
At the present time writing using a pencil, chalk and pens and markers have experienced a decline in the sense that the application is considered unattractive and does not have sufficient memory resistance, resulting in a product cycle where the writing components used by students and business people experience a decrease or near the death of the product. When the product has died, of course technology has seen and designed a replacement which in terms of reliability and attractiveness is better and useful for the long term, in which an event that occurs can be stored and repaired also developed continuously and step by step. the technology that is available now is a lot of its form, namely in electronic engineering that is a super interesting electronic machine such as: laptop - note book - e-pad - cable TV --- Smart Phone - electronic printer - electronic pen - and others etc . The new writing product component components are designed with better reliability and attractiveness because they can be stored and read at any time in the media, namely electronic media. the electronic machine we call above now has been supported in its production in various countries with the manufacture of large-scale electronics manufacturing plants such as Toshiba, Acer, Ms Windows, Apple, HP (Hewlett Packard), as well as smart phones with various types such as oppo, Xiaome , Sony, Motorolla, Texas and so on. in the present era, the existing electronic machinery has been supported by a good and super sophisticated communication and data network such as the internet which was developed by the United States government (USA) as well as a sophisticated satellite network which is widely developed by the existing satellite communication and optical fiber makers in various countries such as the United States and the European continent where the communication network is good and fast. the process of storing text and images has also progressed can be stored in e-mail and also an internet flash disk that might be free or paid for use. thus a glimpse of the social motivational movements and development of high school and college students and the general business network.
Love

Signature ; Gen Mac Tech
From Analog to Digital Writing
Digital and Analog Texts
We have all been asked in the past few decades to consider the advances offered in our lives by digital sound and image recording. Some must have felt that listening, seeing, and reading didn't always seem so different in this digital world when compared to the analog world; that a change that goes all the way down to the most fundamental aspects of representation ought to be more noticeable. Is this distinction between two modes of representation something fundamental that matters for how we read and interpret? Much of the talk of digital and analog comes from work on cybernetics and cognitive science; are these fundamental categories of thought that shape our experiences?
For to these questions is through the history of their use in twentieth-century engineering, cybernetics, and cognitive science. It is a history of metaphorical transfers, in which conceptual tools from one field are reused in others, and along with the spur to thought comes the potential for error. As I will show, the origin of the digital/analog distinction is in the practicalities of building machinery rather than in the fundamental nature of things. And the significance of the distinction also depends on the context. In the realm of engineering, the concepts of digital and analog are exact descriptions of how machinery is designed to operate; in studies of the body and brain, some functions may fit one category or the other, but the whole picture does not contain the same kind of sharp definitions and boundaries; and in the realm of cultural productions, some common practices may be usefully related to these concepts, but many other practices do not abide by those boundaries.
The concepts of digital and analog are helpful to readers and interpreters of texts insofar as they can help us describe some practices in the use of texts more precisely. But these concepts do not control the way texts work, nor do they exhaust the range of things texts can do. Systems are digital or analog because they were designed to act that way; the concepts are less pertinent for application to a system without overt design, explicit boundaries, or rules for interpretation.
Digital and Analog Systems
The common habit is to refer to data as being digital or analog; but it is only as a property of whole systems that the terms are meaningful. A body of data in either form means nothing outside the system that is engineered to perform operations on it. References to digital and analog data suggest that this is an essential property of such data, when it is instead a way to describe how the systems using such data are built to work.
John Haugeland's definitions of digital and analog devices remain the best, and are those I will follow. His principal point about digital devices is that they are based on data defined so that it can be copied exactly: such a system can read, write, and transfer data with perfect preservation of exactly the same content. That is achieved by defining a closed set of distinct tokens that may appear, and requiring all data to be a sequence of such tokens; in most present-day computer systems these basic tokens are bits that may be either 0 or 1 and nothing else, but a system may be based on many more values. (Some early computer systems were intrinsically decimal, for example; and a three-valued notation is more efficient for storage than binary [Hayes 2001].) A copy of digital data is indistinguishable from the original, and within digital computer systems such copying happens with great frequency: the reliability of copying in such systems is not a potential property but one that is exercised constantly. Analog systems involve continuous ranges, not discrete ones: there could always be more gradations between two selected values on a scale. Analog data cannot be copied perfectly, so the criterion in building an analog system is not making perfect copying happen every time, but reducing the accumulation of error and minor changes. The nth-generation-copy problem is a problem of an analog system; a digital system must be designed so that it doesn't have that problem in the slightest degree.
Analog and digital systems embody different sorts of rules for interpretation of data, but they are both built on rules, and the data they process is defined in terms of those rules. Removed from the systems and from the rules for interpretation, the data may also change from analog to digital or vice versa. A famous example due to Nelson Goodman is the clock dial: this looks like an analog system, because you can read off the time to any degree of precision in measuring the position of the hands. In actual practice, we often treat this as a digital device, and only read it to full minutes. The clock might have a digital or an analog mechanism, which affects whether the information is really there to be measured at arbitrary precision. But in any case, this stage of interpretation of something outside the system is an occasion when information often changes from digital to analog or vice versa.
A system of either type cannot regard the data as stable and unproblematic; both digital and analog systems must be engineered to preserve the data. We have some familiarity with that effort from daily life when using analog systems: here again, practical familiarity with operations such as photocopying gives us the intuition that an analog copy may be better or worse and that some effort can improve the result. In analog systems, the crucial need is to avoid introducing noise as data moves about within the system. In computer systems the provisions for keeping data stable are internal and rarely visible to users, but they are there all the same. In discussions of computing it's common to read that switches are either on or off and therefore digital bits naturally have two values, 0 or 1; this analogy seems to go back to an essay by Alan Turing, but Turing's point that it is a simplified picture is usually omitted (1950: 439). The simplification is flatly wrong about how present-day computers actually work, since they use high and low voltages and not open or closed circuits, and their circuitry at many points works to push signals to the high or low extremes, and away from the intermediate range where one value could be mistaken for another. (Hillis 1998 is one of the rare popular accounts of computer hardware that touches on these provisions.) Peter Gutmann's account of the problems of erasing hard disk drives helps to illustrate the work behind the scenes to produce those perfect bits, a complex but ultimately very reliable process — and also the possibility of studying the history of what a drive has stored if you analyze it using analog equipment:
… truly deleting data from magnetic media is very difficult. The problem lies in the fact that when data is written to the medium, the write head sets the polarity of most, but not all, of the magnetic domains. This is partially due to the inability of the writing device to write in exactly the same location each time, and partially due to the variations in media sensitivity and field strength over time and among devices…
In conventional terms, when a one is written to disk the media records a one, and when a zero is written the media records a zero. However the actual effect is closer to obtaining a 0.95 when a zero is overwritten with a one, and a 1.05 when a one is overwritten with a one. Normal disk circuitry is set up so that both these values are read as ones, but using specialised circuitry it is possible to work out what previous "layers" contained. The recovery of at least one or two layers of overwritten data isn't too hard to perform by reading the signal from the analog head electronics with a high-quality digital sampling oscilloscope, downloading the sampled waveform to a PC, and analysing it in software to recover the previously recorded signal…
Deviations in the position of the drive head from the original track may leave significant portions of the previous data along the track edge relatively untouched Regions where the old and new data coincide create continuous magnetization between the two. However, if the new transition is out of phase with the previous one, a few microns of erase band with no definite magnetization are created at the juncture of the old and new tracks…
When all the above factors are combined it turns out that each track contains an image of everything ever written to it, but that the contribution from each "layer" gets progressively smaller the further back it was made. Intelligence organisations have a lot of expertise in recovering these palimpsestuous images.
