists who knew what they were doing.![Apple ][ microcomputer in a museum glass case](https://cdn4.explainthatstuff.com/appleII.jpg)
Photos: Microcomputers like this Apple ][ sold in the hundreds of thousands in the late 1970s and early 1980s, but machines made by one company couldn't share information with those made by other manufacturers.
All this began to change in the 1980s. The first thing that happened was that IBM—the world's biggest computer company, famous for its "big blue" mainframes—introduced a personal computer for small businesses. Other people started to "clone" (copy) it and, pretty soon, all personal computers started to look and work the same way. Microsoft came up with a piece of software called Windows that allowed all these "IBM-compatible" computers to run the same programs. But there was a still a problem getting machines like home computers talking to giant machines in science laboratories or big mainframes in large companies. How could computers be made to talk the same language?
The person who solved that problem was English computer scientist Tim Berners-Lee (1955–). In the 1980s, he was working at CERN, the European particle physics laboratory, which is staffed mostly by people from universities around the world who come and go all the time, and where people were using all kinds of different, incompatible computers. Berners-Lee realized CERN had no "memory": every time people left, they took useful information with them. A related problem was that people who used different computers had no easy way of exchanging their research. Berners-Lee started to wonder how he could get all of CERN's computers—and people—talking together.
What's the difference between HTTP and HTML?
Although early computers were pretty incompatible, almost all of them could store or process information using ASCII (American Standard Code for Information Interchange), sometimes known as "plain text." In ASCII, the numbers 0–255 are used to represent letters, numbers, and keyboard characters like A, B, C, 1, 2, 3, %, &, and @. Berners-Lee used ASCII to come up with two basic systems of rules (known in computer terminology as protocols). If all the computers at CERN followed those two rules, he realized they could exchange any information very simply.He called the first rule HTTP (HyperText Transfer Protocol). It is essentially a way for two computers to exchange information through a simple "conversation," whether they're sitting next to one another in the same room or on opposite sides of the world. One computer (which is called a client and runs a program called a web browser) asks the other computer (which is called a server or web server) for the information it needs with a series of simple messages. The web browser and the web server then chat away for a few seconds, with the browser sending requests for the things it wants and the server sending them if it can find them. The HTTP conversation between a web browser and and a web server is a bit like being at a dinner table when someone says: "Pass the salt, please", someone else says "Here it is", and the first person says "Thank you." HTTP is a sort of simple, polite language that all computers have learned to speak so they can swap files back and forth over the Internet.
A computer also needs to be able to understand any files it receives that have been sent by HTTP. So Berners-Lee introduced another stroke of genius. His second rule was to make all the CERN computers exchange files written in a common language called HTML (HyperText Markup Language). It was based on ASCII, so any computer could understand it. Unlike ASCII, HTML has special codes called tags to structure the text. A Web browser can read these tags and use them to display things like bold font, italics, headings, tables, or images. Incidentally, for the curious among you: you can see what the "secret" HTML behind any web page looks like by right clicking your mouse on a web page and then selecting the View source or View page source option. Try it now!
Photo: An example of HTML code. This is the HTML that produces this web page. The little codes you can see inserted between angled brackets (< and >) are bits of HTML, which identify parts of the text as headings, paragraphs, graphics and so on. For example, new paragraphs are marked out with <p> and medium-sized headings with <h2> (header level 2).
HTTP and HTML are "how the Web works": HTTP is the simple way in which one computer asks another one for Web pages; HTML is the way those pages are written so any computer can understand them and display them correctly. If you find that confusing, try thinking about libraries. HTTP is like the way we arrange and access books in libraries according to more or less the same set of rules: the fact that they have books arranged on shelves, librarians you can ask for help, catalogs where you can look up book titles, and so on. Since all libraries work roughly the same way, if you've been to one library, you know roughly what all the others are like and how to use them. HTML is like the way a book is made: with a contents at the front, an index at the back, text on pages running left to right, and so on. HTML is how we structure information so anyone can read it. Once you've seen one book, you know how they all work.
When Browser met Server
Web browsers (clients) and servers converse not in English, French, or German—but HTTP: the language of "send me a Web page", "Okay, here it is." This is a brief example of how your browser could ask to see our A-Z index page and what our server would say in response. The actual page and its information is sent separately.What the browser asks for
GET /azindex.html HTTP/1.1Host: www.explainthatstuff.com,
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:44.0) Gecko/20100101 Firefox/44.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8,
Accept-Language: en-gb,en;q=0.5,
Accept-Encoding: gzip,deflate,
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7,
Keep-Alive: 300,
Connection: keep-alive,
What the server replies
HTTP/1.1 200 OKDate: Mon, 08 Feb 2016 09:03:23 GMT
Server: Apache
Expires: Wed, 09 Mar 2016 09:03:23 GMT
Content-Encoding: gzip
Content-Length: 19702
Content-Type: text/html; charset=UTF-8
What does it all mean? Briefly, the browser is explaining what software it is (Firefox), what operating system I'm running (Linux Ubuntu), which character-sets (foreign fonts and so on) it can accept, which forms of compressed file it can understand (gzip, deflate), and which file it wants (azindex.html). The server (running software called Apache) is sending a compressed file (gzip), along with data about how long it is (19702 bytes) and what format it's in (text/html, using the UTF-8 character set).
Http status codes
Right at the start of the server's reply, you can see it says HTTP/1.1 200 OK: the 200 "status code" (sometimes called a response code) means the server has correctly located the page and is sending it to the browser. A server can send a variety of other numeric codes too: if it can't find the page, it sends a 404 "Not Found" code; if the page has moved elsewhere, the server sends a 301 "Permanently moved" code and the address of the page's new location; and if the server is down for maintenance, it can send a 503 "Service Unavailable" code, which tells browsers they should try again later.What is a URL?
There was one more clever thing Berners-Lee thought of—and that was a way for any computer to locate information stored on any other computer. He suggested each web page should have something like a zip code, which he called a URL (a Universal or Uniform Resource Locator). The URL is the page address you see in the long bar at the top of your Web browser.The address or URL of this page is: http://www.explainthatstuff.com/howthewebworks.html
What does all that gobbledygook mean? Let's take it one chunk at a time:
- The http:// bit means your computer can pull this page off my computer using the standard process called HTTP.
- www.explainthatstuff.com is the address or domain name of my computer.
- howthewebworks.html is the name of the file you're currently reading off my computer.
- The .html part of the filename tells your computer it's an HTML file
How to set up your own website
The famous American inventor and publisher Benjamin Franklin once said that two things in life are certain: death and taxes. These days, he might add something else to that list: websites—because just about everybody seems to have one! Businesses promote themselves with websites, television soaps have spinoff sites devoted to their characters, newlyweds set up sites for their wedding photographs, and most kids have profiles (statements about themselves and what they like) on "social-networking sites" such as Facebook. If you feel like you're getting left behind, maybe it's time to set up a site yourself? How do you go about it?What is a website?
The basic idea of the Web is that you can read information that anyone else has stored on a publicly accessible space called their website. If you're familiar with using computers for wordprocessing, you'll know that when you create a document (such as a letter or a CV/resumé), it exists on your computer as a file, which you store in a place called a folder (or directory). A website is simply a collection of interlinked documents, usually stored in the same directory on a publicly accessible computer known as a server. Apart from the main documents (text pages), a website generally also contains images or graphic files (photographs, typically stored as JPG files, and artworks, usually stored as GIF or PNG files). So the basic idea of creating a website involves writing all these text pages and assembling the various graphic files you need, then putting them all together in a folder where other people can access them.What do you need to host a website?
Theoretically, you could turn your own computer into a server and allow anyone else on the planet to access it to browse your website. All you have to do is configure your computer in a certain way so that it accepts incoming traffic from the Internet and also register your computer with all the other servers on the Internet so they know where to find it. There are three main reasons why this is not generally a good idea. First, you won't be able to use your computer for anything else because it will be spending all its time serving requests for information from other people. (But if you have more than one computer, that's not such a problem.) Second, you'd have to make sure that your computer was switched on and available 24 hours a day—and you might not want to do that. Third, making your computer available to the Internet in this way is something of a security risk. A determined hacker might be able to access all the other folders on your machine and either steal your information or do other kinds of malicious damage.So, in practice, people rent web space on a large computer operated by an Internet service provider (ISP). This is known as getting someone to host your website for you. Generally, if you want to set up a website, you will need a hosting package (a basic contract with an ISP to give you so much disk space and bandwidth (the maximum amount of information that your website can transfer out to other people each month). The web space you get is simply a folder (directory) on the ISPs server and it will have a fairly obscure and unmemorable name such as: www.myownpersonalISP.com/ABC54321/ That's not exactly the sort of thing you want to paint on the side of your truck, if you're in business. So you'll need a more memorable name for your website—also called a domain name. The domain name is simply a friendly address that you give to your website so that other people can find it more easily. The domain address is set up to point to the real address of your site at your ISPs server (www.myownpersonalISP.com/ABC54321/ ), so when people type your domain name into their Web browser, they are automatically redirected to the correct address without actually having to worry about what it is.
Some ISPs offer a user-friendly system where you simply purchase a domain name and hosting package for a single annual payment (generally, it will be less than about $60 or £30 per annum). With other ISPs, you have to buy the domain name and the hosting package separately and that works out better if you are hosting several different domains with the same ISP. Buying a domain name makes you its legal owner and you'll find that you are immediately registered on a central database known as WHOIS, so that other people can't use the same name as well.
How do you create web pages?
Setting up a domain name and Web hosting package takes all of five minutes; creating a website can take an awful lot longer because it means writing all the information you need, coming up with a nice page layout, finding your photographs, and all the rest of it. Generally, there are three ways to create web pages.Raw HTML
The most basic way of creating web pages is to use a text editor such as notepad or WordPad on Windows and build up your pages from raw HTML web page coding as you go. Generally, this gives you a much better understanding of how web pages work, but it's a bit harder for novices to get the hang of it—and unless you're a geek you may not want to bother. Instead of creating pages from scratch, you can use ready-made ones called templates. They're bare-bones, pre-designed HTML files into which you simply insert your own content. Just change the bits you need and you have an instant website! The main drawback of templates is that you can end up with a me-too site that looks the same as everyone else's.WYSIWYG editors
Another approach is to use an editing program that does all the hidden Web-page coding (known as HTML) for you. This is called a WYSIWYG (what you see is what you get) editor because you lay out your pages on the screen broadly as you want them to appear to everyone who browses your site. Popular programs such as Dreamweaver work in this way. Most word processors, including Microsoft Word and OpenOffice, let you convert existing documents into web pages ("export HTML files") with a couple of mouse clicks.Content management systems
The final method is to use what's called a content-management system (CMS), which handles all the technical side of creating a website automatically. You simply set up a basic page template, style its visual appearance with what's called a "theme," create your various interlinked pages based on the template, and then upload them. CMS systems like Wordpress, Drupal, and Joomla work this way. You can add various extra functions to them using what are called plugins.How do you upload web pages?
Once you've created your web pages and you have your domain name and web space, you simply need to upload the pages onto your web space using a method called FTP (file transfer protocol). It's very easy: just like copying files from one folder of your computer to another. When you've uploaded your files, your website should be publicly accessible within seconds (assuming that your domain name has already been registered for at least a couple of days first). Updating your web pages is then simply a matter of updating them on your local computer, as often as you wish, and copying the changes onto your web space as necessary. Generally it's best to do all your updating on copies of your pages on your own computer rather than editing live pages on the server itself. You avoid embarrassing mistakes that way, but you also have a useful backup copy of the entire site on your computer in case the server crashes and loses all your files.How can you promote a website?
You want lots of other people to find your website, so you'll need to encourage other websites to make links to yours. You'll also need to register your site with search engines such as Google, Bing, and all the dozens of others. Sooner or later, search engines like Google will pick up your site if it's linked by other sites that they're already indexing, because they're constantly "crawling" the web looking for new content.And that's pretty much all there is to it. The best way to learn about websites is to build one for yourself. So, off you go and do it! You can learn all about building basic web pages by playing with HTML files on your computer. Once you're confident about what you're doing, it's easy to take the next step and make a world-wide website for the whole wide world!
Y . I /O IIIIII Mobile broadband
You love the speed and convenience of broadband—but there's a snag: it's tied to your home telephone line. If you're a "road warrior", often working away from home, or you have a long commute into work each day, maybe using your laptop on the train or the bus, a fixed broadband connection isn't much help. What you need is a broadband connection you can take with you—the broadband equivalent of your cellular (mobile) phone. Until recently, using a laptop with a cell phone was a nightmarishly painful experience. The fastest speed you could achieve working in this way was a measly 9.6 kbps (roughly five times slower than a typical dial-up Internet connection). It really was excruciatingly slow! Now, thanks to hugely improved cellphone networks, you can get broadband-speed, wireless Internet access through a mobile phone connection wherever you happen to be. How does mobile broadband work? Let's take a closer look!
Photo: This is all you need to go online with mobile broadband. Technically, it's an HSDPA broadband wireless modem made by ZTE—but the phone companies call them "dongles". The dongle simply plugs into your laptop's USB socket.
How does mobile broadband work?
Mobile broadband is a really simple idea, but the specifics are quite complex. In this article, we'll give you a quick overview for starters, followed by a more detailed technical explanation for those who want it. If you're not familiar with how ordinary cellphones work, how the Internet works, or what makes broadband different from dial-up, you may want to start with some of those articles first and come back here afterwards.
Photo: An alternative, slightly older mobile broadband dongle made by Huawei Technologies. This one attaches with the short silver USB cable you can see coming out at the bottom right and even came with a little bit of Velcro so I could attach it conveniently to my laptop! This dongle (and the one in the top photo) was supplied by the UK wireless company 3; in the United States, mobile broadband is offered by such companies as Sprint, Verizon, and AT&T.
Broadband on a cellphone network
Cellular phones were largely inspired by landlines (traditional telephones wired to the wall) and worked in a very similar way—until recently. A landline effectively establishes a permanent connection—an unbroken electrical circuit—between your phone and the phone you're calling by switching through various telephone exchanges on the way: this is called circuit switching. Once a landline call is in progress, your line is blocked and you can't use it for anything else.If you have broadband enabled on your telephone line, the whole thing works a different way. Your telephone line is effectively split into two lines: a voice channel, that works as before, by circuit switching, and a data channel that can constantly send and receive packets of digital data to or from your computer by packet switching, which is the very fast and efficient way in which data is sent across the Internet. (See our article on the Internet if you want to know more about the difference between circuit switching and packet switching.)
As long as cellphones were using circuit-switching technologies, they could work only at relatively slow speeds. But over the last decade or so, most service providers have built networks that use packet-switching technologies. These are referred to as third-generation (3G) networks and they offer data speeds similar to low-speed landline broadband (typically 350kbps–2MBps). Over time, engineers have found ways of making packet-switching cellphone networks increasingly efficient. So 3G evolved into HSDPA (High-Speed Downlink Packet Access), HSPA, or 3.5G, which is up to five times faster than 3G. Predictably enough, 4G networks are now commonplace, based on technologies called Mobile WiMAX and LTE (Long-Term Evolution). 5G is already in development and expected to become available around 2020.
How do you use mobile broadband
You can use mobile broadband in two ways. If you have a reasonably new cellphone, you can download music and videos to your phone at high (broadband) speeds. Unlike with a traditional phone call, where you pay for access by the minute, with mobile broadband you pay by the amount you download. So your mobile phone provider might sell you a certain number of megabytes or gigabytes for a fixed fee. For example, you might pay so much each month and be able to download 1GB, 5GB, or 10GB of data (but there's no restriction on how long you can actually be online, as there used to be with dialup Internet contracts).The other way to use mobile broadband (and the way I use it) is as a way of getting online with a laptop when you're on the move. You buy a "dongle" (which is a very small, lightweight modem that plugs into the USB socket of your laptop), buy some access time from a service provider, plug your dongle into the laptop, and away you go. The dongle has built-in software so it automatically installs itself on your PC. I was up and running with my mobile broadband in less than five minutes. Think of your dongle as a cross between a modem and a cellphone—but, because it has no battery or screen, it's a fraction of the weight of a cellphone and somewhat smaller. The smallest dongles are slightly bigger than USB flash memory sticks and about twice as heavy (the ZTE dongle in our top photo weighs about 21g or 0.7 oz).