The difference between digital and analog systems, then, is best understood as an engineering difference in how we choose to build systems, and not as resulting from an intrinsic property of data that somehow precedes those systems. Outside such systems, the status of data is less definite, because there is no longer the same specification about what is and is not significant. John Haugeland remarked: "digital, like accurate, economical, or heavy-duty, is a mundane engineering notion, root and branch. It only makes sense as a practical means to cope with the vagaries and vicissitudes, the noise and drift, of earthly existence" (1981: 217). It has become common in popular usage to talk about the analog as the category that covers everything that isn't digital; but in fact most things are neither. The images, sounds, smells, and so on that we live among have mostly not been reduced to information yet. Both analog and digital systems require some stage of choice and reduction to turn phenomena from the world into data that can be processed. The most common error about digital systems is to think that the data is effortlessly stable and unchanging; the most common error about analog systems is to think they're natural and simple, not really encoded.
Minds and Bodies
Both approaches were embodied in machinery long before the rise of digital computers: the abacus is digital, the slide rule is analog. As technology, then, the digital is not something that only arose in the twentieth century. But it was in the later twentieth century that digital computers came to provide an almost inescapable model for thinking about the mind. (On the longer history of such technological analogies, see Wiener 1948; Marshall 1977; Bolter 1984.) How the digital computer came to eclipse the analog computer in such thinking, even though careful study suggested that both kinds of processing were probably among those used in the brain, is one key element of that story, and one that illuminates some of the cultural associations of our current ideas of the digital and analog.
Although the use of both approaches and an awareness of their differences go back a long way, the standard distinction between the two, their names and their pairing, all came in the mid-twentieth century, when substantial advances were made in machinery for both kinds of systems, and there was a serious choice between building one kind of system or the other for many communications and computational applications. (The best available account of that moment is in Mindell 2002.) That was also the moment when the new fields of cybernetics and information theory arose, and seemed to offer remarkable insights into human bodies and minds. Cybernetics in particular proposed understandings of systems that responded to the environment, without strong distinctions between machinery and living beings. In that context, it was a natural question to ask whether human minds and bodies were digital or analog. The thinking of that era is worth revisiting because its perspective is so different from today's assumptions — and so suggests other paths of thought; this earlier perspective has the merit of pointing out complexities that are lost when we focus primarily on the digital.
Cybernetics, today, is a field that lingers on in small pockets of activity but does not matter. But in its day, roughly from 1943 to 1970, it was a highly interdisciplinary field, which encompassed topics now split up among medicine, psychology, engineering, mathematics, and computing, and one of its most persuasive claims to importance was its ability to bring so much together productively. Today its achievements (quite substantial ones) have been merged back into the subject matter of those separate disciplines, and in a broader cultural context its nature and ideas have been mostly forgotten — so that (to give one example) a recent editor of Roland Barthes's work assumes that the term "homeostat" was invented by Barthes, though in Barthes's writings of the 1950s its source in cybernetics is clearly indicated (Barthes 2002: 83).
Although cybernetics included much that is now classified under the heading of cognitive science, it did not give cognition primacy as the object of study. Definitions of cybernetics usually focused on the idea of "control systems," which could respond to the environment and achieve results beyond what it was normally thought machines could do; as Norbert Wiener wrote in his influential book Cybernetics; or, Control and Communication in the Animal and the Machine in 1948:
The machines of which we are now speaking are not the dream of the sensationalist, nor the hope of some future time. They already exist as thermostats, automatic gyrocompass ship-steering systems, self-propelled missiles — especially such as seek their target — anti-aircraft fire-control systems, automatically controlled oil-cracking stills, ultra-rapid computing machines, and the like.
(1948: 55)
The workings of the body were as important a subject as anything cognitive. The interest more recently in "cybernetic organisms" reflects the perspective of cybernetics, which did not distinguish sharply between biological and mechanical systems, and also did not emphasize thought. The excitement associated with the field goes back to earlier discoveries that showed how (for example) the body maintained its temperature by means that were natural but also not cognitive: we don't think about how to keep our body temperature stable, but it is also not a supernatural effect. Previous doubts that the body could be described as a machine had been based on too limited an understanding of the possibilities of machinery; cybernetics showed that a "control system" could achieve a great deal without doing anything that looked like thinking. Wiener's book, which at times has whole pages of mathematical equations, also includes a cultural history of the idea of building "a working simulacrum of a living organism" (1948: 51), leading up to the way cybernetics proposed to do it.
To sum up: the many automata of the present age are coupled to the outside world both for the reception of impressions and for the performance of actions. They contain sense-organs, effectors, and the equivalent of a nervous system to integrate the transfer of information from the one to the other. They lend themselves very well to description in physiological terms. It is scarcely a miracle that they can be subsumed under one theory with the mechanisms of psychology.
(1948: 55)
The word "cybernetic" today is most often just a synonym for "computational"; but in the early thinking of the field computation was only one subject, and being effectively "coupled to the outside world" seemed more important. Peter Galison has traced the role played by Wiener's war work in the development of his thinking — in particular, he had actually been involved in building "anti-aircraft fire-control systems." They could be thought of "in physiological terms" by analogy with reflexive actions of the body, not with thought or calculation. Galison mounts a critique of the dehumanizing tendency of cybernetic thought, but that doesn't seem to be the only way people took it at the time. Theodore Sturgeon's science-fiction novel More than Human (1953) is very clearly influenced by cybernetic thinking (one scene involves "a couple of war-surplus servo-mechanisms rigged to simulate radar-gun directors" that happen to appear as part of a carnival's shooting-gallery attraction [1953: 169]), and it follows cybernetics in assigning conscious thought a role that does not direct everything else. The novel describes the genesis of a being made up of several people with different abilities: "a complex organism which is composed of Baby, a computer; Bonnie and Beanie, teleports; Janie, telekineticist; and myself, telepath and central control" (1953: 142). Computing was quite distinct from "central control."
Cybernetics did include a chapter entitled "Computing Machines and the Nervous System," specifically concerned with how you might build a computer to do what the brain does; though it spends as much time on memory and reflex action as on calculation. Wiener talks about digital and analog representation, but the stress is on the engineering question of what would work best in building a computer, and he argues for binary digital computers for reasons broadly similar to those behind their use today. The neuron, he observes, seems to be broadly digital in its action, since it either fires or does not fire; but he leaves mostly open the question of just what sort of representation the brain uses, and is instead trying to consider very generally how aspects of the brain could be realized in machinery. The importance of the digital-or-analog question here is practical: if you are going to do a lot of computation and data storage, digital has more advantages; but analog representation for other purposes is not ruled out. (In contexts where not very much information needed to be preserved, and detection and reaction were more important, the issue might be quite marginal. W. Ross Ashby's Introduction to Cybernetics has only the barest mention of digital and analog representation.)
The writings of John von Neumann and Gregory Bateson are the two principal sources for the idea that the choice of digital or analog representation is not merely an engineering choice for computer builders, but had real consequences for thought; and that it was a choice that is built into the design of the brain. Von Neumann's views appeared in a posthumously published book, The Computer and the Brain, which in its published form is closer to an outline than to a fully elaborated text. (The review by von Neumann's associate A. H. Taub is a very helpful supplement.) The title characterizes the contents very exactly: Part I describes how computers (both digital and analog) work; Part II describes how the brain works, so far as that was known at the time, and then tries to conclude whether it's a digital or an analog system. Like Wiener he sees the neuron as mainly digital because it either fires or it doesn't; but he too sees that the question is actually more complicated because that activity is influenced by many factors in the brain which aren't on/off signals. This leads to a conclusion that is often cited as the book's main point: that the brain uses a mixture of digital and analog representation (Taub 1960: 68–9). But a substantial part of the book follows that passage, and here von Neumann develops a quite different conclusion: that the brain works in a way fundamentally different from computers analog and digital — it's statistical. Nothing like the precision of mechanical computers in storage or computation is available given the brain's hardware, yet it achieves a high degree of reliability. And von Neumann concludes that the logic used within the brain must be different from that of mathematics, though there might be some connection: a striking conclusion from a mathematician strongly associated with the development of digital computers. But in the end, von Neumann's account of computers is present to highlight what's different about the brain, not to serve as the complete foundation for understanding it.
Gregory Bateson, like von Neumann, was active in cybernetics circles from the 1940s onward; but unlike Wiener and von Neumann he did not work in the physical sciences, but instead in anthropology and psychology. His Steps to an Ecology of Mind: Collected Essays in Anthropology, Psychiatry, Evolution, and Epistemology (1972) collects work that in some cases dates back to the 1940s. It is perhaps best known today as the apparent source of the definition of information as "a difference which makes a difference" (1972: 315, 459). The breadth of concerns surpasses even that of cybernetics: few other books combine analyses of schizophrenia with accounts of communicating with dolphins. But looking for fundamental principles that operated very broadly was a habit of Bateson's:
I picked up a vague mystical feeling that we must look for the same sort of processes in all fields of natural phenomena — that we might expect to find the same sort of laws at work in the structure of a crystal as in the structure of society, or that the segmentation of an earthworm might really be comparable to the process by which basalt pillars are formed.
(1972: 74)
Bateson's criticism of much work in psychology in his day was that it lacked an adequate conceptual basis; so he sought to find fundamental principles and mechanisms on which to build in his work. The difference between digital and analog representation seemed to him one such fundamental distinction: he argued that the two modes entailed different communicative possibilities with different psychological consequences. Analog communication, in his view, did not support the kinds of logical operations that digital communication facilitated, and in particular negation and yes/no choices were not possible; that led to a connection with Freudian concepts that also did not work in accordance with traditional logic (as in "The Antithetical Meaning of Primal Words," for example), and to new theories of his own (of the "double bind," for example).
Bateson's work mirrors one feature of cybernetics in its advantages and disadvantages: he seeks to talk about whole systems rather than about artificially isolated parts; but it is then difficult to find places to start in analysis. The analog/digital pairing is important in his work because of the resulting ideas about different cognitive and communicative possibilities. The distinction had some connection with the difference between people and animals: nonverbal communication was necessarily analog, in Bateson's view, and so could not have the digital features he saw in verbal communication. But, like von Neumann, he concluded that digital and analog representation were both used in thinking — though von Neumann's account was based on a consideration of brain physiology, and Bateson's on the nature of different forms of communication. In both cases, the answers to the question track rather closely the answers current in the 1940s and 1950s to questions about how you'd engineer practical control systems using the available technology. The accounts by Wiener and von Neumann are only clearer than Bateson's about how thought is being seen in the light of current technology, because of their deeper understanding of that technology and fuller awareness of how open the choice still was.
In all of these accounts, then, the mind is not just a digital computer, and its embodiment is a major concern in developing a scientific account. Of course, the course of subsequent technological history was one in which digital computing grew far faster than analog computing, and also began to take over applications that had originally been handled using analog technology. We also have more and more an equation of the analog with the physical and the digital with the cognitive, an alignment that wasn't there in the 1940s and 1950s; popular ideas about the digital/analog pairing in general are narrower in their field of application. While work continues on all the topics that cybernetics addressed, attempts to bring them all together as cybernetics did are now much rarer, and as a result there is (for example) a good deal of work in cognitive science and artificial intelligence that is about ways to make computers think, without reference to how the body works, and with the assumption that only digital techniques are necessary. This approach results, of course, from the remarkable development in the speed and capacity of digital computers: this line of work is attractive as a research program, even if it remains clear that the brain doesn't actually work that way.
One stage along that path may be seen in work from the 1970s by the social anthropologist Edmund Leach, who absorbed influences from cybernetics and structuralism, among other things. In Wiener the choice of binary representation was an engineering decision; but the connection with structuralist thinking was probably inevitable:
In practice, most structuralist analysis invokes the kind of binary algebra which would be appropriate to the understanding of the workings of a brain designed like a digital computer. This should not be taken to imply that structuralists imagine that human brains really work just like a digital computer. It is rather that since many of the products of human brains can be shown to have characteristics which appear also in the output of man-made computers it seems reasonable to attribute computer-like qualities to human brains. This in no way precludes the probability that human brains have many other important qualities which we have not yet been able to discern.
(1972: 333)
Leach's is what by now is a common move: to state that the compelling analogy with digital computing is of course partial, but then to go on to assume it is total. This essay was a contribution to a symposium on nonverbal communication, and unlike most of the other contributors Leach saw nonverbal communication as very similar to verbal communication:
The "yes"/"no" opposition of speech codes and the contrasted signals of non-speech codes are related to each other as metaphors; the structuralist hypothesis is that they are all alike transforms of a common algebraic opposition which must be assumed to occur as "an abstract element of the human mind" in a deep level structure. The relation between this abstraction and the physical organisation of human brain tissue is a matter for later investigation.
Incidentally it is of interest that the internationally accepted symbolism of mathematics represents this binary opposition either as 0/1 or as −/+. The second of these couplets is really very similar to the first since it consists of a base couplet −/− with the addition of a vertical stroke to the second half of the couplet. But if a student of primitive art, who could free himself from our assumptions about the notations of arithmetic, were to encounter paired symbols 0/1 he would immediately conclude that the opposition represented "vagina"/"penis" and was metonymic of female/male. A structuralist might argue that this fits very well with his assumptions about the deep structure algebra of human thought.
(1972: 334)
As we have seen, Bateson's view of nonverbal communication was that it involved a kind of logic that was basically different from the digital and the verbal; but Leach doesn't respond to his views (though he cites one of his books on the subject), or to those of the other speakers at the symposium.
Like cybernetics, structuralism has come and gone. But just as anything binary looked like the right answer to Leach, today anything digital has the same appeal for many. Thus it is now common to read scrupulous and thoroughly researched books on cognitive science — such as Daniel C. Dennett's Consciousness Explained (1991) and Steven Pinker's How the Mind Works (1997) — in which considerations of brain anatomy are only a secondary matter. Once the point is established that there is a good case for seeing the brain as performing computations, though in ways different from conventional digital computers, there is a shift of emphasis to the computational level alone: with the idea that (as both writers put it) most of what matters can be seen as happening in a layer of "software" whose nature doesn't depend very strongly on the brain "hardware" whose details are yet to be established. Though the non-digital features of the brain are fully acknowledged, everything shows a tendency to revert to a digital mode. Some are highly critical of the digital emphasis of this kind of approach: Jerry Fodor, for example, commented in 1983: "If someone — a [Hubert] Dreyfus, for example — were to ask us why we should even suppose that the digital computer is a plausible mechanism for the simulation of global cognitive processes, the answering silence would be deafening" (129). It is nevertheless a strong program for research: it has produced good work, it makes it possible to draw on the power of digital computers as research tools, and it does not require waiting around for a resolution of the many outstanding questions about brain anatomy.
But it doesn't prove that all thinking is digital, or that the situation of the program on the digital computer, involved from start to finish in processing digital data, is a complete model for the mind. The imbalance is far greater in popular culture, where the equation of the digital with thought and a disembodied computational world, and of the analog with the physical world, is inescapable (Rodowick 2001). In the era of cybernetics, the body was both digital and analog, and other things too; not only was the anatomy of the brain significant in a consideration of the mind, but the anatomy of the body offered useful analogies. Now we find ourselves needing to make an effort to defend the idea that the body has something to do with thinking, so strong is the idea of the division.
The Nature of Texts
In the mid-1960s, Nelson Goodman used the ideas of digital and analog representation to help develop a distinction between artworks expressed through "notations" —systems such as writing or musical scoring for specifying a work, with the digital property of being copyable — and art objects such as paintings that could be imitated but not exactly copied. The alphabet, on this view, is digital: every A is assumed to be the same as every other A, even if differences in printing or display make some particular instances look slightly different. There is a fixed set of discrete letters: you can't make up new ones, and there is no possibility of another letter halfway between A and B. A text is readily broken down into its component letters, and is readily copied to create something just as good as the original. But a painting is not based on juxtaposing elements from a fixed set, and may not be easy to decompose into discrete parts. Like von Neumann and Bateson, Goodman found that the modes could be mixed: "A scale model of a campus, with green papier-mâché for grass, pink cardboard for brick, plastic film for glass, etc., is analog with respect to spatial dimensions but digital with respect to materials" (1968: 173).