Photo: Another view of my broadband dongle, this time photographed from underneath. You can see the SIM card drawer opened up with the SIM card exposed. You need a SIM card in your dongle to give you access to your phone network. It's identical to the SIM card you'd use in a cellphone (indeed, you can take it out and use it in a cellphone to make calls if you want to).
How good is mobile broadband?
If you need to use broadband on the move, it's a brilliant solution. Anywhere you can get a good (3.5G or 4G) signal, you can get high-speed broadband. Where there is no 3.5G or 4G network coverage, your broadband will work at 3G speeds (less than about 300kbps)—but that's still about seven times faster than a dial-up landline connection. Depending on which country you're in and where you live and work, you may find mobile broadband has much better overall coverage than Wi-Fi—in other words, you can go online in far more places—and it can work out far cheaper too.The drawback is that you're using a cellphone network for your access, so the quality of your connection can vary drastically. If you're working on a train, for example, you can expect to be regularly connected and disconnected as you move in and out of cell coverage—just as a cellphone call gets cut off when you go through tunnels and under bridges. Right now, I seem to be working on the edge of a cell, so the quality of my connection is constantly flickering between 3.5G and 3G and my connection speed is varying from moment to moment. So the erratic quality of my broadband service, at this moment, does not compare very well with what I'd get from a Wi-Fi hotspot. But the nearest hot-spot is five miles away and would charge me as much for a couple of hours access as I pay for a whole month of mobile broadband, so I have no real reason to complain.
Two bits of advice, then: if you plan on using your mobile broadband in certain specific locations most of the time, you need to check out the network coverage in those places before you buy. Most phone service providers publish maps of their coverage, but there is no substitute for checking the coverage by using the system for real. (In the UK, the 3 cellphone company I use allows customers a couple of days grace after taking delivery of the USB broadband modem to try out the network coverage. If you're not happy you can return the equipment for a refund.)
All told, I've found mobile broadband the best solution to working on the move. It's infinitely faster than a dial-up mobile, it's much faster than a dial-up landline, and it's cheaper and more convenient than Wi-Fi. I love it!
How will mobile broadband develop in future?
Cellphone companies are very excited about mobile broadband—and for good reason: mobile wireless broadband users are growing much faster than fixed (landline) broadband users. Worldwide, more people are now using mobile broadband than landline broadband. A few years ago, industry pundits were predicting that HSDPA would capture up to three quarters of the mobile market, though it's now starting to face competition from 4G systems (WiMAX and LTE).Over the next decade, talk will turn increasingly to 5G, which will offer another 10-fold increase in speed, cheaper bandwidth, greater reliability, and lower latency (faster connections), making it possible for many more people (and things) to be online at the same time. I say "things," because one major goal of 5G is to allow more "inanimate objects" to be connected online. This will help to power the so-called Internet of Things, connecting everything from smart-home central heating systems and instantly trackable parcels to the world's increasingly interlinked computer systems. Another goal of 5G is to achieve greater integration with wired, landline networks: at some point, the distinction between "wired" and "wireless" is likely to disappear altogether as they converge and merge into a single, hybrid telecommunications network—part wired, part wireless—that can accessed anyhow, anytime, anywhere by anyone or anything.

The more detailed explanation
If that's all you want to know about mobile broadband, you can safely stop reading now. The rest of this article is for those of you who want a slightly more technical explanation of HSDPA (3.5G), LTE (4G), and 5G networks. First, it helps if we understand a little bit about the mobile cellphone systems that preceded it and how they've evolved from one another.Analog landlines
Imagine you want to make lots of money by setting up a telephone company in your area. Back in the 1950s, you would have had to run separate telephone lines to the homes of all your customers. In effect, you would have given each customer a separate electrical circuit that they could use to connect to any other customer via some central switching equipment, known as the exchange. Phone calls made this way were entirely analog: the sound of people's voices was converted into fluctuating electrical signals that traveled up and down their phone lines.Analog cellphones (1G)
By the 1970s, mobile telephone technology was moving on apace. You could now give your customers cellphones they could use while they were on the move. Instead of giving each person a wired phone, what you gave them was effectively a radio handset that could transmit or receive by sending calls as radio waves of a certain frequency. Now if everyone uses the same frequency band, you can hear other people's calls—indeed, the calls get all jumbled up together. So, in practice, you divide the frequency band available into little segments and let each person send and receive on a slightly different frequency. This system is called frequency-division multiple access (FDMA) and it's how the early analog cellphones worked (cordless landline telephones still work this way). FDMA simply means lots of people use the cellphone system at once by sending their calls with radio waves of slightly different frequency. FDMA was like a radio version of the ordinary landline phone system and, crucially, it was still analog. FDMA cellphones were sometimes called first-generation (1G) mobile phones.Digital cellphones (2G)
The trouble with FDMA is that frequencies are limited. As millions of people sought the convenience of mobile phones ("phones to go"), the frequency band was soon used up—and the engineers had to find a new system. First, they swapped from analog to digital technology: phone calls were transmitted by sampling the sound of people's voices and turning each little segment into a numeric code. As well as sharing phone calls between different frequency bands, the engineers came up with the idea of giving each phone user a short "time share" of the band. Effectively, the mobile phone system splits up everyone's calls into little digital chunks and sends each chunk at a slightly different time down the same frequency channel. It's a bit like lots of people being in a crowded room together and taking it in turns to talk so they don't drown one another out. This system is called time-division multiple access (TDMA) and it's a big advance on FDMA. GSM cellphones, based on TDMA, were the second generation (2G) of mobile phones.High-speed digital cellphones (3G)
Even TDMA isn't perfect. With the number of phone users increasing so fast, the frequency bands were still getting overcrowded. So the engineers put their thinking caps on again and found yet another way to squeeze more users into the system. The idea they came up with next was called code-division multiple access (CDMA) and uses elements of both TDMA and FDMA so a number of different callers can use the same radio frequencies at the same time. CDMA works by splitting calls up into pieces, giving each piece a code that identifies where it's going from and to. It's effectively a packet-switching technology similar to the way information travels across the Internet and it can increase the overall capacity of the phone system by 10–20 percent over TDMA. Basic CDMA evolved into an even higher-capacity system called Wideband CDMA (WCDMA), which sends data packets over a wide band of radio frequencies so they travel with less interference, and more quickly and efficiently (an approach known as spread-spectrum). WCDMA is an example of a third generation (3G) cellphone system. The 3G equivalent of GSM is known as UMTS."Broadband" cellphones (3.5G)
Ordinary CDMA is great for sending phone calls, which involve two-way communication. But it's not so good for providing Internet access. Although Net access is also two-way (because your computer is constantly requesting Web pages from servers and getting things back in return), it's not a symmetrical form of communication: you typically download many times more information than you upload. Fast home broadband connections achieve their high speeds by splitting your phone line into separate voice and data channels and allocating more data channels to downloading than to uploading. That's why broadband is technically called ADSL: the A stands for asymmetric (and DSL means digital subscriber line)—and the "asymmetry" is simply the fact that you do more downloading than uploading.Think of HSDPA as a kind of broadband, cellular ADSL. It's a variation of CDMA that is designed for downloading—for sending lots of data to broadband cellphones or laptops attached with mobile broadband modems. It's optimized in various different ways. First, like ADSL, it introduces a high-speed downloading channel called HS-DSCH (High Speed Downlink Shared Channel), which allows lots of users to download data efficiently at once. Three other important features of HSDPA are AMC (adaptive modulation and coding), fast base-station scheduling (BTS), and fast retransmissions with incremental redundancy. What does all that stuff actually mean?
- AMC (Adaptive modulation and coding) simply means that the cellphone system figures out how good your connection is and changes the way it sends you data if you have a good connection. So if you're in the middle of a cell (near a cellphone antenna base station), you'll get more data more quickly than if you're at the edge of a cell where reception is poor.
- Fast base-station scheduling means that the base station figures out when and how users should be sent data, so the ones with better connections get packets more often.
- In any packet-switching system, packets sometimes get lost in transmission, just as letters get lost in the regular mail. When this happens, the packets have to be retransmitted—and that can take time. With ordinary CDMA technologies, retransmissions have to be authorized by a top-level controller called the radio network control (RNC). But with HSDPA, fast retransmissions are organized by a system closer to the end user, so they happen more quickly and the overall system is speeded up. Incremental redundancy means the system doesn't waste time retransmitting bits of data that successfully got through first time.
High-speed broadband cellphones (4G)
It's taken about 40 years for cellphones to get from basic analog, voice conversations up to 3.5G and 4G mobile broadband. Not surprisingly, better phone systems are already in development and it won't be long before we have 5G, 6G, and more! There are already improved systems called HSDPA Evolved, offering download speeds of 24–42 Mbps, and 3G/4G LTE (Long Term Evolution), promising 50Mbps–100Mbps. Broadly, 4G is something like 10–50 times faster than 3G (depending which way the wind is blowing and whose figures you choose to believe).What makes 4G better than 3.5G and 3G? Although there are numerous differences, one of the most significant is that CDMA (the way of getting many signals to share frequencies by coding them) is replaced by a more efficient technology called orthogonal frequency-division multiple access (OFDMA), which makes even better use of the frequency spectrum. Effectively, we can think of OFDMA as an evolution of the three older technologies, TDMA, FDMA, and CDMA. With traditional FDMA, the available frequency spectrum is divided up into parallel channels that can carry separate calls, but there still has to be some separation between them to stop them overlapping and interfering, and that means the overall band is used inefficiently. With OFDMA, signals are digitally coded, chopped into bits, and sent on separate subchannels at different frequencies. The coding is done in such a way that different signals are orthogonal (math-speak meaning they are made "independent" and "unrelated" to one another), so they can be overlapped much more without causing interference, giving better use of the spectrum (a considerable saving of bandwidth) and higher data speeds. OFDMA is an example of multiplexing, where multiple, different frequency bands are used to send data instead of one single frequency band. The big advantage of this is that there's less signal disruption from interference (where selected frequencies might be destroyed by transmissions from other sources) and fading (where signals gradually lose strength as they travel); lost data can be reassembled by various error-correction techniques. At least, I think that's how it works—I'm still figuring it out myself!
The next generation (5G)
Of course, it doesn't stop there! Cynics would say that cellphone manufacturers need us to update to a new model each year, while the cellphone networks want us to send more and more data; both are helped by the shift to newer, better, and faster mobile networks. But, overwhelmingly, the main driver for 5G is that so many more people—and things—want to connect wirelessly to the Internet.As we've already seen, 5G is meant to be faster, more reliable, higher capacity, and lower latency than 3G and 4G, which already use their very congested part of the frequency spectrum very efficiently. So how do you possibly get even more out of a limited band of radio waves? One solution is to switch to a completely different, less-used frequency band. Where existing 4G cellphone networks use radio waves that have frequencies of roughly 2GHz and wavelengths of about 15cm (6in), 5G could switch to much higher frequencies (between 30–300GHz) and shorter wavelengths (a millimeter or less). These so-called "millimeter-waves" are currently used by things like radar and military communication, so there's much less congestion than in the current frequency band. But the drawback is that these waves don't travel so far or so well through objects like walls, so we might need more mobile antennas, mobile antennas inside our buildings, more cells in our cellphone networks, completely different antennas in our smartphones, and a range of other improvements. The switch to higher frequencies is one aspect of 5G; the other aspect would be the development of improved technologies building on existing approaches such as HSDPA and LTE. For the moment, details of exactly how 5G will work are still vague and very much under discussion; I'll be adding more information here as it becomes available.
Summary
Here's a hugely simplified attempt to represent, visually and conceptually, the four key wireless technologies. I emphasize that it is a considerable simplification; if you want a proper, technical account, you'll find a selection of books and papers in the references at the end.
- TDMA: In the simplest case we can imagine, each call gets a time-share of the complete frequency band. It's a bit like callers waiting in line for a payphone. Each one waits until the phone is vacated by the previous caller, makes their call, and hands on to the next person.
- FDMA: With the total frequency band split up into smaller bands, we can imagine sending multiple calls in parallel. This is a bit like having four payphones in a line; four callers can use them simultaneously. We could also run TDMA at the same time, dividing each of the smaller bands into time slots.
- CDMA: We break each call into pieces, code them, and send them down any available channel. This makes much better use of our available frequency spectrum, because none of the channels is idle at any time. However, channels have to be kept separate to stop them from interfering, which means our total frequency band is used inefficiently.
- OFDMA: We set up our system so that we can, effectively, superimpose channels on top of one another, packing in even more capacity to give even greater data speeds.
How to upgrade your dongle's firmware or switch mobile broadband providers
Warning!
- The information provided here is a general description and may not apply to your own, specific dongle or network service. Do not follow this procedure unless you are technically competent and know exactly what you're doing. I take no responsibility for any loss or damage that may result.
- You may not be able to undo the changes you've made and restore your dongle to how it was before. There is even a chance you could damage your dongle or stop it from working altogether.
- If you change the firmware in your dongle, you may breach your contract with your service provider. You'll almost certainly find they do not give you any technical support if you get into trouble. You may want to ask their advice before you go any further.
- Understand the risk? Know what you're doing? Okay, read on...
The way to do this is to change the firmware (preloaded software) in the dongle, which is stored in flash memory, and use the generic software supplied by the manufacturer on your PC instead of your provider's customized software. Before you go any further, be sure to write down all the connection settings for your current provider (look in the control panel of your dongle's PC software). You will need them later. Next, go to the dongle manufacturer's website (it's probably a company such as Huawei), download the latest firmware package, and follow the instructions to load it into your dongle. Make sure you get exactly the right firmware to match your dongle's model number. Follow the manufacturer's instructions to the letter!
The next time you use your dongle, you'll find it runs a more generic version of the connection software branded with the manufacturer's logo (i.e. Huawei, or whoever it might be) rather than the service provider's, and you'll have to enter your connection settings manually the first time. You should find the dongle works perfectly, as before—it may even work faster and more reliably now because you're using newer software. To use a different provider, all you need to do is swap over your SIM card and enter the connection settings for your new provider using the PC software.
Photo (right): This is the manufacturer's own version of essentially the same software, called Huawei Mobile Connect. This is what you'll see if you flash the firmware of your dongle. It works the same but just looks a little bit different. Connection speeds are shown on the right (the modem wasn't actually connected when this screenshot was taken).
Y . I/O IIIIIII Broadband over power lines (BPL)

High-speed Internet access anywhere, anytime—that's what we've increasingly come to expect in the 21st-century information age. But what if you live in a rural area where it's too expensive for a telecoms company to provide broadband? Or what if your house has old telephone wiring or the room you want to work in doesn't have a telephone access point? Worry not! The solution could be BPL (broadband over power lines), also called EOP (Ethernet over power)—a way of piping broadband to your home and channeling it from one room to another using the standard electricity supply. BPL is also known as HomePlug (the name of an alliance of manufacturers who make the equipment) and, in the UK, as "networking over the mains." Let's take a closer look at how it works!
Photo: Ordinary, medium-voltage electric power lines like these can be used to bring broadband Internet to your home. That's because you can do more than one thing with the same electricity cable at the same time.
Sending two signals down one line
If you know something about broadband Internet already, you're probably aware that it works by splitting your ordinary telephone line into a number of separate channels. Some of them carry your phone calls, as usual, some carry downloads (information coming from the Internet to your home), and some handle uploads (information going the opposite way). Broadband uses low-frequency electric signals (the equivalent of low-pitched sounds) to carry ordinary phone calls and higher-frequency signals (like high-pitched sounds) to carry Internet data. Electronic filters separate the two kinds of signal, with the low frequencies going to your telephone and the higher frequencies to your Internet modem.Does that sound so strange? It's really not so hard to use a single medium to carry more than one thing. People work this way all the time. If you've ever stood quietly in a corner of a cocktail party tuning in on different conversations, you'll know how easy it is to do. The air in the room is like a giant pipe carrying many different sounds to your ears. But, using something called selective attention, your brain can tune into one conversation or another depending on whom you find most interesting. Broadband Internet works a bit like this too. A single piece of telephone cable carries both phone calls and Internet data. Your telephone listens just to the calls; your modem lists only to the data.
Access BPL: bringing broadband to your home
Photo: With BPL, your modem takes its signal from your domestic electricity socket rather than your telephone socket.
If you can send computer data down a phone line, there's no reason why you can't channel it down a power line as well. Some Internet service providers (ISPs) are already using overhead and underground power lines to carry broadband data long distances to and from their customers in what's called access BPL. It's exactly the same principle as sending broadband over a phone line: a high-frequency signal carrying the broadband data is superimposed on the lower-frequency, alternating current that carries your ordinary electric power. In your home, you need to have slightly modified power outlets with an extra computer socket. Plug in a special BPL modem, plug that into your computer, and your broadband is up and running in no time.
In-house BPL: carrying broadband within your home
You can also use BPL with traditional telephone or cable broadband to bring Internet access to all the different rooms in your home. You simply plug the Ethernet lead from your normal modem into a special adapter that fits into one of the power outlets. Your home electricity circuit then takes the broadband to and from every room in your house as a high-frequency signal superimposed on top of the power supply. If you want to use broadband in a bedroom, you simply plug another Ethernet adapter into one of the ordinary power outlets in that room and plug your computer into it. In-house BPL, as this system is known, is a great way of getting broadband in any part of your home. It's particularly useful if you have a big house with thick walls that make wireless Internet impossible.Smart homes of the future?
BPL opens up an even more exciting possibility for the future. If we can connect computers using the ordinary power lines in our home, there's nothing to stop us connecting up domestic appliances both to one another and to the Internet. Smart homes (in which appliances are switched on and off automatically by electronic controllers or computers) have used this basic idea for years—but BPL could take it much further and make it far more widespread. Imagine a future where you can use a Web browser on your computer at work to switch on the electric cooker in the kitchen at home, ready for when you arrive. Or how about using the Web browser on your cellphone to turn your home lights on and off when you're staying in a hotel, to give added protection against intruders? Just imagine the possibilities: BPL could take remote control to an amazing new level!How does BPL compare with wireless broadband?

Photo: A typical BPL Ethernet adapter (wired for the British power supply). You plug the adapter (1) into your electricity outlet and then plug your computer or modem into the Ethernet socket (2) on the side. There are extra Ethernet sockets so you can connect games consoles or other equipment too (3).
According to companies who sell the equipment, BPL is a great way to distribute a computer network through your home that's at least as convenient as wireless Internet (Wi-Fi):
- It can send signals up to 200m or 650ft (further than a typical Wi-Fi router, which offers only 35m or 115ft).
- It offers data rates from 200Mbps (million bits per second) to over 1 Gbps (gigabits per second = thousand megabits per second), comparable with or better than a typical Wi-Fi router.
- It will work with other networking products based on Ethernet, such as Net-linked computer games machines.
- It uses encryption to protect signals traveling around your home and is (theoretically at least) much more secure from eavesdropping than wireless networks. However, as with any network, there are still security loopholes.
- You don't need any additional wiring. All you need is two plug units, one for each socket you want to use.
Hybrid setups
There's nothing to stop you using BPL and Wi-Fi in a combined, hybrid setup—and that can work really well for larger homes or older buildings with Wi-Fi "dead spots" (where walls or other obstacles interfere with decent wireless signals). So you could have a wireless router connected to the Internet through satellite, cable, or phone, in the conventional way and talking to smartphones, tablets, and other wireless devices using Wi-Fi. You could plug your in-house BPL adapter into the same router, and into a home power socket, to carry wired broadband signals to other devices, such as desktop computers, smart home equipment, or devices that are simply too far to reach with conventional Ethernet cables or have poor Wi-Fi connectivity. You're free to mix and match as you wish.Advantages and disadvantages of broadband over power lines
Advantages
- Electricity power lines are ubiquitous in most developed countries.
- Access BPL may be quicker, cheaper, and simpler to deploy in rural areas than higher cost, high-speed broadband over telephone lines or cable.
- Access BPL technology is relatively simple.
- Power companies who already supply electricity could also provide inexpensive broadband to existing customers over the same lines, which could help to push down the cost of broadband across the board.
- In-house BPL is perfectly compatible with Wi-Fi and helps to overcome distance and reliability limitations in existing wired and wireless networks.
Disadvantages
- Access BPL is still relatively uncommon. At the time of writing, it's failed to gain momentum in countries such as the United States, the UK, and Australia. In-house BPL is much more popular, however, and still widely available.
- Only low and medium voltage power cables can be used for access BPL.
- Different countries use different power voltages, which would make it harder to sell equipment internationally and push up the cost.
- Signals need booster equipment to make them travel long distances. Transformers, circuit breakers, and surge protectors can interfere with broadband signals.
- Most people already use DSL (traditional broadband) or wireless systems and own routers, modems, and other equipment compatible with it. They'll be reluctant to buy new equipment unless there's a compelling reason to do so.
Y . I/O IIIIIIII Computer models
Is it going to rain tomorrow? How will climate change affect world food production? Is there likely be another stock-market crash? Where will a hurricane do the most damage? These are the sorts of questions you can answer with a computer model—a mathematical way of predicting the future based on what's happened in the past. Computer models have been widely used since the mid-20th century. That's when the first, powerful scientific computers made it possible to study complex problems such as weather forecasting (without looking out of the window) and how atom bombs work (without setting off dangerous explosions). So what exactly is a computer model? Let's take a closer look!
Photo: Computer models are useful for studying things we can't easily visualize in any other way. This is a computer graphic model of the fluid flow and temperature inside a teapot. Photo by courtesy of Pacific Northwest National Laboratory and US Department of Energy.
What is a model?
Have you noticed how children love playing with models? From dolls houses and cuddly dogs to model airplanes and race cars, many of the toys children like most are actually simplified versions of things we find in the world around us. Are kids wasting their time playing with toys like this? Far from it! Monkeying around with a model helps you learn how the world works. Build a model suspension bridge and—whether you realize it or not—you're learning an awful lot about the science of forces and the practicalities of everyday engineering. In theory, you can test whether a new bridge design would work by building a model with an erector set and loading it up with toy cars. That's why NASA scientists build models of rockets and space planes and test them out in wind tunnels. Realistic models of real-world things are called physical models. They're concrete and realistic and you can tell straight away what they're supposed to be.
Photo: A physical model. This is a little wooden model of a real-life sailboat, but you can see that it's hugely simplified. In theory, you could put it in the bathtub and use it to study how sailboats work by blowing on it (using your breath to model the wind). But if you try to do that, you'll find it capsizes straight away. That's because the sails aren't hung realistically and, unlike on a real boat, there is no keel (underwater stabilizing bar) to keep the vessel upright. A model like this is too crudely simplified to use for scientific studies of real boats—but it looks neat on my bookshelf!
How is a mathematical model different?
There are lots of things we need to understand that we can't build out of miniature plastic parts. You can't make a model of the weather that way or predict whether a disease epidemic will spread more in a hot summer or a cold winter. Things like this have to be modeled mathematically. A mathematical model is an abstract way of understanding very complex things like the weather or the world economic system. It's a collection of algebraic equations (things like a+b=2c÷d×e) that relate different quantities called variables (represented here by the letters a, b, c, d, and e). In the case of weather forecasting, the variables are things like air pressure, air temperature, humidity, ocean temperature, wind speed, and so on and they're related by equations based on the laws of physics. In theory, if you've measured some of these things, you can figure out the others by solving the equations; and if you've measured the things many times in the past and know how they relate to one another, you can attempt to predict what will happen in the future. That's mathematical modeling in a nutshell! Unlike with a physical model, a mathematical model doesn't necessarily bear any physical resemblance to the thing it represents; a mathematical model of the weather won't give you a suntan or soak you to the skin. But there are ways of representing mathematical models visually. A graph, for example, might be a visual representation of a mathematical model.Why use a computer for mathematical modeling?

Photo: Computer modeling a wind tunnel test: Building realistic models of new cars to test their aerodynamics is expensive and time consuming, so a lot of this kind of work is now done with computer models. You can even try your hand at it yourself by downloading a wind tunnel modeling app for your smartphone, like this one. It's a great educational exercise for physics students.
You don't necessarily need a computer to make a mathematical model. Pick an easy enough problem and you can do the math in your head or draw yourself a little chart on paper. Let's look at a really simple example. Suppose you're 10 years old and you want to know how tall you're going to be when you're 20. You could guess you're going to be twice as tall (because you'll be twice as old), but if you've done a lot of growing early on and you're tall for your age, that's going to give you the wrong answer. If you've grown at a steady rate (so many centimeters/inches per year), you could guess that your height at some age in the future (let's call it X) is your height at age 10 (call that A) plus the number of years into the future (call that B) times the number of centimeters you grow per year (call that C). So X = A + (B × C). If you're 150cm (1.5m or ˜5 ft) tall at age 10 and grow an average of 5cm (˜ 2 inches) per year for each of the next 10 years, you'll be 150 + (10 x 5) = 200cm (6.5 ft) tall at age 20. That sounds like a fair guess (if a little on the high side)—and it certainly sounds better than just doubling your height at age 10 (which predicts a height of 3m or 10ft by age 20).
A model of something like the weather involves hundreds, thousands, or even millions of different variables linked together by much more complex equations. There are so many variables and so many equations that it would take forever to solve them by hand. When pioneering mathematical modeler Lewis Fry Richardson made one of the world's first detailed weather forecasts this way in the 1920s, using just seven equations, it took him and his wife something like six weeks to figure out a single day's weather! That's why, in practice, supercomputers (ultra-powerful computers) are now used for virtually all mathematical modeling—and why it's now called computer modeling as a result. Let's face it, no-one wants to wait six weeks to hear what the weather was like a couple of months ago!
How do you build a computer model?
The first step in building a model is to decide which variables it should include and figure out the equations that connect them together. This involves making a number of assumptions and simplifications. Going back to our model of height at age 20, you can see we made two notable assumptions: first, that we'd keep growing at all and second that we'd do so at a steady rate between 10 and 20. What if we'd stopped growing at 11 or grown much more rapidly at ages 14 and 15? We could have allowed for that with a more complex equation if we'd wanted to. Another thing we didn't consider was whether our model ceased to be valid at all after a certain age (do the numbers and you'll find it predicts we'll be 3.5m or ˜11.5 ft tall at the age of 50 and 6m or ˜20ft tall if we reach 100). There were all kinds of things we might have considered or incorporated into our height model—but we glossed over them to keep the problem simple to understand and easy to solve.Models are always (by definition) simplified versions of real life and, where mathematical models are concerned, there are good reasons for this. If really complex problems (such as weather forecasting and climate change) are being studied, mathematical models have to be simplified purely so that computers can generate useful results in a reasonable amount of time. The science of modeling is all about ensuring that the variables and equations in a model represent reality as accurately as possible, but there's an art to modeling too—and that involves deciding what kind of simplifications can safely be made without making the model so crude that any results it produces are inaccurate or misleading. Early 1970s models of the climate neglected clouds, for example, which were considered too complex and changeable to represent accurately. Once computers became more powerful, climate models were extended to include the way clouds behave, hopefully producing much more accurate and useful weather forecasts and climate simulations in the process.
Photo: Climate models are based on millions of precise measurements of the weather made all over the world during the last few decades. My computer produced this computer model of the climate as part of Climateprediction.net, in which ordinary computer users help scientists study global warming. Over 47,000 computers in the world are helping to "number crunch" climate data for the project.
Once the model is built, it has to be loaded up with data; in the case of a climate model, that means real-world measurements of the different variables, such as temperature, rainfall, and pressure measurements from around the world going back years or decades. Once that's done, it's possible to verify and validate the model. Verifying a model means running it to see whether it makes reasonable predictions. So if you build a model for weather forecasting and it tells you the temperature in Beijing next week is going to be 5000 degrees, you know you've gone wrong somewhere. Validating a model is a different process that involves running a model to produce results you can check against existing data. So if you build a model of the world's weather using measurements taken during every year of the 20th century (from 1900 to 1999), you might run it forward to the years 2002, 2003, and 2004 (say) to see what predictions it makes. You could compare those predictions with actual measurements made during those years and, if there's good agreement, take that as a validation of the model.
With the model successfully built, verified, and validated, the next step is to use it to make some actual predictions. A weather forecasting model could be used to predict how much rain will fall in Toronto or Berlin for a week or two in advance; a climate model (similar in many ways and based on the same data) would be making far less detailed predictions much further into the future.
What else are computer models used for?
Modeling the weather and climate aren't the only things you can do with computer modeling. Models are used in all kinds of fields from science and engineering to medicine and economics. A model of a newly designed airplane might be used to predict the stresses and strains on different parts of the fuselage at different flying speeds or under different flying conditions (in strong winds, with ice on the wings, or whatever the conditions might be). Military planners often run computer simulations ("wargames") to consider how potential battles might play out with different numbers of tanks, troops, and airplanes. Traffic planners can make models of the highway network (or the streets in a busy city) to test whether new signals or road layouts will make cars run more smoothly. When dramatic accidents occur in space, scientists run models to test the best ways of making repairs or to figure out whether astronauts can return home safely. In all these cases, the modelers can try out many different possibilities and find what works best—without ever leaving their desk!Why use computer models?
This illustrates perhaps the most important advantage of computer modeling: it gives us the ability to ask "what if?" questions about complex aspects of the world we can't easily test in reality. You can't build 100 different designs of skyscraper to see which is most likely to survive an earthquake, but you can do that very easily with a computer model. You can't run a war in four different ways to see which option gives the fewest civilian casualties, but a computer model can give you a pretty good idea. If the problem you're trying to tackle is something like climate change, and you want to know what will happen centuries into the future, computer models are the only tools at your disposal.
Photo: Computer models make difficult and dangerous things easy to study safely. This is a model of the fluid flow inside a nuclear reactor. Photo courtesy of Argonne National Laboratory published on Flickr in 2009 under a Creative Commons Licence.
Modeling also saves time and money. Auto manufacturers routinely test the safety of their cars by wrecking prototypes (test versions) with crash-test dummies inside them, but it saves a great deal of time and money to do a lot of pre-testing with computer models beforehand. Computer models make it possible to run many more tests and cars are safer as a result. Computer models are increasingly being used to predict natural disasters, such as hurricanes, earthquakes, and tsunamis. If weather forecasters can accurately predict which tropical storms will become hurricanes, and how they will behave when they hit land, they can warn people of danger in good time, helping to reduce damage to property and potentially save lives.
Next time you fool around with a model, bear this in mind: you're not playing, your carrying out serious scientific research!
Who invented computer models?
Here's a brief list of some key moments in modeling:- 1920s: Lewis Fry Richardson begins modeling weather using seven mathematical equations, but has no computers to help him .
- 1940s: US mathematician John von Neumann pioneers the use of computers in modeling
- 1950: An early supercomputer called ENIAC makes the world's first computerized weather forecast.
- 1960: The National Center for Atmospheric Research (NCAR) is established in Boulder, Colorado to study weather and climate with complex computer models.
- 1972: Meteorologist Edwin Lorenz sums up the complex, uncertain, nature of weather forecasting by asking his famous question "Does the flap of a butterfly's wings in Brazil set off a Tornado in Texas?". Attempts to answer the question lead to popular interest in a new branch of math known as chaos theory.
- 1972: A group of academics and others known as The Club of Rome runs a computer model of how the planet's resources are being used and concludes human civilization will collapse.
- 1980s: Spreadsheets (computer programs that calculate and draw charts from lists of numbers entered into tables) are developed for inexpensive PCs, so virtually anyone can build and run simple computer models. Spreadsheets soon revolutionize business planning.
- 1990s: The Internet makes it possible for millions of ordinary PC users to help scientists run large, complex computer models by downloading chunks of data and processing them during "downtime." SETI@Home and FightAIDS@Home are two of the best known projects of this kind.
- 2003: Climate scientists launch Climateprediction.net, allowing millions of computer users worldwide to help run a giant model of the climate.
- 2016: Police in Chicago reveal that they are using a computer model to predict people at most risk of committing (or falling victim to) gun crime.