The idea that text is in this sense a digital medium, a perfect-copy medium, is now widespread. And this view also fits many of our everyday practices in working with texts: we assume that the multiple copies of a printed book are all the same, and in an argument at any level about the merits of a recent novel it would not be persuasive if I objected, "But you didn't read my copy of it." In the world of art history, though, that kind of argument does have force: it is assumed that you need to see originals of paintings, and that someone who only saw a copy was seeing something significantly different. In discussions of texts we also assume that it is possible to quote from a text and get it right; you could make a mistake, but in principle it can be done and in frequent practice it is done. The digital view of text offers an explanation of what's behind these standard practices.
The digital view of text also suggests reasons why it works so well in digital computer systems: why text does not in general pose as many technical difficulties as graphics, and is at the heart of some outstandingly successful applications, most notably digital publishing and full-text searching. Written language is pre-analyzed into letters, and because those letters can be treated as digital data it is straightforward to make digital texts, and then to search them. The limitations of full-text searching are familiar: above all, the problem that it's only particular word forms that are easy to search, and not meanings. But that is still far ahead of the primitive state of searching digital images: because there is no easy way to decompose digital images into anything like an alphabet of visual components, even the most limited kind of image searching is a huge technical problem. And while we have many tools for working with digital texts and images, it is for texts that we have tools like spelling correctors that are able to get somewhere near the meaning, without any special preparation of the data. Image manipulation cannot do that unless the image has been created in a very deliberate manner, to keep its components separate from the beginning (as with the "layering" possible in some programs).
But digital computers and written texts are digital in different ways. Digital computer systems are engineered to fit that definition: data in them is digital because it is created and maintained that way. Goodman's definition of a "notation" is an exact description of such data. But the same description is an idealized view of our practice with texts, one that helps explain many of its features but is wrong about others. A digital system has rules about what constitutes the data and how the individual tokens are to be recognized — and nothing else is to be considered significant. With texts we are free to see any other features as significant: to decide that things often considered as mere bearers of content (the paper, the design, the shapes of the letters) do matter. Such decisions are not merely arbitrary whims, as we internalize many assumptions about how particular sorts of texts should be presented. Jonathan Gibson has demonstrated the importance of blank space in seventeenth-century English letters: the higher the status of the addressee, the more blank space there was supposed to be on the page. And most readers of the present chapter would find their response to it affected by reading a text written in green crayon on yellow cardboard, rather than in a printed Blackwell Companion. Examples are not difficult to multiply once you try to examine implicit assumptions about how texts are appropriately presented and not merely worded. Though many of our practices assume that text is only the sequence of alphabetic letters, is only the "content," the actual system involves many other meaningful features — features which as readers we find it difficult to ignore. These issues about copying are ones that may well seem to lack urgency, because along with knowledge of the alphabet we've absorbed so much about the manner of presentation that we don't normally need to think about it: the yellow cardboard is not something you even consider in thinking about academic writing. But a description of what reading actually is must take these issues into account.
The digital trait of having an exact and reliable technique for copying does not in practice apply to texts on paper: it is not hard to explain how to copy a contemporary printed text letter-for-letter, but getting it letter-perfect is in fact difficult for a text of any length, unless you use imaging methods that essentially bypass the digitality of the alphabet. But the bigger problem is knowing what matters besides the letters: To what level of detail do we copy? How exactly do we need to match the typefaces? Does it need to be the same kind of paper? Do the line breaks need to match? Some of these features are ones that could be encoded as digital data, some as analog; but the core problem is that there is not a clearly bounded set of information we could identify as significant, any more than with a painting. Once we attend to the whole object presented to our senses every feature is potentially significant.
Texts created in digital form to some extent avoid these problems. They're digital and so can be exactly copied. Languages such as PostScript can specify what is to be displayed with great specificity (though the more specific such languages are, the more complex they are: PostScript is vastly larger than HTML). But actual presentations still wind up being variable because machinery is: a reader still sees the text on a particular screen or paper, and those interfaces are features that still matter for the reception of what's written.
It is not, of course, absurd to say to readers: look at what I've said, not at the way it's written down! It remains true that many practices in working with texts fit the digital view, in which only the sequence of letters is significant, and this view of their work is often what authors intend. The experience of using the World Wide Web has bolstered that view, as we now often see work of scholarly value presented in a typographically unattractive manner that we ought to disregard. But that bracketing is a step we have to choose to take: our normal mode of reading just isn't to read the letters alone and abstract them in the digital way; we normally take in much more than that. We may think of ourselves as working with text as computers do, but it is not a way of working that comes naturally.
The constitution of digital and analog data is a function of the whole system in which it is embedded, rather than of data as an independent entity; the problem with texts is that the system does not have the built-in limits of a computer system, because we as readers don't always follow the digital rules. Just as it is appealing and even useful to think about the mind in digital-computer terms, it is also appealing and useful to think about text that way: so long as we remember that it is a partial view. You are not supposed to be paying attention to the typography of this chapter in reading it and extracting its informational content; as a piece of scholarly writing it is not supposed to have an aesthetic dimension at all. But, as Gérard Genette argued, there are ample empirical and theoretical reasons to think that any text has the potential to be regarded aesthetically, even this one; some writing by its form (such as poetry) makes a direct claim to literary status, but readers choose to regard other writing as literary despite its nonliterary genre. And beyond this, there does not seem to be a human operation of reading that works the way digital reading has to: by making a copy of the data as defined within the system, and nothing more. That bracketing may to a degree become habitual for us, to the extent that it seems like the proper way to read, but it never becomes quite complete. Reading remains a practice that is not reducible to information or to digital data.
XO____XO Electronic Scholarly Editions

Many people have commented on the ongoing transformation of scholarly publication, with some fearing and some exulting over the move to digital production and dissemination. It seems inevitable that an ever-increasing amount of scholarly work will take digital form. Yet if we assess the current moment and consider key genres of traditional print scholarship — articles, monographs, collections of essays, and scholarly editions — we find that digital work has achieved primacy only for editions. The turn toward electronic editions is remarkable because they are often large in scope, requiring significant investments in time and money. Moreover, although editions are monuments to memory, no one is expressing great confidence in our ability to preserve them. Marilyn Deegan notes the challenge librarians face in preserving digital scholarly editions — this "most important of scholarly tools" — and suggests steps scholars may take "in order to ensure that what is produced is preserved to the extent possible" (Deegan 2006: 358). Morris Eaves candidly acknowledges the uncertain future of the project he co-edits: "We plow forward with no answer to the haunting question of where and how a project like [The William Blake Archive] will live out its useful life" (Eaves 2006: 218). Given the apparent folly of investing huge amounts of time and money in what cannot be preserved with certainty, there must be sound reasons that make this medium attractive for scholarly editors. This chapter explores some of those reasons.
Jerome McGann has argued that the entirety of our cultural heritage will need to be re-edited in accord with the new possibilities of the digital medium (McGann 2002: B7). He laments that the academy has done little to prepare literary and historical scholars for this work, thus leaving the task, he fears, to people less knowledgeable about the content itself: librarians and systems engineers. In general, humanities scholars have neglected editorial work because the reward structures in the academy have not favored editing but instead literary and cultural theory. Many academics fail to recognize the theoretical sophistication, historical knowledge, and analytical strengths necessary to produce a sound text or texts and the appropriate scholarly apparatus for a first-rate edition. In this fraught context, it seems useful to clarify the key terms and assumptions at work in this chapter. By scholarly edition, I mean the establishment of a text on explicitly stated principles and by someone with specialized knowledge about textual scholarship and the writer or writers involved. An edition is scholarly both because of the rigor with which the text is reproduced or altered and because of the expertise brought to bear on the task and in the offering of suitable introductions, notes, and textual apparatus. Mere digitizing produces information; in contrast, scholarly editing produces knowledge.