Roll back time a half-century or so and the smallest computer in the world was a gargantuan machine that filled a room. When transistors and integrated circuits were developed, computers could pack the same power into microchips as big as your fingernail. So what if you build a room-sized computer today and fill it full of those same chips? What you get is a supercomputer—a computer that's millions of times faster than a desktop PC and capable of crunching the world's most complex scientific problems. What makes supercomputers different from the machine you're using right now? Let's take a closer look!
Photo: This is Titan, a supercomputer based at Oak Ridge National Laboratory. At the time of writing in 2017, it's the world's third most powerful machine. Picture courtesy of Oak Ridge National Laboratory, US Department of Energy, published on Flickr in 2012 under a Creative Commons Licence.
What is a supercomputer?
Before we make a start on that question, it helps if we understand what a computer is: it's a general-purpose machine that takes in information (data) by a process called input, stores and processes it, and then generates some kind of output (result). A supercomputer is not simply a fast or very large computer: it works in an entirely different way, typically using parallel processing instead of the serial processing that an ordinary computer uses. Instead of doing one thing at a time, it does many things at once.Serial and parallel processing
What's the difference between serial and parallel? An ordinary computer does one thing at a time, so it does things in a distinct series of operations; that's called serial processing. It's a bit like a person sitting at a grocery store checkout, picking up items from the conveyor belt, running them through the scanner, and then passing them on for you to pack in your bags. It doesn't matter how fast you load things onto the belt or how fast you pack them: the speed at which you check out your shopping is entirely determined by how fast the operator can scan and process the items, which is always one at a time. (Since computers first appeared, most have worked by simple, serial processing, inspired by a basic theoretical design called a Turing machine, originally conceived by Alan Turing.)A typical modern supercomputer works much more quickly by splitting problems into pieces and working on many pieces at once, which is called parallel processing. It's like arriving at the checkout with a giant cart full of items, but then splitting your items up between several different friends. Each friend can go through a separate checkout with a few of the items and pay separately. Once you've all paid, you can get together again, load up the cart, and leave. The more items there are and the more friends you have, the faster it gets to do things by parallel processing—at least, in theory. Parallel processing is more like what happens in our brains.
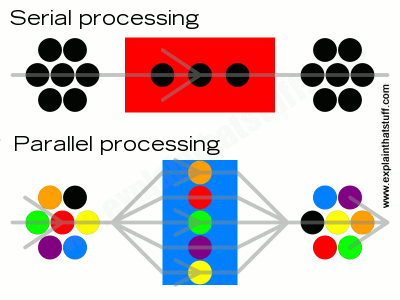
Artwork: Serial and parallel processing: Top: In serial processing, a problem is tackled one step at a time by a single processor. It doesn't matter how fast different parts of the computer are (such as the input/output or memory), the job still gets done at the speed of the central processor in the middle. Bottom: In parallel processing, problems are broken up into components, each of which is handled by a separate processor. Since the processors are working in parallel, the problem is usually tackled more quickly even if the processors work at the same speed as the one in a serial system.
Why do supercomputers use parallel processing?
Most of us do quite trivial, everyday things with our computers that don't tax them in any way: looking at web pages, sending emails, and writing documents use very little of the processing power in a typical PC. But if you try to do something more complex, like changing the colors on a very large digital photograph, you'll know that your computer does, occasionally, have to work hard to do things: it can take a minute or so to do really complex operations on very large digital photos. If you play computer games, you'll be aware that you need a computer with a fast processor chip and quite a lot of "working memory" (RAM), or things really slow down. Add a faster processor or double the memory and your computer will speed up dramatically—but there's still a limit to how fast it will go: one processor can generally only do one thing at a time.Now suppose you're a scientist charged with forecasting the weather, testing a new cancer drug, or modeling how the climate might be in 2050. Problems like that push even the world's best computers to the limit. Just like you can upgrade a desktop PC with a better processor and more memory, so you can do the same with a world-class computer. But there's still a limit to how fast a processor will work and there's only so much difference more memory will make. The best way to make a difference is to use parallel processing: add more processors, split your problem into chunks, and get each processor working on a separate chunk of your problem in parallel.
Massively parallel computers
Once computer scientists had figured out the basic idea of parallel processing, it made sense to add more and more processors: why have a computer with two or three processors when you can have one with hundreds or even thousands? Since the 1990s, supercomputers have routinely used many thousands of processors in what's known as massively parallel processing; at the time I'm writing this, in February 2012, the world's fastest supercomputer, Fujitsu K, has over 88,000 eight-core processors (individual processor units with what are effectively eight separate processors inside them), which means 705,204 processors in total!Unfortunately, parallel processing comes with a built-in drawback. Let's go back to the supermarket analogy. If you and your friends decide to split up your shopping to go through multiple checkouts at once, the time you save by doing this is obviously reduced by the time it takes you to go your separate ways, figure out who's going to buy what, and come together again at the end. We can guess, intuitively, that the more processors there are in a supercomputer, the harder it will probably be to break up problems and reassemble them to make maximum efficient use of parallel processing. Moreover, there will need to be some sort of centralized management system or coordinator to split the problems, allocate and control the workload between all the different processors, and reassemble the results, which will also carry an overhead.
With a simple problem like paying for a cart of shopping, that's not really an issue. But imagine if your cart contains a billion items and you have 65,000 friends helping you with the checkout. If you have a problem (like forecasting the world's weather for next week) that seems to split neatly into separate sub-problems (making forecasts for each separate country), that's one thing. Computer scientists refer to complex problems like this, which can be split up easily into independent pieces, as embarrassingly parallel computations (EPC)—because they are trivially easy to divide.
But most problems don't cleave neatly that way. The weather in one country depends to a great extent on the weather in other places, so making a forecast for one country will need to take account of forecasts elsewhere. Often, the parallel processors in a supercomputer will need to communicate with one another as they solve their own bits of the problems. Or one processor might have to wait for results from another before it can do a particular job. A typical problem worked on by a massively parallel computer will thus fall somewhere between the two extremes of a completely serial problem (where every single step has to be done in an exact sequence) and an embarrassingly parallel one; while some parts can be solved in parallel, other parts will need to be solved in a serial way. A law of computing (known as Amdahl's law, for computer pioneer Gene Amdahl), explains how the part of the problem that remains serial effectively determines the maximum improvement in speed you can get from using a parallel system.
Clusters
You can make a supercomputer by filling a giant box with processors and getting them to cooperate on tackling a complex problem through massively parallel processing. Alternatively, you could just buy a load of off-the-shelf PCs, put them in the same room, and interconnect them using a very fast local area network (LAN) so they work in a broadly similar way. That kind of supercomputer is called a cluster. Google does its web searches for users with clusters of off-the-shelf computers dotted in data centers around the world.
Photo: Supercomputer cluster:NASA's Pleiades ICE Supercomputer is a cluster of 112,896 cores made from 185 racks of Silicon Graphics (SGI) workstations. Picture by Dominic Hart courtesy of NASA Ames Research Center.
Grids
A grid is a supercomputer similar to a cluster (in that it's made up of separate computers), but the computers are in different places and connected through the Internet (or other computer networks). This is an example of distributed computing, which means that the power of a computer is spread across multiple locations instead of being located in one, single place (that's sometimes called centralized computing).Grid super computing comes in two main flavors. In one kind, we might have, say, a dozen powerful mainframe computers in universities linked together by a network to form a supercomputer grid. Not all the computers will be actively working in the grid all the time, but generally we know which computers make up the network. The CERN Worldwide LHC Computing Grid, assembled to process data from the LHC (Large Hadron Collider) particle accelerator, is an example of this kind of system. It consists of two tiers of computer systems, with 11 major (tier-1) computer centers linked directly to the CERN laboratory by private networks, which are themselves linked to 160 smaller (tier-2) computer centers around the world (mostly in universities and other research centers), using a combination of the Internet and private networks.
The other kind of grid is much more ad-hoc and informal and involves far more individual computers—typically ordinary home computers. Have you ever taken part in an online computing project such as SETI@home, GIMPS, FightAIDS@home, Folding@home, MilkyWay@home, or ClimatePrediction.net? If so, you've allowed your computer to be used as part of an informal, ad-hoc supercomputer grid. This kind of approach is called opportunistic supercomputing, because it takes advantage of whatever computers just happen to be available at the time. Grids like this, which are linked using the Internet, are best for solving embarrassingly parallel problems that easily break up into completely independent chunks.
Hot stuff!

Photo: A Cray-2 supercomputer (left), photographed at NASA in 1989, with its own personal Fluorinert cooling tower (right). State of the art in the mid-1980s, this particular machine could perform a half-billion calculations per second. Picture courtesy of NASA Image Exchange (NIX).
If you routinely use a laptop (and sit it on your lap, rather than on a desk), you'll have noticed how hot it gets. That's because almost all the electical energy that feeds in through the power cable is ultimately converted to heat energy. And it's why most computers need a cooling system of some kind, from a simple fan whirring away inside the case (in a home PC) to giant air-conditioning units (in large mainframes).
Overheating (or cooling, if you prefer) is a major issue for supercomputers. The early Cray supercomputers had elaborate cooling systems—and the famous Cray-2 even had its own separate cooling tower, which pumped a kind of cooling "blood" (Fluorinert™) around the cases to stop them overheating.
Modern supercomputers tend to be either air-cooled (with fans) or liquid cooled (with a coolant circulated in a similar way to refrigeration). Either way, cooling systems translate into very high energy use and very expensive electricity bills; they're also very bad environmentally. Some supercomputers deliberately trade off a little performance to reduce their energy consumption and cooling needs and achieve lower environmental impact.
What software do supercomputers run?
You might be surprised to discover that most supercomputers run fairly ordinary operating systems much like the ones running on your own PC, although that's less surprising when we remember that a lot of modern supercomputers are actually clusters of off-the-shelf computers or workstations. The most common supercomputer operating system used to be Unix, but it's now been superseded by Linux (an open-source, Unix-like operating system originally developed by Linus Torvalds and thousands of volunteers). Since supercomputers generally work on scientific problems, their application programs are sometimes written in traditional scientific programming languages such as Fortran, as well as popular, more modern languages such as C and C++.What do supercomputers actually do?

Photo: Supercomputers can help us crack the most complex scientific problems, including modeling Earth's climate. Picture courtesy of NASA on the Commons.
As we saw at the start of this article, one essential feature of a computer is that it's a general-purpose machine you can use in all kinds of different ways: you can send emails on a computer, play games, edit photos, or do any number of other things simply by running a different program. If you're using a high-end cellphone, such as an Android phone or an iPhone or an iPod Touch, what you have is a powerful little pocket computer that can run programs by loading different "apps" (applications), which are simply computer programs by another name. Supercomputers are slightly different.
Typically, supercomputers have been used for complex, mathematically intensive scientific problems, including simulating nuclear missile tests, forecasting the weather, simulating the climate, and testing the strength of encryption (computer security codes). In theory, a general-purpose supercomputer can be used for absolutely anything.
While some supercomputers are general-purpose machines that can be used for a wide variety of different scientific problems, some are engineered to do very specific jobs. Two of the most famous supercomputers of recent times were engineered this way. IBM's Deep Blue machine from 1997 was built specifically to play chess (against Russian grand master Gary Kasparov), while its later Watson machine (named for IBM's founder, Thomas Watson, and his son) was engineered to play the game Jeopardy. Specially designed machines like this can be optimized for particular problems; so, for example, Deep Blue would have been designed to search through huge databases of potential chess moves and evaluate which move was best in a particular situation, while Watson was optimized to analyze tricky general-knowledge questions phrased in (natural) human language.
How powerful are supercomputers?
Look through the specifications of ordinary computers and you'll find their performance is usually quoted in MIPS (million instructions per second), which is how many fundamental programming commands (read, write, store, and so on) the processor can manage. It's easy to compare two PCs by comparing the number of MIPS they can handle (or even their processor speed, which is typically rated in gigahertz or GHz).Supercomputers are rated a different way. Since they're employed in scientific calculations, they're measured according to how many floating point operations per second (FLOPS) they can do, which is a more meaningful measurement based on what they're actually trying to do (unlike MIPS, which is a measurement of how they are trying to do it). Since supercomputers were first developed, their performance has been measured in successively greater numbers of FLOPS, as the table below illustrates:
| Unit | FLOPS | Example | Decade |
|---|---|---|---|
| Hundred FLOPS | 100 = 102 | Eniac | ~1940s |
| KFLOPS (kiloflops) | 1 000 = 103 | IBM 704 | ~1950s |
| MFLOPS (megaflops) | 1 000 000 = 106 | CDC 6600 | ~1960s |
| GFLOPS (gigaflops) | 1 000 000 000 = 109 | Cray-2 | ~1980s |
| TFLOPS (teraflops) | 1 000 000 000 000 = 1012 | ASCI Red | ~1990s |
| PFLOPS (petaflops) | 1 000 000 000 000 000 = 1015 | Jaguar | ~2010s |
| EFLOPS (exaflops) | 1 000 000 000 000 000 000 = 1018 | ????? | ~2020s |
Who invented supercomputers? A supercomputer timeline!
Study the history of computers and you'll notice something straight away: no single individual can lay claim to inventing these amazing machines. Arguably, that's much less true of supercomputers, which are widely acknowledged to owe a huge debt to the work of a single man, Seymour Cray (1925–1996). Here's a whistle stop tour of supercomputing, BC and AC—before and after Cray!