Many prominent electronic editions are referred to as digital archives, and such terminology may strike some people as loose usage. In fact, electronic editorial undertakings are only imperfectly described by any of the terms currently in use: edition, project, archive, thematic research collection. Traditionally, an archive has referred to a repository holding material artifacts rather than digital surrogates. An archive in this traditional sense may well be described in finding aids but its materials are rarely, if ever, meticulously edited and annotated as a whole. In an electronic environment, archive has gradually come to mean a purposeful collection of digital surrogates. Words take on new meanings over time, of course, and archive in a digital context has come to suggest something that blends features of editing and archiving. To meld features of both — to have the care of treatment and annotation of an edition and the inclusiveness of an archive — is one of the tendencies of recent work in electronic editing. One such project, the William Blake Archive, was awarded an MLA prize recently as a distinguished scholarly edition. The Walt Whitman Archive also contains a fair amount of matter that, in the past, ordinarily would not be included as part of an edition focused on an "author's" writings: we have finding guides to manuscripts, a biography, all reviews of Whitman's work, photographs of the poet, selected criticism from his contemporaries and from our own time, an audio file of what is thought to be the poet's voice reading "America," encoding guidelines, and other information about the history and technical underpinnings of the site. In other words, in a digital context, the "edition" is only a piece of the "archive," and, in contrast to print, "editions," "resources," and "tools" can be interdependent rather than independent.
Why Are People Making Electronic Editions?
One distinguishing feature of electronic editions is their capaciousness: scholars are no longer limited by what they can fit on a page or afford to produce within the economics of print publishing. It is not as if economic problems go away with electronic editing, but they are of a different sort. For example, because color images are prohibitively expensive for most book publications, scholars can usually hope to have only a few black and white illustrations in a book. In an electronic edition, however, we can include as many high-resolution color images as can be procured, assuming adequate server space for storage and delivery, and assuming sufficient staff to carry out the laborious process of scanning or photographing materials and making them available to users. A group of scholars who have sufficient resources (and who work with cooperative repositories) can create an edition of extraordinary depth and richness, an edition that provides both the evidence and the final product — a transcribed text and the images of the material they worked from in producing the edition. They can include audio and video clips, high-quality color reproductions of art works, and interactive maps. For multimedia artists such as William Blake and Dante Gabriel Rossetti the benefits are clear: much more adequate representation of their complex achievements. Likewise it is now possible to track and present in one convenient place the iconographic tradition of Don Quixote, a novel that has been repeatedly illustrated in ways rich with interpretive possibilities (<http://www.csdl.tamu.edu/cervantes/english/images_temp.html>). The non-authorial illustrations of this novel are part of the social text and provide an index to the culturally inscribed meanings of Cervantes' novel. Electronic editions have also deepened interest in the nature of textuality itself, thus giving the field of scholarly editing a new cachet.
The possibility of including so much and so many kinds of material makes the question of where and what is the text for an electronic edition every bit as vexed (if not more so) than it has been for print scholarship. For example, we might ask: what constitutes the text of an electronic version of a periodical publication? The Making of America project, collaboratively undertaken by Cornell University (<http://cdl.library.cornell.edu/moa/>) and the University of Michigan (<http://www.hti.umich.edu/m/moagrp/>), is a pioneering contribution of great value, but it excludes advertising, thereby implying that the authentic or real text of a periodical excludes this material of great importance for the study of history, popular culture, commerce, and so on.1 A similar disregard of the material object is seen also in editions that emphasize the intention of the writer over the actual documents produced. This type of edition has been praised, on the one hand, as producing a purer text, a version that achieves what a writer ideally wanted to create without the intervening complications of overzealous copy-editors, officious censors, sloppy compositors, or slips of the writer's own pen. For these intentionalist editors, any particular material manifestation of a text may well differ from what a writer meant to produce. On the other hand, the so-called "critical" editions they produce have been denigrated in some quarters as being ahistorical, as producing a text that never existed in the world. The long-standing debate between, say, critical and documentary editors won't be resolved because each represents a legitimate approach to editing.
A great deal of twentieth-century editing — and, in fact, editing of centuries before —as G. Thomas Tanselle notes, was based on finding an authoritative text based on "final intentions" (Tanselle 1995: 15–16). Ordinarily editors emphasized the intentions of the "author" (a contested term in recent decades) and neglected a range of other possible collaborators including friends, proofreaders, editors, and compositors, among others. A concern with final intentions makes sense at one level: the final version of a work is often stronger — more fully developed, more carefully considered, more precisely phrased — than an early or intermediate draft of it. But for poets, novelists, and dramatists whose work may span decades, there is real question about the wisdom of relying on last choices. Are people at their sharpest, most daring, and most experimental at the end of life when energies (and sometimes clarity) fade and other signs of age begin to show? Further, the final version of a text is often even more mediated by the concerns of editors and censors than are earlier versions, and the ability of anyone to discern what a writer might have hoped for, absent these social pressures, is open to question.
The long-standing concern with an author's final intentions has faced a significant challenge in recent years. Richard J. Finneran notes that the advent of new technologies "coincided with a fundamental shift in textual theory, away from the notion of a single-text 'definitive edition' " (Finneran 1996: x). Increasingly, editors have wanted to provide multiple texts, sometimes all versions of a text. Texts tend to exist in more than one version, and a heightened concern with versioning or fluidity is a distinctive trait of contemporary editing (Bryant 2002; Schreibman 2002: 287). Electronic editing allows us to avoid choosing, say, the early William Wordsworth or Henry James over the late. Even if there were unanimous agreement over the superiority of one period over another for these and other writers, that superiority would probably rest on aesthetic grounds open to question. And of course we often want to ask questions of texts that have nothing to do with the issue of the "best version."
New developments in electronic editing — including the possibility of presenting all versions of some especially valuable texts — are exciting, but anyone contemplating an electronic edition should also consider that the range of responsibilities for an editorial team has dramatically increased, too. The division of labor that was seen in print editing is no longer so well defined. The electronic scholarly edition is an enterprise that relies fundamentally on collaboration, and work in this medium is likely to stretch a traditional humanist, the solitary scholar who churns out articles and books behind the closed door of his office. Significant digital projects tend to be of a scope that they cannot be effectively undertaken alone, and hence collaborations with librarians, archivists, graduate students, undergraduate students, academic administrators, funding agencies, and private donors are likely to be necessary. These collaborations can require a fair amount of social capital for a large project, since the good will of many parties is required. Editors now deal with many issues they rarely concerned themselves with before. In the world of print, the appearance of a monograph was largely someone else's concern, and the proper functioning of the codex as an artifact could be assumed. With regard to book design, a wide range of options were available, but these choices customarily were made by the publisher. With electronic work, on the other hand, proper functionality cannot be assumed, and design choices are wide open. Collaboration with technical experts is necessary, and to make collaboration successful some knowledge of technical issues — mark-up of texts and database design, for example — is required. These matters turn out to be not merely technical but fundamental to editorial decision-making.
The electronic edition can provide exact facsimiles along with transcriptions of all manuscripts and books of a given writer. At first glance, it might be tempting to think of this as unproblematic, an edition without bias. Of course, there are problems with this view. For one thing, all editions have a perspective and make some views more available than others. An author-centered project may imply a biographical framework for reading, while a gender-specific project .
Even an inclusive digital archive is both an amassing of material and a shaping of it. That shaping takes place in a variety of places, including in the annotations, introductions, interface, and navigation. Editors are shirking their duties if they do not offer guidance: they are and should be, after all, something more than blind, values-neutral deliverers of goods. The act of not overtly highlighting specific works is problematic in that it seems to assert that all works in a corpus are on the same footing, when they never are. Still, there are degrees of editorial intervention; some editions are thesis-ridden and others are more inviting of a multitude of interpretations.
The idea of including everything in an edition is suitable for writers of great significance. Yet such an approach has some negative consequences: it can be seen as damaging to a writer (and might be seen as counterproductive for readers and editors themselves). In fact, the decision to include everything is not as clear a goal or as "objective" an approach as one might think. Just what is "everything," after all? For example, are signatures given to autograph hunters part of what is everything in a truly inclusive edition of collected writings? Should marginalia be included? If so, does it comprise only words inscribed in margins or also underlinings and symbolic notations? Should address books, shopping and laundry lists be included? When dealing with a prolific writer such as W. B. Yeats, editors are likely to ask themselves if there are limits to what all should be construed to be. What separates wisdom and madness in a project that sets out to represent everything?
This section started by asking why people are making electronic editions, and to some extent the discussion has focused on the challenges of electronic editing. I would argue that these very challenges contribute to the attraction of working in this medium. At times there is a palpable excitement surrounding digital work stemming in part from the belief this is a rare moment in the history of scholarship. Fundamental aspects of literary editing are up for reconsideration: the scope of what can be undertaken, the extent and diversity of the audience, and the query potential that —through encoding — can be embedded in texts and enrich future interpretations. Electronic editing can be daunting — financially, technically, institutionally, and theoretically — but it is also a field of expansiveness and tremendous possibility.
Digital Libraries and Scholarly Editions
It is worthwhile to distinguish between the useful contributions made by large-scale digitization projects, sometimes referred to as digital library projects, and the more fine-grained, specialized work of an electronic scholarly edition. Each is valuable, though they have different procedures and purposes. The Wright American Fiction project can be taken as a representative digital library project
This ambitious undertaking has been supported by a consortium of Big Ten schools plus the University of Chicago. As of September 2005 (the most recent update available) nearly half the texts were fully edited and encoded; the rest were unedited. "Fully edited" in this context means proofread and corrected (rather than remaining as texts created via optical character recognition (OCR) with a high number of errors). The "fully edited" texts also have SGML tagging that enables better navigation to chapter or other divisions within the fiction and links from the table of contents to these parts. Not surprisingly, Wright American Fiction lacks scholarly introductions, annotations, and collation of texts. Instead, the collection is made up of full-text presentations of the titles listed in Lyle Wright's American Fiction 1851–1875: A Contribution Toward a Bibliography (1957; rev. 1965). The texts are presented as page images and transcriptions based on microfilm originally produced by a commercial firm, Primary Source Media. It is telling that the selection of texts for Wright American Fiction was determined by a pre-existing commercial venture and was not based on finding the best texts available or by creating a fresh "critical" edition. The latter option was no doubt a practical impossibility for a project of this scale. In contrast to Wright American Fiction's acceptance of texts selected and reproduced by a third party, the editor of a scholarly edition would take the establishment of a suitable text to be a foundational undertaking. Moreover, as the MLA "Guidelines for Editors of Scholarly Editions" indicate, any edition that purports to be scholarly will provide annotations and other glosses.
Wright American Fiction, in a nutshell, has taken a useful bibliography and made it more useful by adding the content of the titles Wright originally listed. One might think of the total record of texts as the great collective American novel for the period. Wright American Fiction has so extended and so enriched the original print bibliography that it has become a fundamentally new thing: the difference between a title and a full text is enormous. As a searchable collection of what approaches the entirety of American fiction for a period, Wright American Fiction has a new identity quite distinct from, even if it has its basis in, the original printed volume.
Wright American Fiction's handling of Harriet Jacobs (listed by her pseudonym Linda Brent) demonstrates some of the differences between the aims of a digital library project and a scholarly edition. The key objective of Wright American Fiction has been to build a searchable body of American fiction. Given that between the creation of the bibliography and the creation of the full-text electronic resource, an error in the original bibliography has been detected (a work listed as fiction has been determined not be fictional), it seems a mistaken policy to magnify the error by providing the full text of a non-fictional document. Incidents in the Life of a Slave Girl was listed as fiction by the original bibliographer, Lyle Wright — at a time when Jacobs's work was thought to be fictional — and it remains so designated in the online project even though the book is no longer catalogued or understood that way. This would seem to be a mechanical rather than a scholarly response to this particular problem. The collection of texts in the Wright project is valuable on its own terms, but it is different from an edition where scholarly judgment is paramount. Wright American Fiction consistently follows its own principles, though these principles are such that the project remains neutral on matters where a scholarly edition would be at pains to take a stand. Wright American Fiction is a major contribution to scholarship without being a scholarly edition per se.
In contrast to the digital library collection, we also see a new type of scholarly edition that is often a traditional edition and more, sometimes called a thematic research collection. Many thematic research collections — also often called archives —aim toward the ideal of being all-inclusive resources for the study of given topics. In an electronic environment, it is possible to provide the virtues of both a facsimile and a critical or documentary edition simultaneously. G. Thomas Tanselle calls "a newly keyboarded rendition (searchable for any word)" and "a facsimile that shows the original typography or handwriting, lineation, and layout … the first requirement of an electronic edition" (1995: 58). A facsimile is especially important for those who believe that texts are not separable from artifacts, that texts are fundamentally linked to whatever conveys them in physical form. Those interested in bibliographic codes —how typeface, margins, ornamentation, and other aspects of the material object convey meaning — are well served by electronic editions that present high-quality color facsimile images of documents. Of course, digital facsimiles cannot convey every physical aspect of the text — the smell, the texture, and the weight, for example.
An additional feature of electronic editions deserves emphasis — the possibility of incremental development and delivery. If adequate texts do not exist in print then it is often advisable to release work-in-progress. For example, if someone were to undertake an electronic edition of the complete letters of Harriet Beecher Stowe, it would be sensible to release that material as it is transcribed and annotated since no adequate edition of Stowe's letters has been published. It has become conventional to release electronic work before it reaches fully realized form, and for good reason. Even when a print edition exists, it can be useful to release electronic work-in-progress because of its searchability and other functionality. Of course, delivering work that is still in development raises interesting new questions. For example: when is an electronic edition stable? And when is it ready to be ingested into a library system?
Electronic editing projects often bring into heightened relief a difficulty confronted by generations of scholarly editors. As Ian Donaldson argues in "Collecting Ben Jonson," "The collected edition [a gathering of the totality of a writer's oeuvre, however conceived] is a phrase that borders upon oxymoron, hinting at a creative tension that lies at the very heart of editorial practice. For collecting and editing —gathering in and sorting out — are very different pursuits, that often lead in quite contrary directions" (Donaldson 2003: 19). An "electronic edition" is arguably a different thing than an archive of primary documents, even a "complete" collection of documents, and the activities of winnowing and collecting are quite different in their approaches to representation. Is a writer best represented by reproducing what may be most popular or regarded as most important? Should an editor try to capture all variants of a particular work, or even all variants of all works? As Amanda Gailey has argued, "Each of these editorial objectives carries risks. Editors whose project is selection threaten to oversimplify an author's corpus, [and to] neglect certain works while propagating overexposed ones … Conversely, editors who seek to collect an author's work, as Donaldson put it, risk 'unshap[ing] the familiar canon in disconcerting ways"' (2006: 3).
Unresolved Issues and Unrealized Potentials
Much of what is most exciting about digital scholarship is not yet realized but can be glimpsed in suggestive indicators of what the future may hold. We are in an experimental time, with software and hardware changing at dizzying speeds and the expectations for and the possibilities of our work not yet fully articulated. Despite uncertainty on many fronts, one thing is clear: it is of the utmost importance that electronic scholarly editions adhere to international standards. Projects that are idiosyncratic are almost certain to remain stand-alone efforts: they have effectively abandoned the possibility of interoperability. They cannot be meshed with other projects to become part of larger collections and so a significant amount of the research potential of electronic work is lost. Their creators face huge barriers if they find they want to integrate their work with intellectually similar materials. As Marilyn Deegan remarks, "Interoperability is difficult to achieve, and the digital library world has been grappling with it for some time. Editors should not strive to ensure the interoperability of their editions but make editorial and technical decisions that do not preclude the possibility of libraries creating the connections at a later date" (Deegan 2006: 362). Deegan perceives that tag sets such as the Text Encoding Initiative (TEI) and Encoded Archival Description (EAD) make possible interoper-ability, though they do not guarantee it. Figuring out how to pull projects together effectively will be a challenging but not impossible task. We face interesting questions: for example, can we aggregate texts in ways that establish the necessary degree of uniformity across projects without stripping out what is regarded as vital by individual projects? An additional difficulty is that the injunction to follow standards is not simple because the standards themselves are not always firmly established.