Photo: The distinctive C-shaped processor unit of a Cray-2 supercomputer. Picture courtesy of NASA Image Exchange (NIX).
- 1946: John Mauchly and J. Presper Eckert construct ENIAC (Electronic Numerical Integrator And Computer) at the University of Pennsylvania. The first general-purpose, electronic computer, it's about 25m (80 feet) long and weighs 30 tons and, since it's deployed on military-scientific problems, is arguably the very first scientific supercomputer.
- 1953: IBM develops its first general-purpose mainframe computer, the IBM 701 (also known as the Defense Calculator), and sells about 20 of the machines to a variety of government and military agencies. The 701 is arguably the first off-the-shelf supercomputer. IBM engineer Gene Amdahl later redesigns the machine to make the IBM 704, a machine capable of 5 KFLOPS (5000 FLOPS).
- 1956: IBM develops the Stretch supercomputer for Los Alamos National Laboratory. It remains the world's fastest computer until 1964.
- 1957: Seymour Cray co-founds Control Data Corporation (CDC) and pioneers fast, transistorized, high-performance computers, including the CDC 1604 (announced 1958) and 6600 (released 1964), which seriously challenge IBM's dominance of mainframe computing.
- 1972: Cray leaves Control Data and founds Cray Research to develop high-end computers—the first true supercomputers. One of his key ideas is to reduce the length of the connections between components inside his machines to help make them faster. This is partly why early Cray computers are C-shaped, although the unusual circular design (and bright blue or red cabinets) also helps to distinguish them from competitors.
- 1976: First Cray-1 supercomputer is installed at Los Alamos National Laboratory. It manages a speed of about 160 MFLOPS.
- 1979: Cray develops an ever faster model, the eight-processor, 1.9 GFLOP Cray-2. Where wire connections in the Cray-1 were a maximum of 120cm (~4 ft) long, in the Cray-2 they are a mere 41cm (16 inches).
- 1983: Thinking Machines Corporation unveils the massively parallel Connection Machine, with 64,000 parallel processors.
- 1989: Seymour Cray starts a new company, Cray Computer, where he develops the Cray-3 and Cray-4.
- 1990s: Cuts in defense spending and the rise of powerful RISC workstations, made by companies such as Silicon Graphics, pose a serious threat to the financial viability of supercomputer makers.
- 1993: Fujitsu Numerical Wind Tunnel becomes the world's fastest computer using 166 vector processors.
- 1994: Thinking Machines files for bankruptcy protection.
- 1995: Cray Computer runs into financial difficulties and files for bankruptcy protection. Tragically, Seymour Cray dies on October 5, 1996, after sustaining injuries in a car accident.
- 1996: Cray Research (Cray's original company) is purchased by Silicon Graphics.
- 1997: ASCI Red, a supercomputer made from Pentium processors by Intel and Sandia National Laboratories, becomes the world's first teraflop (TFLOP) supercomputer.
- 1997: IBM's Deep Blue supercomputer beats Gary Kasparov at chess.
- 2008: The Jaguar supercomputer built by Cray Research and Oak Ridge National Laboratory becomes the world's first petaflop (PFLOP) scientific supercomputer. Briefly the world's fastest computer, it is soon superseded by machines from Japan and China.
- 2011–2013: Jaguar is extensively (and expensively) upgraded, renamed Titan, and briefly becomes the world's fastest supercomputer before losing the top slot to the Chinese machine Tianhe-2.
- 2014: Mont-Blanc, a European consortium, announces plans to build an exaflop (1018 FLOP) supercomputer from energy efficient smartphone and tablet processors.
- 2016: China and the United States continue to dominate the TOP500 ranking of the world's fastest supercomputers, with 171 machines each. The Sunway TaihuLight remains the world's most powerful machine.
- 2017: Chinese scientists announce they will soon unveil the prototype of an exaflop supercomputer, expected to be based on Tianhe-2.
Y . I/O IIIIIIIII Virtual reality

You'll probably never go to Mars, swim with dolphins, run an Olympic 100 meters, or sing onstage with the Rolling Stones. But if virtual reality ever lives up to its promise, you might be able to do all these things—and many more—without even leaving your home. Unlike real reality (the actual world in which we live), virtual reality means simulating bits of our world (or completely imaginary worlds) using high-performance computers and sensory equipment, like headsets and gloves. Apart from games and entertainment, it's long been used for training airline pilots and surgeons and for helping scientists to figure out complex problems such as the structure of protein molecules. How does it work? Let's take a closer look!
Photo: Virtual reality means blocking yourself off from the real world and substituting a computer-generated alternative. Often, it involves wearing a wraparound headset called a head-mounted display, clamping stereo headphones over your ears, and touching or feeling your way around your imaginary home using datagloves (gloves with built-in sensors). Picture by Wade Sisler courtesy of NASA Ames Research Center.
What is virtual reality?
Virtual reality (VR) means experiencing things through our computers that don't really exist. From that simple definition, the idea doesn't sound especially new. When you look at an amazing Canaletto painting, for example, you're experiencing the sites and sounds of Italy as it was about 250 years ago—so that's a kind of virtual reality. In the same way, if you listen to ambient instrumental or classical music with your eyes closed, and start dreaming about things, isn't that an example of virtual reality—an experience of a world that doesn't really exist? What about losing yourself in a book or a movie? Surely that's a kind of virtual reality?If we're going to understand why books, movies, paintings, and pieces of music aren't the same thing as virtual reality, we need to define VR fairly clearly. For the purposes of this simple, introductory article, I'm going to define it as:
A believable, interactive 3D computer-created world that you can explore so you feel you really are there, both mentally and physically.Putting it another way, virtual reality is essentially:
- Believable: You really need to feel like you're in your virtual world (on Mars, or wherever) and to keep believing that, or the illusion of virtual reality will disappear.
- Interactive: As you move around, the VR world needs to move with you. You can watch a 3D movie and be transported up to the Moon or down to the seabed—but it's not interactive in any sense.
- Computer-generated: Why is that important? Because only powerful machines, with realistic 3D computer graphics, are fast enough to make believable, interactive, alternative worlds that change in real-time as we move around them.
- Explorable: A VR world needs to be big and detailed enough for you to explore. However realistic a painting is, it shows only one scene, from one perspective. A book can describe a vast and complex "virtual world," but you can only really explore it in a linear way, exactly as the author describes it.
- Immersive: To be both believable and interactive, VR needs to engage both your body and your mind. Paintings by war artists can give us glimpses of conflict, but they can never fully convey the sight, sound, smell, taste, and feel of battle. You can play a flight simulator game on your home PC and be lost in a very realistic, interactive experience for hours (the landscape will constantly change as your plane flies through it), but it's not like using a real flight simulator (where you sit in a hydraulically operated mockup of a real cockpit and feel actual forces as it tips and tilts), and even less like flying a plane.

Artwork: This Canaletto painting of Venice, Italy is believable and in some sense explorable (you can move your eyes around and think about different parts of the picture), but it's not interactive, computer-generated, or immersive, so it doesn't meet our definition of virtual reality: looking at this picture is not like being there. There's nothing to stop us making an explorable equivalent in VR, but we need CGI—not oil paints—to do it. Picture courtesy of Wikimedia Commons.
We can see from this why reading a book, looking at a painting, listening to a classical symphony, or watching a movie don't qualify as virtual reality. All of them offer partial glimpses of another reality, but none are interactive, explorable, or fully believable. If you're sitting in a movie theater looking at a giant picture of Mars on the screen, and you suddenly turn your head too far, you'll see and remember that you're actually on Earth and the illusion will disappear. If you see something interesting on the screen, you can't reach out and touch it or walk towards it; again, the illusion will simply disappear. So these forms of entertainment are essentially passive: however plausible they might be, they don't actively engage you in any way.
VR is quite different. It makes you think you are actually living inside a completely believable virtual world (one in which, to use the technical jargon, you are partly or fully immersed). It is two-way interactive: as you respond to what you see, what you see responds to you: if you turn your head around, what you see or hear in VR changes to match your new perspective.
Types of virtual reality
"Virtual reality" has often been used as a marketing buzzword for compelling, interactive video games or even 3D movies and television programs, none of which really count as VR because they don't immerse you either fully or partially in a virtual world. Search for "virtual reality" in your cellphone app store and you'll find hundreds of hits, even though a tiny cellphone screen could never get anywhere near producing the convincing experience of VR. Nevertheless, things like interactive games and computer simulations would certainly meet parts of our definition up above, so there's clearly more than one approach to building virtual worlds—and more than one flavor of virtual reality. Here are a few of the bigger variations:Fully immersive
For the complete VR experience, we need three things. First, a plausible, and richly detailed virtual world to explore; a computer model or simulation, in other words. Second, a powerful computer that can detect what we're going and adjust our experience accordingly, in real time (so what we see or hear changes as fast as we move—just like in real reality). Third, hardware linked to the computer that fully immerses us in the virtual world as we roam around. Usually, we'd need to put on what's called a head-mounted display (HMD) with two screens and stereo sound, and wear one or more sensory gloves. Alternatively, we could move around inside a room, fitted out with surround-sound loudspeakers, onto which changing images are projected from outside. We'll explore VR equipment in more detail in a moment.Non-immersive
A highly realistic flight simulator on a home PC might qualify as nonimmersive virtual reality, especially if it uses a very wide screen, with headphones or surround sound, and a realistic joystick and other controls. Not everyone wants or needs to be fully immersed in an alternative reality. An architect might build a detailed 3D model of a new building to show to clients that can be explored on a desktop computer by moving a mouse. Most people would classify that as a kind of virtual reality, even if it doesn't fully immerse you. In the same way, computer archaeologists often create engaging 3D reconstructions of long-lost settlements that you can move around and explore. They don't take you back hundreds or thousands of years or create the sounds, smells, and tastes of prehistory, but they give a much richer experience than a few pastel drawings or even an animated movie.Collaborative
What about "virtual world" games like Second Life and Minecraft? Do they count as virtual reality? Although they meet the first four of our criteria (believable, interactive, computer-created and explorable), they don't really meet the fifth: they don't fully immerse you. But one thing they do offer that cutting-edge VR typically doesn't is collaboration: the idea of sharing an experience in a virtual world with other people, often in real time or something very close to it. Collaboration and sharing are likely to become increasingly important features of VR in future.Web-based
Virtual reality was one of the hottest, fastest-growing technologies in the late 1980s and early 1990s, but the rapid rise of the World Wide Web largely killed off interest after that. Even though computer scientists developed a way of building virtual worlds on the Web (using a technology analogous to HTML called Virtual Reality Markup Language, VRML), ordinary people were much more interested in the way the Web gave them new ways to access real reality—new ways to find and publish information, shop, and share thoughts, ideas, and experiences with friends through social media. With Facebook's growing interest in the technology, the future of VR seems likely to be both Web-based and collaborative.Augmented reality

Photo: Augmented reality: A heads-up display, like this one used by the US Air Force, superimposes useful, computer-based information on top of the things you see with your own eyes. Picture by Major Chad E. Gibson courtesy of US Air Force.
Mobile devices like smartphones and tablets have put what used to be supercomputer power in our hands and pockets. If we're wandering round the world, maybe visiting a heritage site like the pyramids or a fascinating foreign city we've never been to before, what we want is typically not virtual reality but an enhanced experience of the exciting reality we can see in front of us. That's spawned the idea of augmented reality (AR), where, for example, you point your smartphone at a landmark or a striking building and interesting information about it pops up automatically. Augmented reality is all about connecting the real world we experience to the vast virtual world of information that we've collectively created on the Web. Neither of these worlds is virtual, but the idea of exploring and navigating the two simultaneously does, nevertheless, have things in common with virtual reality. For example, how can a mobile device figure out its precise location in the world? How do the things you see on the screen of your tablet change as you wander round a city? Technically, these problems are similar to the ones developers of VR systems have to solve—so there are close links between AR and VR.
What equipment do we need for virtual reality?
Close your eyes and think of virtual reality and you probably picture something like our top photo: a geek wearing a wraparound headset (HMD) and datagloves, wired into a powerful workstation or supercomputer. What differentiates VR from an ordinary computer experience (using your PC to write an essay or play games) is the nature of the input and output. Where an ordinary computer uses things like a keyboard, mouse, or (more exotically) speech recognition for input, VR uses sensors that detect how your body is moving. And where a PC displays output on a screen (or a printer), VR uses two screens (one for each eye), stereo or surround-sound speakers, and maybe some forms of haptic (touch and body perception) feedback as well. Let's take a quick tour through some of the more common VR input and output devices.Head-mounted displays (HMDs)

Photo: The view from inside. A typical HMD has two tiny screens that show different pictures to each of your eyes, so your brain produces a combined 3D (stereoscopic) image. Picture by courtesy of US Air Force.
There are two big differences between VR and looking at an ordinary computer screen: in VR, you see a 3D image that changes smoothly, in real-time, as you move your head. That's made possible by wearing a head-mounted display, which looks like a giant motorbike helmet or welding visor, but consists of two small screens (one in front of each eye), a blackout blindfold that blocks out all other light (eliminating distractions from the real world), and stereo headphones. The two screens display slightly different, stereoscopic images, creating a realistic 3D perspective of the virtual world. HMDs usually also have built-in accelerometers or position sensors so they can detect exactly how your head and body are moving (both position and orientation—which way they're tilting or pointing) and adjust the picture accordingly. The trouble with HMDs is that they're quite heavy, so they can be tiring to wear for long periods; some of the really heavy ones are even mounted on stands with counterweights. But HMDs don't have to be so elaborate and sophisticated: at the opposite end of the spectrum, Google has developed an affordable, low-cost pair of cardboard goggles with built-in lenses that convert an ordinary smartphone into a crude HMD.
Immersive rooms
An alternative to putting on an HMD is to sit or stand inside a room onto whose walls changing images are projected from outside. As you move in the room, the images change accordingly. Flight simulators use this technique, often with images of landscapes, cities, and airport approaches projected onto large screens positioned just outside a mockup of a cockpit. A famous 1990s VR experiment called CAVE (Cave Automatic Virtual Environment), developed at the University of Illinois by Thomas de Fanti, also worked this way. People moved around inside a large cube-shaped room with semi-transparent walls onto which stereo images were back-projected from outside. Although they didn't have to wear HMDs, they did need stereo glasses to experience full 3D perception.Datagloves
See something amazing and your natural instinct is to reach out and touch it—even babies do that. So giving people the ability to handle virtual objects has always been a big part of VR. Usually, this is done using datagloves, which are ordinary gloves with sensors wired to the outside to detect hand and figure motions. One technical method of doing this uses fiber-optic cables stretched the length of each finger. Each cable has tiny cuts in it so, as you flex your fingers back and forth, more or less light escapes. A photocell at the end of the cable measures how much light reaches it and the computer uses this to figure out exactly what your fingers are doing. Other gloves use strain gauges, piezoelectric sensors, or electromechanical devices (such as potentiometers) to measure finger movements.

Photos: Left/above: EXOS datagloves produced by NASA in the 1990s had very intricate external sensors to detect finger movements with high precision. Picture courtesy of NASA Marshall Space Flight Center (NASA-MSFC). Right/below: This more elaborate EXOS glove had separate sensors on each finger segment, wired up to a single ribbon cable connected up to the main VR computer. Picture by Wade Sisler courtesy of NASA Ames Research Center.
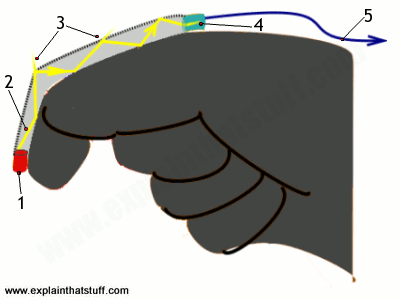
Artwork: How a fiber-optic dataglove works. Each finger has a fiber-optic cable stretched along its length. (1) At one end of the finger, a light-emitting diode (LED) shines light into the cable. (2) Light rays shoot down the cable, bouncing off the sides. (3) There are tiny abrasions in the top of each fiber through which some of the rays escape. The more you flex your fingers, the more light escapes. (4) The amount of light arriving at a photocell at the end gives a rough indication of how much you're flexing your finger. (5) A cable carries this signal off to the VR computer. This is a simplified version of the kind of dataglove VPL patented in 1992, and you'll find the idea described in much more detail in US Patent 5,097,252.
Wands
Even simpler than a dataglove, a wand is a stick you can use to touch, point to, or otherwise interact with a virtual world. It has position or motion sensors (such as accelerometers) built in, along with mouse-like buttons or scroll wheels. Originally, wands were clumsily wired into the main VR computer; increasingly, they're wireless.
Photo: A typical handheld virtual reality controller (complete with elastic bands), looking not so different from a video game controller. Photo courtesy of NASA Ames Research Center.
Applications of virtual reality
VR has always suffered from the perception that it's little more than a glorified arcade game—literally a "dreamy escape" from reality. In that sense, "virtual reality" can be an unhelpful misnomer; "alternative reality," "artificial reality," or "computer simulation" might be better terms. The key thing to remember about VR is that it really isn't a fad or fantasy waiting in the wings to whistle people off to alternative worlds; it's a hard-edged practical technology that's been routinely used by scientists, doctors, dentists, engineers, architects, archaeologists, and the military for about the last 30 years. What sorts of things can we do with it?Education

Photo: Flight training is a classic application of virtual reality, though it doesn't use HMDs or datagloves. Instead, you sit in a pretend cockpit with changing images projected onto giant screens to give an impression of the view you'd see from your plane. The cockpit is a meticulous replica of the one in a real airplane with exactly the same instruments and controls. Photo by Javier Garcia courtesy of US Air Force.
Difficult and dangerous jobs are hard to train for. How can you safely practice taking a trip to space, landing a jumbo jet, making a parachute jump, or carrying out brain surgery? All these things are obvious candidates for virtual reality applications. As we've seen already, flight cockpit simulators were among the earliest VR applications; they can trace their history back to mechanical simulators developed by Edwin Link in the 1920s. Just like pilots, surgeons are now routinely trained using VR. In a 2008 study of 735 surgical trainees from 28 different countries, 68 percent said the opportunity to train with VR was "good" or "excellent" for them and only 2 percent rated it useless or unsuitable.
Scientific visualization
Anything that happens at the atomic or molecular scale is effectively invisible unless you're prepared to sit with your eyes glued to an electron microscope. But suppose you want to design new materials or drugs and you want to experiment with the molecular equivalent of LEGO. That's another obvious application for virtual reality. Instead of wrestling with numbers, equations, or two-dimensional drawings of molecular structures, you can snap complex molecules together right before your eyes. This kind of work began in the 1960s at the University of North Carolina at Chapel Hill, where Frederick Brooks launched GROPE, a project to develop a VR system for exploring the interactions between protein molecules and drugs.
Photo: If you're heading to Mars, a trip in virtual reality could help you visualize what you'll find when you get there. Picture courtesy of NASA Ames Research Center.
Medicine
Apart from its use in things like surgical training and drug design, virtual reality also makes possible telemedicine (monitoring, examining, or operating on patients remotely). A logical extension of this has a surgeon in one location hooked up to a virtual reality control panel and a robot in another location (maybe an entire continent away) wielding the knife. The best-known example of this is the daVinci surgical robot, released in 2009, of which several thousand have now been installed in hospitals worldwide. Introduce collaboration and there's the possibility of a whole group of the world's best surgeons working together on a particularly difficult operation—a kind of WikiSurgery, if you like!Industrial design and architecture
Architects used to build models out of card and paper; now they're much more likely to build virtual reality computer models you can walk through and explore. By the same token, it's generally much cheaper to design cars, airplanes, and other complex, expensive vehicles on a computer screen than to model them in wood, plastic, or other real-world materials. This is an area where virtual reality overlaps with computer modeling: instead of simply making an immersive 3D visual model for people to inspect and explore, you're creating a mathematical model that can be tested for its aerodynamic, safety, or other qualities.Games and entertainment
From flight simulators to race-car games, VR has long hovered on the edges of the gaming world—never quite good enough to revolutionize the experience of gamers, largely due to computers being too slow, displays lacking full 3D, and the lack of decent HMDs and datagloves. All that may be about to change with the development of affordable new peripherals like the Oculus Rift.Pros and cons of virtual reality
Like any technology, virtual reality has both good and bad points. How many of us would rather have a complex brain operation carried out by a surgeon trained in VR, compared to someone who has merely read books or watched over the shoulders of their peers? How many of us would rather practice our driving on a car simulator before we set foot on the road? Or sit back and relax in a Jumbo Jet, confident in the knowledge that our pilot practiced landing at this very airport, dozens of times, in a VR simulator before she ever set foot in a real cockpit?Critics always raise the risk that people may be seduced by alternative realities to the point of neglecting their real-world lives—but that criticism has been leveled at everything from radio and TV to computer games and the Internet. And, at some point, it becomes a philosophical and ethical question: What is real anyway? And who is to say which is the better way to pass your time? Like many technologies, VR takes little or nothing away from the real world: you don't have to use it if you don't want to.
The promise of VR has loomed large over the world of computing for at least the last quarter century—but remains largely unfulfilled. While science, architecture, medicine, and the military all rely on VR technology in different ways, mainstream adoption remains virtually nonexistent; we're not routinely using VR the way we use computers, smartphones, or the Internet. But the 2014 acquisition of VR company Oculus, by Facebook, greatly renewed interest in the area and could change everything. Facebook's basic idea is to let people share things with their friends using the Internet and the Web. What if you could share not simply a photo or a link to a Web article but an entire experience? Instead of sharing photos of your wedding with your Facebook friends, what if you could make it possible for people to attend your wedding remotely, in virtual reality, in perpetuity? What if we could record historical events in such a way that people could experience them again and again, forever more? These are the sorts of social, collaborative virtual reality sharing that (we might guess) Facebook is thinking about exploring right now. If so, the future of virtual reality looks very bright indeed!
A brief history of virtual reality
So much for the future, but what of the past. Virtual reality has a long and very rich history. Here are a few of the more interesting highlights...
Artwork: The first virtual reality machine? Morton Heilig's 1962 Sensorama. Picture courtesy US Patent and Trademark Office.
- 1890s: Thomas Edison and his assistant William Dickson pioneer the Kinetograph (a camera for recording pictures) and Kinetoscope (a projector for playing them back)—in effect, the first one-person "movie experience."
- 1895: French brothers Auguste and Louis Lumière open the first movie theater in Paris, France. Legend has it that one of their movie shorts, Arrival of a Train at La Ciotat, is such a convincing depiction of reality that people in the audience scream and run to the back of the room.
- 1929: Edwin Link develops the Link Trainer (also called the Pilot Maker), a mechanical airplane simulator. His work pioneers the field of flight simulation.
- 1950: US Air Force psychologist James J. Gibson publishes an influential book, The Perception of the Visual World, describing how people see and experience things as an "optic flow" as they move through the world. These ideas, and those of contemporaries such as Adelbert Ames, help to form the foundations of the 20th century psychology of visual perception, which feeds into academic studies of computer vision and virtual reality.
- 1956: Cinematographer Morton Heilig begins developing machines that can produce artificial sensory experiences. In 1957, he develops a pioneering 3D head-mounted display. In 1962, he's granted a patent for a machine called the Sensorama (a kind of updated, highly sophisticated Kinetoscope) that can immerse its user in artificial vision, sound, smell, and vibration. Many people regard Heilig as the true father of virtual reality, though he has seldom been acknowledged as such.
- 1961: C. Comeau and J. Bryan make Headsight, the first real head-mounted display.
- 1962: Ivan Sutherland, pioneer of human-computer interaction, develops the lightpen and a program called Sketchpad that allows people to draw on a computer screen—opening the way for the kind of computer graphics later used in virtual reality.
- 1965: Sutherland develops Ultimate Display, a sophisticated HMD.
- 1968. Sutherland produces a HMD with stereo (3D) vision.
- 1970s: Computer scientist Myron Krueger opens Videoplace, a pioneering VR laboratory.
- 1975-1976: Programmer Will Crowther develops Adventure (also called Colossal Cave Adventure), a highly influential, text-based computer game in which players explore a virtual world, solving problems through a question and answer dialog.
- 1977: Dan Sandin, Richard Sayre, and Thomas Defanti produce the first dataglove.
- 1980s: Fast 3D graphical workstations, notably those developed by Silicon Graphics, accelerate the development of scientific visualization, visual computer modeling, CGI movies, and VR.
- 1982: Tron, a pioneering CGI movie, tells the story of a software engineer (played by actor Jeff Bridges) who ventures into the software of a mainframe computer.
- 1983: Computer scientist Myron Krueger coins the term "artificial reality."
- 1983: Writer William Gibson invents the related term "cyberspace."
- 1989: Computer scientist and musician Jaron Lanier: coins the now preferred term "virtual reality." His company, VPL Research, garners huge media attention and develops pioneering VR peripherals, including a HMD and dataglove. Lanier has been popularly referred to as the "father of virtual reality" ever since, though, as this timeline demonstrates, he was quite a late entrant to the field!
- 1992: The Lawnmower Man, another influential VR film, based on a Stephen King story, is partly inspired by the story of VPL.
- 1993: Brothers Robyn and Rand Miller create Myst, an extremely successful graphical computer game, in which players explore an island in non-immersive virtual reality.
- 1994: Dave Raggett, an influential English computer scientist who has played a key role in the development of the World Wide Web, coins the term VRML (Virtual Reality Markup Language).
- 1999: The Matrix, a movie starring Keanu Reaves based on virtual reality, grosses over $450 million at the box office.
- 2011: Palmer Luckey develops the Oculus Rift, an inexpensive homemade HMD, in his parents' garage.
- 2014: Facebook announces its acquisition of Oculus in a deal worth $2 billion.
- 2016: Oculus begins shipping its Rift headsets to customers to generally positive reviews. Meanwhile, a variety of smartphone makers (including Samsung and HTC) produce rival VR systems, VR also appears for PlayStation, and Google announces it has shipped over 5 million cardboard head-mounted displays for smartphones.
- 2017: Sony reveals that it sold almost a million PlayStation VR headsets in their first four months on the market.
Y . I/O IIIIIIIIIII Computer graphics

If Rembrandt were alive today, would he still paint with oil on canvas... or sit calmly at a desk, hand on mouse, and draw dazzling graphics on a computer screen? Most of us would happily admit to having less talent in both hands than a great painter like this had in a millimeter of his pinkie, but computers can turn us into reasonably competent, everyday artists all the same. Whether you're an architect or a web designer, a fashion student or a scientist, computer graphics can make your work quicker, easier, and much more effective. How? Let's take a closer look!
Photo: Computer graphics, early 1980s style! Arcade games like Space Invaders were how most 30- and 40-something computer geeks first experienced computer graphics. At that time, even good computer screens could display only about 64,000 pixels—hence the relatively crudely drawn, pixelated graphics.
What is computer graphics?