Many archivists refer to eXtensible Markup Language (XML) as the "acid-free paper of the digital age" because it is platform-independent and non-proprietary. Nearly all current development in descriptive text markup is XML-based, and far more tools (many of them open-source) are available for handling XML data than were ever available for SGML. Future versions of TEI will be XML-only, and XML search engines are maturing quickly. XML and more particularly, the TEI implementation of XML, has become the de facto standard for serious humanities computing projects. XML allows editors to determine which aspects of a text are of interest to their project and to "tag" them, or label them with markup. For example, at the Whitman Archive, we tag structural features of the manuscripts, such as line breaks and stanza breaks, and also the revisions that Whitman made to the manuscripts, as when he deleted a word and replaced it with another. Our markup includes more information than would be evident to a casual reader. A stylesheet, written in Extensible Stylesheet Language Transformations (XSLT), processes our XML files into reader-friendly HTML that users see when they visit our site. A crucial benefit of XML is that it allows for flexibility, and the application of XSLT allows data entered once to be transformed in various ways for differing outputs. So while some of the information that we have embedded in our tagging is not evident in the HTML display, later, if we decide that the information is valuable to readers, we can revise our stylesheet to include it in the HTML display.
The combination of XML-encoded texts and XSLT stylesheets also enables projects to offer multiple views of a single digital file. This is of considerable importance in scholarly editing because editors (or users) may want to have the same content displayed in various ways at different times. For example, the interface of the expanded, digital edition of A Calendar of the Letters of Willa Cather, now being prepared by a team led by Andrew Jewell, will allow users to dynamically reorder and index over 2,000 letter descriptions according to different factors, such as chronology, addressee, or repository. Additionally, the Cather editorial team is considering giving users the option of "turning on" some of the editorial information that is, by default, suppressed. In digitizing new descriptions and those in Janis Stout's original print volume, such data as regularized names of people and titles often takes the form of a mini-annotation. In the digital edition, the default summary might read something like, "Going to see mother in California"; with the regularization visible, it might read, "Going to see mother [Cather, Mary Virginia (Jennie) Boak] in California."
These multiple views of the Calendar are enabled by the rich markup adopted by this project and point to some of the issues that editors must consider. Even while adhering to the same TEI standard used on many other digital editing projects, these editors' choices of which textual characteristics to mark up may nonetheless differ significantly from choices made by other project editors. When an effort is made to aggregate material from The Willa Cather Archive (<http://cather.unl.edu>) with that of other comparable sites, how will differences in markup be handled? Of course, unless projects make their source code available to interested scholars and expose their metadata for harvesting in accordance with Open Archives Initiative (OAI) protocols, it won't be easy now or in the future even to know what digital objects make up a given edition or how they were treated.
Clearly, then, issues of preservation and aggregation are now key for editors. In looking toward the future, the Whitman Archive is attempting to develop a model use of the Metadata Encoding and Transmission Standard (METS) for integrating metadata in digital thematic research collections. A METS document enables the Whitman Archive —and all entities that subsequently ingest the Whitman materials into larger collections —to describe administrative metadata, structural metadata, and descriptive metadata. For example, the Whitman Archive uses thousands of individual files in our project to display transcriptions and digital images of Whitman's manuscripts and published works. These files — TEI-encoded transcriptions, archival TIFF images, derived JPEG images, EAD finding guides — could be more formally united through the use of a METS document to record their specific relationships. The use of METS will help preserve the structural integrity of the Whitman Archive by recording essential relationships among the files. Additionally, we think that using METS files which adhere to a proper profile will promote accessibility and sustainability of the Archive and other projects like it, making them prime candidates for ingestion into library collections.
The proper integration of metadata is important because large sites are likely to employ more than one standard, as the example of the Walt Whitman Archive suggests. Redundant data is at least a workflow problem when it involves unnecessary labor. There is also the matter of figuring out what the canonical form of the metadata is. Currently, no METS Profile for digital thematic research collections has been developed, and there has not been a demonstration of the effectiveness of METS as an integration tool for such collections. In a report to the UK Joint Information Systems Committee, Richard Gartner argues that what prohibits "the higher education community [from] deriving its full benefit from METS is the lack of standardization of metadata content which is needed to complement the standardization of format provided by METS" (Gartner 2002). Specifically, he calls for new work to address this gap so that the full benefits of METS can be attained. In short, practices need to be normalized by user communities and expressed in detailed and precise profiles if the promise of METS as a method for building manageable, sustainable digital collections is to be realized.
Researchers and librarians are only just beginning to use the METS standard, so the time is right for an established humanities computing project, like the Whitman Archive, to develop a profile that properly addresses the complicated demands of scholar-enriched digital documents. In fact, a grant from the Institute for Museum and Library Services is allowing the Whitman Archive to pursue this goal, with vital assistance from some high-level consultants.2
Cost
A significant amount of scholarly material is now freely available on the web, and there is a strong movement for open access. As I have observed elsewhere, scholarly work may be free to the end user but it is not free to produce (Price 2001: 29). That disjunction is at the heart of some core difficulties in digital scholarship. If one undertakes a truly ambitious project, how can it be paid for? Will granting agencies provide editors the resources to make costly but freely delivered web-based resources?
The comments of Paul Israel, Director and General Editor of the Thomas A. Edison Papers, highlight the problem; his comments are all the more sobering when one recalls that the Edison edition recently was honored with the Eugene S. Ferguson Prize as an outstanding history of technology reference work:
It is clear that for all but the most well funded projects online editions are prohibitively expensive to self publish. The Edison Papers has been unable to fund additional work on our existing online image edition. We have therefore focused on collaborating with others. We are working with the Rutgers Library to digitize a small microfilm edition we did of all extant early motion picture catalogs through 1908, which we are hoping will be up later this year. The library is doing this as part of a pilot project related to work on digital infrastructure. Such infrastructure rather than content has been the focus [of] funding agencies that initially provided funding for early digital editions like ours. We are also now working with the publisher of our book edition, Johns Hopkins University Press, to do an online edition of the book documents with links to our image edition. In both cases the other institution is both paying for and undertaking the bulk of the work on these electronic editions.
(Israel 2006)
Over recent decades, grant support for the humanities in the US has declined in real dollars. By one estimate, "adjusted for inflation, total funding for NEH is still only about 60% of its level 10 years ago and 35% of its peak in 1979 of $386.5 million" (Craig 2006). If development hinges on grant support, what risks are there that the priorities of various agencies could skew emphases in intellectual work? Some have worried about a reinstitution of an old canon, and others have expressed concern about the possible dangers of political bias in federally awarded grants. Some worry that canonical writers may be more likely to be funded by federal money and that writers perceived to be controversial might be denied funding.
One possible strategy for responding to the various funding pressures is to build an endowment to support a scholarly edition. The National Endowment for the Humanities provides challenge grants that hold promise for some editorial undertakings. One dilemma, however, is that the NEH directs challenge grants toward support of institutions rather than projects — that is, toward ongoing enterprises rather than those of limited duration. Thus far, some funding for editorial work has been allocated via "We the People" challenge grants from NEH, but this resource has limited applicability because only certain kinds of undertakings can maintain that they will have ongoing activities beyond the completion of the basic editorial work, and only a few can be plausibly described as treating material of foundational importance to US culture.3
Presses and Digital Centers
University presses and digital centers are other obvious places one might look for resources to support digital publication, and yet neither has shown itself to be fully equipped to meet current needs. Oxford University Press, Cambridge University Press, and the University of Michigan Press all expressed interest in publishing electronic editions in the 1990s, though that enthusiasm has since waned. On the whole, university presses have been slow to react effectively to the possibilities of electronic scholarly editions. University presses and digital centers have overlapping roles and interests, and there may well be opportunities for useful collaborations in the future, and some collaborations have already been effective. Notably, it was the Institute for Advanced Technology in the Humanities (IATH), under John Unsworth's leadership, that secured grant funding and internal support for an electronic imprint, now known as Rotunda, at the University of Virginia Press. It is too early to tell whether or not the Electronic Imprint at the University of Virginia will flourish — either way it is already an important experiment.