Photo: Oil paints like these can produce magical results in the right hands—but only in the right hands. Thankfully, those of us without the talent and skill to use them can still produce decent everyday art with computer graphics.
Computer graphics means drawing pictures on a computer screen. What's so good about that? Sketch something on paper—a man or a house—and what you have is a piece of analog information: the thing you draw is a likeness or analogy of something in the real world. Depending on the materials you use, changing what you draw can be easy or hard: you can erase pencil or charcoal marks easily enough, and you can scrape off oil paints and redo them with no trouble; but altering watercolors or permanent markers is an awful lot more tricky. That's the wonder of art, of course—it captures the fresh dash of creativity—and that's exactly what we love about it. But where everyday graphics is concerned, the immediacy of art is also a huge drawback. As every sketching child knows too well, if you draw the first part of your picture too big, you'll struggle to squeeze everything else on the page.... and what if you change your mind about where to put something or you want to swap red for orange or green for blue? Ever had one of those days where you rip up sheet after sheet of spoiled paper and toss it in the trash?
That's why many artists, designers, and architects have fallen in love with computer graphics. Draw a picture on a computer screen and what you have is a piece of digital information. It probably looks similar to what you'd have drawn on paper—the ghostly idea that was hovering in your mind's eye to begin with—but inside the computer your picture is stored as a series of numbers. Change the numbers and you can change the picture, in the blink of an eye or even quicker. It's easy to shift your picture around the screen, scale it up or down, rotate it, swap the colors, and transform it in all kinds of other ways. Once it's finished, you can save it, incorporate it into a text document, print it out, upload it to a web page, or email it to a client or work colleague—all because it's digital information. (Find out more about the benefits of digital in our main article about analog and digital.)
Raster and vector graphics
All computer art is digital, but there are two very different ways of drawing digital images on a computer screen, known as raster and vector graphics. Simple computer graphic programs like Microsoft Paint and PaintShop Pro are based on raster graphics, while more sophisticated programs such as CorelDRAW, AutoCAD, and Adobe Illustrator use vector graphics. So what exactly is the difference?Raster graphics
Stare hard at your computer screen and you'll notice the pictures and words are made up of tiny colored dots or squares called pixels. Most of the simple computer graphic images we come across are pixelated in this way, just like walls are built out of bricks. The first computer screens, developed in the mid-20th century, worked much like televisions, which used to build up their moving pictures by "scanning" beams of electrons (tiny charged particles inside atoms, also called cathode rays) back and forth from top to bottom and left to right—like a kind of instant electronic paintbrush. This way of making a picture is called raster scanning and that's why building up a picture on a computer screen out of pixels is called raster graphics.Photo: Raster graphics: This is a closeup of the paintbrushes in the photo of the artist's paint palette up above. At this magnification, you can clearly see the individual colored pixels (squares) from which the image is built, like bricks in a wall.
Bitmaps
You've probably heard of binary, the way that computers represent decimal numbers (1,2,3,4 and so on) using just the two digits zero and one (so the decimal number 5678 becomes 1011000101110 in binary computer speak). Suppose you're a computer and you want to remember a picture someone is drawing on your screen. If it's in black and white, you could use a zero to store a white area of the picture and a one to store a black area (or vice versa if you prefer). Copying down each pixel in turn, you could transform a picture filling an entire screen of, say, 800 pixels across by 600 pixels down into a list of 480,000 (800 x 600) binary zeros and ones. This way of turning a picture into a computer file made up of binary digits (which are called bits for short) is called a bitmap, because there's a direct correspondence—a one-to-one "mapping"—between every pixel in the picture and every bit in the file. In practice, most bitmaps are of colored pictures. If we use a single bit to represent each pixel, we can only tell whether the pixel is on or off (white or black); if we use (say) eight bits to represent each pixel, we could remember eight different colors, but we'd need eight times more memory (storage space inside the computer) to store a picture the same size. The more colors we want to represent, the more bits we need.Raster graphics are simple to use and it's easy to see how programs that use them do their stuff. If you draw a pixel picture on your computer screen and you click a button in your graphics package to "mirror" the image (flip it from left to right or right to left), all the computer does is reverse the order of the pixels by reversing the sequence of zeros and ones that represent them. If you scale an image so it's twice the size, the computer copies each pixel twice over (so the numbers 10110 become 1100111100) but the image becomes noticeably more grainy and pixelated in the process. That's one of the main drawbacks of using raster graphics: they don't scale up to different sizes very well. Another drawback is the amount of memory they require. A really detailed photo might need 16 million colors, which involves storing 24 bits per pixel and 24 times as much memory as a basic black-and-white image. (Do the sums and you'll find that a picture completely filling a 1024 x 768 computer monitor and using 24 bits per pixel needs roughly 2.5 megabytes of memory.)
Photo: How a raster graphics program mirrors an image. Top: The pixels in the original image are represented by zeros and ones, with black pixels represented here by 1 and white ones represented by zero. That means the top image can be stored in the computer's memory as the binary number 100111. That's an example of a very small bitmap. Bottom: Now if you ask the computer to mirror the image, it simply reverses the order of the bits in the bitmap, left to right, giving the binary number 111001, which automatically reverses the original pattern of pixels. Other transformations of the picture, such as rotation and scaling, involve swapping the bits in more complex ways.
Resolution
The maximum number of pixels in an image (or on a computer screen) is known as its resolution. The first computer I ever used properly, a Commodore PET, had an ultra-low resolution display with 80 characters across by 25 lines down (so a maximum of 2000 letters, numbers, or punctuation marks could be on the screen at any one time); since each character was built from an 8 × 8 square of pixels, that meant the screen had a resolution of 640 × 200 = 128,000 pixels (or 0.128 Megapixels, where a Megapixel is one million pixels). The laptop I'm using right now is set to a resolution of 1280 × 800 =1.024 Megapixels, which is roughly 7–8 times more detailed. A digital camera with 7 Megapixel resolution would be roughly seven times more detailed than the resolution of my laptop screen or about 50 times more detailed than that original Commodore PET screen.Anti-aliasing
Displaying smoothly drawn curves on a pixelated display can produce horribly jagged edges ("jaggies"). One solution to this is to blur the pixels on a curve to give the appearance of a smoother line. This technique, known as anti-aliasing, is widely used to smooth the fonts on pixelated computer screens.Photo: How anti-aliasing works: Pixelated images, like the word "pixelated" shown here, are made up of individual squares or dots, which are really easy for raster graphics displays (such as LCD computer screens) to draw. I copied this image directly from the italic word "pixelated" in the text up above. If you've not altered your screen colors, the original tiny text probably looks black and very smooth to your eyes. But in this magnified image, you'll see the letters are actually very jagged and made up of many colors. If you move back from your screen, or squint at the magnified word, you'll see the pixels and colors disappear back into a smooth black-and-white image. This is an example of anti-aliasing, a technique used to make pixelated words and other shapes smoother and easier for our eyes to process.
Vector graphics
There's an alternative method of computer graphics that gets around the problems of raster graphics. Instead of building up a picture out of pixels, you draw it a bit like a child would by using simple straight and curved lines called vectors or basic shapes (circles, curves, triangles, and so on) known as primitives. With raster graphics, you make a drawing of a house by building it from hundreds, thousands, or millions of individual pixels; importantly, each pixel has no connection to any other pixel except in your brain. With vector graphics, you might draw a rectangle for the basic house, smaller rectangles for the windows and door, a cylinder for the smokestack, and a polygon for the roof. Staring at the screen, a vector-graphic house still seems to be drawn out of pixels, but now the pixels are precisely related to one another—they're points along the various lines or other shapes you've drawn. Drawing with straight lines and curves instead of individual dots means you can produce an image more quickly and store it with less information: you could describe a vector-drawn house as "two red triangles and a red rectangle (the roof) sitting on a brown rectangle (the main building)," but you couldn't summarize a pixelated image so simply. It's also much easier to scale a vector-graphic image up and down by applying mathematical formulas called algorithms that transform the vectors from which your image is drawn. That's how computer programs can scale fonts to different sizes without making them look all pixelated and grainy.
Photo: Vector graphics: Drawing with Bézier curves ("paths") in the GIMP. You simply plot two points and then bend the line running between them however you want to create any curve you like.
Most modern computer graphics packages let you draw an image using a mixture of raster or vector graphics, as you wish, because sometimes one approach works better than another—and sometimes you need to mix both types of graphics in a single image. With a graphics package such as the GIMP (GNU Image Manipulation Program), you can draw curves on screen by tracing out and then filling in "paths" (technically known as Bézier curves) before converting them into pixels ("rasterizing" them) to incorporate them into something like a bitmap image.
3D graphics
Real life isn't like a computer game or a virtual reality simulation. The very best CGI (computer-generated imagery) animations are easy to tell apart from ones made on film or video with real actors. Why is that? When we look at objects in the world around us, they don't appear to be drawn from either pixels or vectors. In the blink of an eye, our brains gather much more information from the real-world than artists can include in even the most realistic computer-graphic images. To make a computerized image look anything like as realistic as a photograph (let alone a real-world scene), we need to include far more than simply millions of colored-in pixels.Really sophisticated computer graphics programs use a whole series of techniques to make hand-drawn (and often completely imaginary) two-dimensional images look at least as realistic as photographs. The simplest way of achieving this is to rely on the same tricks that artists have always used—such things as perspective (how objects recede into the distance toward a "vanishing point" on the horizon) and hidden-surface elimination (where nearby things partly obscure ones that are further away).
If you want realistic 3D artwork for such things as CAD (computer-aided design) and virtual reality, you need much more sophisticated graphic techniques. Rather than drawing an object, you make a 3D computer model of it inside the computer and manipulate it on the screen in various ways. First, you build up a basic three-dimensional outline of the object called a wire-frame (because it's drawn from vectors that look like they could be little metal wires). Then the model is rigged, a process in which different bits of the object are linked together a bit like the bones in a skeleton so they move together in a realistic way. Finally, the object is rendered, which involves shading the outside parts with different textures (surface patterns), colors, degrees of opacity or transparency, and so on. Rendering is a hugely complex process that can take a powerful computer hours, days, or even weeks to complete. Sophisticated math is used to model how light falls on the surface, typically using either ray tracing (a relatively simple method of plotting how light bounces off the surface of shiny objects in straight lines) or radiosity (a more sophisticated method for modeling how everyday objects reflect and scatter light in duller, more complex ways).

Photo: NASA scientists think computer graphics will one day be so good that computer screens will replace the cockpit windows in airplanes. Instead of looking at a real view, the pilots will be shown a computerized image drawn from sensors that work at day or night in all weather conditions. For now, that remains a science fiction dream, because even well-drawn "3D" computer images like this are easy to tell from photographs of real-world scenes: they simply don't contain enough information to fool our amazingly fantastic eyes and brains. Photo courtesy of NASA Langley Research Center (NASA-LaRC).
What is computer graphics used for?
Photo: Computer graphics can save lives. Medical scan images are often complex computerized images built up from hundreds or thousands of detailed measurements of the human body or brain. Photo by courtesy of Warren Grant Magnuson Clinical Center (CC) and US National Institutes of Health (NIH).
Obvious uses of computer graphics include computer art, CGI films, architectural drawings, and graphic design—but there are many non-obvious uses as well and not all of them are "artistic." Scientific visualization is a way of producing graphic output from computer models so it's easier for people to understand. Computerized models of global warming produce vast tables of numbers as their output, which only a PhD in climate science could figure out; but if you produce a speeded-up animated visualization—with the Earth getting bluer as it gets colder and redder as it gets hotter—anyone can understand what's going on. Medical imaging is another good example of how graphics make computer data more meaningful. When doctors show you a brain or body scan, you're looking at a computer graphic representation drawn using vast amounts of data produced from thousands or perhaps even millions of measurements. The jaw-dropping photos beamed back from space by amazing devices like the Hubble Space Telescope are usually enhanced with the help of a type of computer graphics called image processing; that might sound complex, but it's not so very different from using a graphics package like Google Picasa or PhotoShop to touch up your holiday snaps).
And that's really the key point about computer graphics: they turn complex computer science into everyday art we can all grasp, instantly and intuitively. Back in the 1980s when I was programming a Commodore PET, the only way to get it to do anything was to type meaningless little words like PEEK and POKE onto a horribly unfriendly green and black screen. Virtually every modern computer now has what's called a GUI (graphical user interface), which means you operate the machine by pointing at things you want, clicking on them with your mouse or your finger, or dragging them around your "desktop." It makes so much more sense because we're visual creatures: something like a third of our cortex (higher brain) is given over to processing information that enters our heads through our eyes. That's why a picture really is worth a thousand words (sometimes many more) and why computers that help us visualize things with computer graphics have truly revolutionized the way we see the world.
What is computer-aided design (CAD)?

Photo: Designing a plane? CAD makes it quicker and easier to transfer what's in your mind's eye into reality. Photo by courtesy of NASA Langley Research Center (NASA-LaRC).
Computer-aided design (CAD)—designing things on a computer screen instead of on paper—might sound hi-tech and modern, but it's been in use now for over a half century. It first appeared back in 1959, when IBM and General Motors developed Design Augmented by Computers-1 (DAC-1), the first ever CAD system, for creating automobiles on a computer screen.
Drawing on a computer screen with a graphics package is a whole lot easier than sketching on paper, because you can modify your design really easily. But that's not all there is to CAD. Instead of producing a static, two-dimensional (2D) picture, usually what you create on the screen is a three-dimensional (3D) computer model, drawn using vector graphics and based on a kind of line-drawn skeleton called a wireframe, which looks a bit like an object wrapped in graph paper.
Once the outside of the model's done, you turn your attention to its inner structure. This bit is called rigging your model (also known as skeletal animation). What parts does the object contain and how do they all connect together? When you've specified both the inside and outside details, your model is pretty much complete. The final stage is called texturing, and involves figuring out what colors, surface patterns, finishes, and other details you want your object to have: think of it as a kind of elaborate, three-dimensional coloring-in. When your model is complete, you can render it: turn it into a final image. Ironically, the picture you create at this stage may look like it's simply been drawn right there on the paper: it looks exactly like any other 3D drawing. But, unlike with an ordinary drawing, it's super-easy to change things: you can modify your model in any number of different ways. The computer can rotate it through any angle, zoom in on different bits, or even help you "cutaway" certain parts (maybe to reveal the engine inside a plane) or "explode" them (show how they break into their component pieces).
What is CAD used for?
From false teeth to supercars and designer dresses to drink cartons, virtually every product we buy today is put together with the help of computer-aided design. Architects, advertising and marketing people, draftsmen, car designers, shipbuilders, and aerospace engineers—these are just some of the people who rely on CAD. Apart from being cheaper and easier than using paper, CAD designs are easy to send round the world by email (from designers in Paris to manufacturers in Singapore, perhaps). Another big advantage is that CAD drawings can be converted automatically into production instructions for industrial robots and other factory machines, which greatly reduces the overall time needed to turn new designs into finished products. Next time you buy something from a store, trace it back in your mind's eye: how did it find its way into your hand, from the head-scratching designer sitting at a computer in Manhattan to the robot-packed factory in Shanghai where it rolled off the production line? Chances are it was all done with CAD!Using CAD in architecture

Photo: Architectural models are traditionally made from paper or cardboard, but they're laborious and expensive to make, fragile and difficult to transport, and virtually impossible to modify. Computer models don't suffer from any of these drawbacks. Photo by Warren Gretz courtesy of US DOE/NREL.
Architects have always been visionaries—and they helped to pioneer the adoption of CAD technology from the mid-1980s, when easy-to-use desktop publishing computers like the Apple Mac became widely available. Before CAD came along, technical drawing, was the best solution to a maddening problem architects and engineers knew only too well: how to communicate the amazing three-dimensional constructions they could visualize in their mind's eye with clarity and precision. Even with three-dimensional drawings (such as orthographic projections), it can still be hard to get across exactly what you have in mind. What if you spent hours drawing your proposed building, airplane, or family car... only for someone to say infuriating things like: "And what does it look like from behind? How would it look from over there? What if we made that wall twice the size?" Having drawn their projections, architects would typically build little models out of paper and board, while engineers would whittle model cars and planes out of balsa wood. But even the best models can't answer "What if...?" questions.
Computer-aided design solves these problems in a particularly subtle way. It doesn't simply involve drawing 2D pictures of buildings on the screen: what you produce with CAD is effectively a computer model of your design. Once that's done, it's easy to rotate your design on-screen or change any aspect of it in a matter of moments. If you want to make a wall twice the size, click a button, drag your mouse here and there, and the computer automatically recalculates how the rest of your model needs to change to fit in. You can print out three dimensional projections of your model from any angle or you can demonstrate the 3D form to your clients on-screen, allowing them to rotate or play with the model for themselves. Some models even let you walk through them in virtual reality. CAD has revolutionized architecture not simply by removing the drudge of repetitive plan drawing and intricate model making, but by providing a tangible, digital representation of the mind's eye: what you see is—finally—what you get.
Over the last 30 years, computers have absolutely revolutionized architecture. In 2012, Architects' Journal went so far as to describe CAD as "the greatest advance in construction history."
Who invented computer graphics?
Here's a brief timeline of some key moments in the history of computer graphics. In this section, most links will take you to Wikipedia articles about the pioneering people and programs.
Photo: A NASA scientist draws a graphic image on an IBM 2250 computer screen with a light pen. This was state-of-the-art technology in 1973! Photo by courtesy of NASA Ames Research Center (NASA-ARC).
- 1951: Jay Forrester and Robert Everett of Massachusetts Institute of Technology (MIT) produce Whirlwind, a mainframe computer that can display crude images on a television monitor or VDU (visual display unit).
- 1955: Directly descended from Whirlwind, MIT's SAGE (Semi-Automatic Ground Equipment) computer uses simple vector graphics to display radar images and becomes a key part of the US missile defense system.
- 1959: General Motors and IBM develop Design Augmented by Computers-1 (DAC-1), a CAD (computer-aided design) system to help engineers design cars.
- 1961: John Whitney, Sr. uses computer graphics to design a captivating title sequence for the Alfred Hitchcock thriller Vertigo.
- 1961: MIT student Steve Russell programs Spacewar!, the first graphical computer game, on a DEC PDP-1 minicomputer.
- 1963: Ivan Sutherland, a pioneer of human-computer interaction (making computers intuitively easy for humans to use), develops Sketchpad (also called Robot Draftsman), one of the first computer-aided design packages, in which images can be drawn on the screen using a lightpen (an electronic pen/stylus wired into the computer). Later, Sutherland develops virtual reality equipment and flight simulators.
- 1965: Howard Wise holds an exhibition of computer-drawn art at his pioneering gallery in Manhattan, New York.
- 1966: NASA's Jet Propulsion Laboratory (JPL) develops an image-processing program called VICAR (Video Image Communication and Retrieval), running on IBM mainframes, to process images of the moon captured by spacecraft.
- 1970: Bézier curves are developed, soon becoming an indispensable tool in vector graphics.
- 1972: Atari releases PONG, a popular version of ping-pong (table tennis) played by one or two players on a computer screen.
- 1973: Richard Shoup produces SuperPaint, a forerunner of modern computer graphic packages, at the Xerox PARC (Palto Alto Research Center) laboratory.
- 1970s: Ivan Sutherland's student Edwin Catmull becomes one of the pioneers of 3D computer-graphic animation, later playing key roles at Lucasfilm, Pixar, and Disney.
- 1981: UK company Quantel develops Paintbox, a revolutionary computer-graphic program that allows TV producers and filmakers to edit and manipulate video images digitally.
- 1982: The movie Tron, starring Jeff Bridges, mixes live action and computer graphic imagery in a story that takes a man deep inside a computer system.
- 1980s: The appearance of the affordable, easy-to-use Apple Macintosh computer paves the way for desktop publishing (designing things on your own small office computer) with popular computer graphic packages such as Aldus PageMaker (1985) and QuarkXPress (1987).
- 1985: Microsoft releases the first version of a basic raster-graphics drawing program called MS Paint. Thanks to its stripped-down simplicity, it becomes one of the world's most popular computer art programs.
- 1990: The first version of Adobe PhotoShop (one of the world's most popular professional graphic design packages) is released. A simple, affordable home graphics program called PaintShop (later PaintShop Pro) is launched the same year.
- 1993: University of Illinois student Marc Andreessen develops Mosaic, the first web browser to show text and images side-by-side, prompting a huge explosion in interest in the Web virtually overnight.
- 1995: Toy Story, produced by Pixar Animation Studios (founded by Apple's Steve Jobs, with Ed Catmull as its chief technology officer) demonstrates the impressive possibilities of CGI graphics in moviemaking. Stunning follow-up movies from the same stable include A Bug's Life, Monsters, Inc., Finding Nemo, and The Incredibles.
- 1995: The GIMP (GNU Image Manipulation Program) is developed by University of California students Spencer Kimball and Peter Mattis.
- 1999: The World Wide Web Consortium (W3C) begins development of SVG (Scalable Vector Graphics), a way of using text-based (XML) files to provide higher-quality images on the Web. SVG images can include elements of both conventional vector and raster graphics.
- 2007: Apple launches its iPhone and iPod Touch products with touchscreen graphical user interfaces.
- 2017: Microsoft announces it will not kill off its basic but very popular Paint program, loved by computer artists for over 30 years.
Y . I/O IIIIIIIIII How to draw scientific diagrams
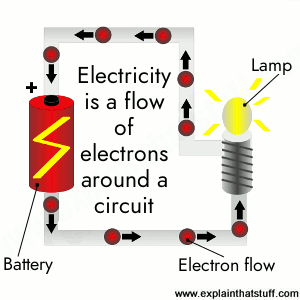
No-one's ever likely to mistake me for Michelangelo, but I have at least one thing in common with that famous Renaissance artist: both of us have used art to communicate important things to other people. In Michelangelo's case, it was stunning paintings and sculptures; my own contribution to art history has been far more mundane: over the last decade or two, I've had to produce dozens of diagrams to illustrate the books and web pages I've written about science and technology.
Much of the time I've had superb artists and illustrators to help: I've just roughed out a basic sketch and they've done all the clever stuff for me. Recently, since I've been writing more for the web, I've produced most of my own art as well, which means I've had to learn to draw scientific and technological things far better than ever before. That's been a real challenge, because I've never been good at art. Fortunately, scientific art is very different from real, artistic art and, even if you've as little artistic talent as me, you can still do a passable job of communicating your ideas if you use a decent computer graphics package. So what's the secret? Here are some of the tips I've picked up over the years that I'd like to share with you now.
Artwork: How electricity works: I've redrawn this diagram at least four times in the last few years and this will probably be the final version. It was drawn large and scaled down to make the battery look good. I've put a big caption in the center of the picture and labeled the three key components. The drawback of doing this is that readers who don't use English, but who use auto-translation to read my pages in their own language, will see English text they may not understand. I discuss an easy way around this in point 6 below.
1. Keep it simple
Once you've decided what you're going to draw (say, how a television works), strip down to the absolute essence of what you're trying to communicate (the process by which a broadcast signal arrives and is turned into a picture and sound by the circuits inside). If this is the kind of thing you're trying to explain, you don't need to show every single electronic component: just pick the handful of key bits that tell your story and forget everything else. Combine components and show them as bigger, cruder parts if you wish. Good how-it-works diagrams have maybe only a dozen distinct elements to them at most.Remember that your entire explanation doesn't have to rest on this one artwork: you'll have text and you can add photos too to show finer details of how things appear in reality. If you're going to use photos and artworks together, it's best to choose the photos first so you can draw your artwork to relate to them in some way (you could copy key details from the photos, or use the same colors for parts that the photos show so your readers can relate the artwork directly to the photos without difficulty).
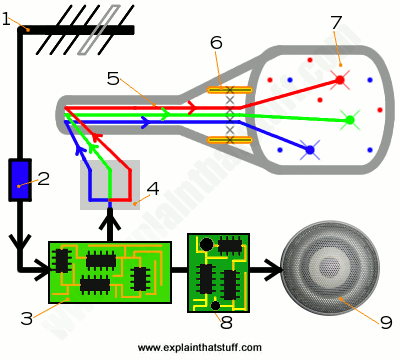
Artwork: How a television works: This diagram illustrates many of the principles I've set out in this article. It's ultra-simplified, there's no excess decoration, I've removed everything but the components I want to explain (fewer than 10 in total), I've arranged the internal parts in an order that makes sense to my explanation (taking lots of licence), I've made the artwork flow logically from top to bottom and from left to right, I've mixed photography (of the chip and speaker) with drawing, and I've left the text off the artwork (in favor of numbers) so the captions will translate properly. It's no Michelangelo, but I think it does its job well.
2. Communicate not decorate
There's a great temptation to draw things in extreme detail so they look as realistic as possible, but there's usually no need: the fewer lines you use and the simpler you make things, the easier they are to understand. If you're drawing the drive mechanism of a car, and explaining how power gets from the engine to the wheels to make it go down the road, you don't need to draw any of the parts in any great detail. You can just draw the car wheels as circles, for example—you don't need to draw the nuts on the hubs or the tread on the tires!"Communicate not decorate" is a lesson you'll learn quickly by browsing the artworks that inventors draw when they submit patent applications (legal records of inventions). With the help of a site like Google Patents, you can quickly find the original records of all kinds of famous inventions, from the Wright brothers' "flying machine" to George de Mestral's detailed description of VELCRO® (the hook-and-loop fabric fastener). It's well worth browsing through some of these patents to see how technical illustrators simplify complex mechanisms so they're easily understandable from a drawing. One of the biggest challenges these artists face is communicating incredible amounts of detail in a two dimensional, static, black-and-white picture. There is no room at all for decoration, which distracts from the explanation. When I'm using patent drawings on this website, I typically add color to make them easier to follow (and sometimes I animate them too).
Artwork: George de Mestral's VELCRO® patent includes this very clear drawing showing how his invention works. The original is black and white, but I've added the color myself to make the explanation faster and clearer. It's important to note that the color is here to communicate, not decorate: the simple addition of two colors, to show up the two distinct parts of the VELCRO® fastening, makes all the difference. Artwork from US Patent 3,009,235: Separable fastening device courtesy US Patent and Trademark Office.
3. Take artistic (and scientific) licence
Painters often use what's called "artistic licence," which means they don't slavishly follow reality if they can make a better picture some other way. They might put in extra people, move trees, draw buildings in different places, and take all kinds of other liberties with reality to produce a more interesting composition. As a scientific artist, you should feel free to do exactly the same. Leave things out if they complicate what you're trying to communicate; add extra things in if they help. If it confuses to draw things exactly as they are, draw them a different way. Your number one priority is not to depict reality exactly as it is—you can use a photograph for that—but to help people understand something. Remember all the time that you are trying to communicate clearly; it's fine to bend the truth a little to make that happen.David Macaulay, one of the greatest technical illustrators of the 20th century, made his name with the fantastic children's book The Way Things Work. The striking thing about David's approach in that book is the use of a kind of "retro" drawing style to illustrate even the most cutting edge technologies: a woolly mammoth from prehistory sits happily alongside body scanners, computer chips, and lasers. Why? Isn't that precisely what I just told you to avoid: decoration at the expense of communication? No, it's artistic licence! David's style makes mundane material more lively and compelling—so you spend time inspecting his drawings instead of just thinking "Well that's pretty dull" and turning the page. The drawings entice and engage you so the process of communication can begin. If you aspire to be any kind of technical artist or illustrator, David's work is definitely something to study.
4. Go with the flow
In the western world, we read pages of text from left to right (Arabic readers are used to their eyes working in the opposite direction) and from top to bottom. People naturally try to read diagrams the same way, starting on the left and moving to the right, and flowing from the top of the page to the bottom, so design your artworks that way if you possibly can. If you're laying out the parts of something, assume they'll be read left-to-right and top-to-bottom. If you're illustrating a sequence of things, arrange it in a logical order with the first item on the left, then the second item, and so on... working your way across to the right of the page.5. Number in a logical order
You'll often find it helps if you number items on a diagram, especially if you're showing a definite sequence of things or lots of different parts. Again, if you're going to do this, make sure the numbers flow logically either from left to right, top to bottom, clockwise, or anticlockwise. Don't have the numbers jumping around all over the place (especially if there are lots of them). Readers don't want to have to keep scanning their eyes back and forth over the diagram to search for the next item: make it easy and less confusing by putting things in the order they expect.6. Leave text off the artwork on web pages
Often you'll need to label a diagram with names of parts or short captions that explain what's going on. If you're preparing a diagram for a book, it's usually easiest to put the text on the diagram itself—and there's no real reason for not doing so. If you're producing an online diagram to illustrate a web page, there's something else to think about. If your website is like mine, a high proportion of your readers may be reading your pages not in English but auto-translated into their own language. If you write text on your artwork (as I've done in the top picture on this page), foreign language readers may not be able to understand it. The alternative (and one I've used on the other artworks shown here) is to put numbers on my pictures and then caption those numbers in the HTML text of the web page, in something like a numbered list. Then if the web page is auto-translated, the captions will be auto-translated too and readers will still be able to understand the artwork properly. The broader lesson here is to see things through your reader's eyes.7. Explain in space... and time
Often you'll want to explain how something like a machine works in a sequence of distinct steps. Sometimes you can do that by drawing the parts inside in a particular way (not necessarily how they're arranged in reality), laying them out on the page (or the screen) from left to right and numbering them so you can describe what they do in the correct order. That's what I've done with the TV set and airbag artworks on this page. I've separated key parts in space to make a process clear in each case.If you're drawing something for the web, there's also the option of making a simple animation—which amounts to separating parts in time as well as space. If you want to do this, the easiest way is to make an animated GIF, which is simply a series of individual frames (separate pictures) packaged into a conventional GIF file so they play in sequence as many times as you like.
Bear in mind that animated GIFs can turn into very large files, they'll take time to load, and they may slow down your pages. There are three things you can do to address that: try not to get carried away with too many frames (four is about the maximum you want); keep the size of the artwork as small as you can without sacrificing clarity; and use a relatively limited color palette (a small number of colors). If you find you've ended up with a very big GIF file, try reducing the number of colors from 256 (typically the default) to 128, 64, or 32. Find a value that preserves the quality without making the file size too big.
You can also use Flash for making animations, but it's more of a nuisance for users. You can't be certain that Flash files are supported on browsers and mobile devices and, with the development of HTML5, there's some doubt about how long Flash itself will survive. Animated GIFs have been around since the earliest days of the web; they're tried-and-tested and work on pretty much everything.
Animation: How a smoke detector works. This one uses two simple, alternating frames to communicate an idea that would be hard to depict without animation. In the first frame, I show the detector in its passive state; in the second frame, I show what happens when smoke enters and triggers the alarm. It's easy to make animations like this. You just draw one frame, save it and make a copy, modify that copy to make your second frame, and then combine the two frames in a single animated GIF. You can easily specify how many times the frames loop (here it's indefinitely) and the time lag between them. You can make animated GIFs in lots of different graphics packages, including the GIMP, which is what I use.
8. Scale your pictures according to your users
In the world of Michelangelo art, bigger is often better, but that doesn't always hold for scientific art. Generally you want diagrams that are big enough to see and understand. In books, page size and layout are the constraints you work with. On the screen, things are slightly different. Bear in mind that not everyone will have a screen the same size as yours. Increasingly, people are browsing websites on mobile devices, many of which have a maximum screen size of 320×480 pixels (though "phablets," which are somewhere between cellphones and tablets, are significantly bigger). On this website, we're now trying to keep all photos and artworks within these dimensions if we possibly can.Designing materials for readers doesn't just mean seeing things through their eyes; it means testing things the way they'd use them too. In the case of web pages, be sure to try out your artworks on a range of different devices. Colors, for example, can vary quite a bit between different laptops and screen types. Do your artworks look equally good on smartphones, tablets, and desktops? If you're not lucky enough to own a closet full of computers, you can test your pages using mobile device emulators with a web browser such as Chrome (Chromium on Linux). Look under "More Tools" and "Developer Tools" and you'll find a huge set of emulators that let you test any web page on a wide range of emulated devices, from iPods and iPads to Kindles and Blackberrys.
Bear in mind that it's not just the basic pixel dimensions of an artwork that affect how it will look on a particular device: the aspect ratio and resolution of the device itself are also very important. If you find it confusing to get your head around all this stuff, Google has published two excellent introductions that I can recommend: Image Optimization by Ilya Grigorik and Images in Markup by Pete LePage.
9. Beat your poor artistic skills
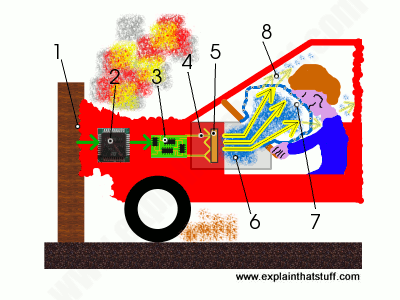
Artwork: How an airbag works: I'm really pleased with how this little drawing turned out. The final artwork is 400×300 pixels, but I drew it about three times the size (so the original filled my screen) and scaled it down. Overall, the effect is far better than if I'd drawn at 400×300 to start with. Not everything worked out, though: after I scaled down, the circuit (3) became too blurred to make out properly, so I had to redraw it. Bear in mind that anything finely detailed will take up a half, a third, or a quarter as many pixels after the scaling process, which could make it difficult to see. Experiment with scaling first so you know what will work and what won't before wasting your time on elaborate detail.
Picture size is also helpful if, like me, you're a clumsy artist. I find I always know what to draw, but actually translating what's in my mind into a nice-looking picture on the screen is quite difficult because I don't have enough skill with a mouse.
Fortunately, there is a solution. First, figure out the final size of the artwork you want (say it's 300×300 pixels). Then, instead of making your "canvas" that size to start with, make it at least twice as big (or three times as big if you can). Draw your picture so everything is double or triple size and then, when it's finished, scale it down to 300×300 or whatever. You'll be amazed how much more professional it looks. Your wiggly, pixelated lines will all look far sharper and better drawn. Bear in mind that lines will get thinner as you scale a picture down so you may need to use a bigger "brush" size than you would normally. Also, text may blur as you scale down so you may want to add in any text or numbering after the scaling operation, not before.
Another good trick for so-so artists is to mix photography with drawn artworks, as I have in the TV picture up above. If you need to illustrate bits of something you can't draw, find copyright-free photos of them online (or even take your own photos) and cut and paste into your artwork as necessary. I took photos of the speaker and circuits because I didn't think I could draw them well.
10. Use pullouts instead of cutaways or explosions
Artwork: How a plasma TV works. Here I'm using a pullout (the grey circle on the right) to show what happens inside one pixel of a plasma TV screen (the colored grid on the top left).
If you're drawing technological things, like machines, you often need to show bits that are hidden away out of view. A really skillful artist can do this with a cutaway (a composite drawing in which part of the exterior is removed to show what's lurking behind) or an exploded diagram (where the parts inside something are separated in a very logical way that keeps a suggestion of how they fit together). Cutaways and explosions are very demanding and time-consuming for even skilled artists to draw, but again there's a solution—in the form of pullouts.
A pullout is simply a detailed, magnified drawing of one part of another drawing that you place on top with lines to show what it relates to. (It's a bit like holding a magnifying glass over part of your main drawing.) One approach is to take a photo of the object you want to illustrate and draw a large circle on some part of it where you can safely cover what's underneath. Inside the circle, draw a simple artwork illustrating some key detail of what's happening inside the object. Then draw two lines from the outside edge of the circle that meet at the point on the object where the action you've drawn is happening. (Remember that you can draw your diagram in a very large circle to begin with and then scale it down to size later.)
======= MA THE WORLD ELECTRONIC COMPUTER EL DESIGN MATIC ========
Tidak ada komentar:
Posting Komentar