Digital Centers such as IATH, the Maryland Institute for Technology in the Humanities (MITH), and the Center for Digital Research in the Humanities at the University of Nebraska—Lincoln (CDRH) in a sense have been acting as publishers for some of their projects, though they are really research and development units. They ordinarily handle some publisher functions, but other well-established parts of the publishing system (advertising, peer review, cost-recovery) are not at the moment within their ordinary work. Nor are these units especially suited to contend with issues of long-term preservation. They can nurture projects with sustainability in mind, but the library community is more likely to have the people, expertise, and the institutional frameworks necessary for the vital task of long-term preservation. As indicated, many scholars promote open access, but not all of the scholarship we want to see developed can get adequate support from universities, foundations, and granting agencies. Presses might one day provide a revenue stream to support projects that cannot be developed without it. What we need are additional creative partnerships that build bridges between the scholars who produce content, the publishers who (sometimes) vet and distribute it, and the libraries who, we hope, will increasingly ingest and preserve it. A further challenge for editors of digital editions is that this description of roles suggests a more clearly marked division of responsibilities than actually exists. Traditional boundaries are blurring before our eyes as these groups —publishers, scholars, and librarians — increasingly take on overlapping functions. While this situation leaves much uncertainty, it also affords ample room for creativity, too, as we move across newly porous dividing lines.
Audience
Having the ability, potentially, of reaching a vast audience is one of the great appeals of online work. Most of us, when writing scholarly articles and books, know we are writing for a limited audience: scholars and advanced students who share our interests. Print runs for a book of literary criticism are now rarely more than 1,000 copies, if that. A good percentage of these books will end up in libraries, where fortunately a single volume can be read over time by numerous people. In contrast, an online resource for a prominent writer can enjoy a worldwide audience of significant size. For example, during the last two months of the past academic year (March — April 2006), The Willa Cather Archive averaged about 7,700 hits a day, or about 230,000 hits a month. In that period, there was an average of 7,639 unique visitors a month. The Journals of the Lewis and Clark Expedition (<http://lewisandclarkjournals.unl.edu>), which, interestingly, has numbers that correspond less to the academic year, had its peak period of the last year during January—March 2006. For those three months, Lewis and Clark averaged 188,000 hits a month (about 6,300 hits a day), and an average of 10,413 unique visitors a month.
In the past the fate of the monumental scholarly edition was clear: it would land on library shelves and, with rare exceptions, be purchased only by the most serious and devoted specialists. Now a free scholarly edition can be accessed by people all over the world with vastly different backgrounds and training. What assumptions about audience should the editors of such an edition make? This is a difficult question since the audience may range widely in age and sophistication and training, and the answer of how best to handle the complexity is unclear. A savvy interface designer on a particular project might figure out a way to provide levels of access and gradations of difficulty, but unless carefully handled, such an approach might seem condescending. Whatever the challenges are of meeting a dramatically expanded readership — and those challenges are considerable — we should also celebrate this opportunity to democratize learning. Anyone with a web browser has access, free of charge, to a great deal of material that was once hidden away in locked-up rare-book rooms. The social benefit of freely available electronic resources is enormous.
Possible Future Developments
Future scholarship will be less likely than now to draw on electronic archives to produce paper-based scholarly articles. It seems likely that scholars will increasingly make the rich forms of their data (rather than the HTML output) open to other scholars so that they can work out of or back into the digital edition, archive, or project. An example may clarify how this could work in practice. The Whitman Archive, in its tagging of printed texts, has relied primarily on non-controversial markup of structural features. Over the years, there have been many fine studies of Leaves of Grass as a "language experiment." When the next scholar with such an interest comes along, we could provide her with a copy of, say, "Song of Myself" or the 1855 Leaves to mark up for linguistic features. This could be a constituent part of her own free-standing scholarly work. Alternatively, she could offer the material back to the Archive as a specialized contribution. To take another example, in our own work we have avoided thematic tagging for many reasons, but we wouldn't stand in the way of scholars who wished to build upon our work to tag Whitman for, say, racial or sexual tropes.
Translation
In an intriguing article, "Scales of Aggregation: Prenational, Subnational, Transnational," Wai Chee Dimock points out that "humanistic fields are divided by nations: the contours of our knowledge are never the contours of humanity." She further notes that
nowhere is the adjective American more secure than when it is offered as American literature; nowhere is it more naturalized, more reflexively affirmed as inviolate. American literature is a self-evident field, as American physics and American biology are not. The disciplinary form of the humanities is "homeland defense" at its deepest and most unconscious.
(Dimock 2006: 223)
We might be able to adjust our fields of inquiry if we, through editorial work on translations, highlighted the limitations of "humanistic fields … divided by nations." For example, we could approach Whitman via a social text method — where versions produced by non-US societies are key objects of interest. The remaking of a writer to suit altered cultural contexts is a rich and largely untapped field of analysis. A truly expansive electronic edition — one more expansive than any yet realized — could make this possibility a reality.
Whitman said to one of his early German translators: "It has not been for my country alone — ambitious as the saying so may seem — that I have composed that work. It has been to practically start an internationality of poems. The final aim of the United States of America is the solidarity of the world One purpose of my chants is to cordially salute all foreign lands in America's name" (quoted in Folsom 2005: 110). As Ed Folsom has remarked, Whitman "enters most countries as both invader and immigrant, as the confident, pushy, overwhelming representative of his nation … and as the intimate, inviting, submissive, endlessly malleable immigrant, whose work gets absorbed and rewritten in some surprising ways" (Folsom 2005: 110–11). Scholarly editions, especially with the new possibilities in their electronic form, can trouble the nationally bounded vision so common to most of us.
In the near future, the Walt Whitman Archive will publish the first widely distributed Spanish language edition of Leaves of Grass. One of our goals is to make a crucial document for understanding Whitman's circulation in the Hispanophone world available, but an equally important goal is to make available an edition that will broaden the audience for the Archive, both in the US and abroad, to include a huge Spanish-speaking population. Foreign-language editions of even major literary texts are hard to come by online, and in many cases the physical originals are decaying and can barely be studied at all.4 Translations and other "responses" (artistic, literary) can be part of a digital scholarly edition if we take a sociological view of the text. In this social text view a translation is seen as a version. The translation by Á lvaro Armando Vasseur that we are beginning with is fascinating as the work of a Uruguayan poet who translated Whitman not directly from English but via an Italian translation (apparently Luigi Gamberale's 1907 edition), and our text is based on the 1912 F. Semper issue. These details are suggestive of the development of a particular version of modernism in South America, and of the complex circulation of culture.
The translation project serves as an example of the expansibility of electronic editions. Electronic work allows an editor to consider adding more perspectives and materials to illuminate texts. These exciting prospects raise anew familiar issues: who pays for expansive and experimental work? Given that not all of the goals imaginable by a project can be achieved, what is the appropriate scope and what are the best goals? Scholars who create electronic editions are engaged in the practice of historical criticism. Editing texts is a way to preserve and study the past, to bring it forward into the present so that it remains a living part of our heritage. How we answer the difficult questions that face us will to a large extent determine the past we can possess and the future we can shape.
Notes
1 It could be argued that the Making of America creators didn't so much make as inherit this decision. That is, librarians and publishers made decisions about what was important to include when issues were bound together into volumes for posterity. One could imagine a project less given to mass digitization and more devoted to the state of the original material objects that would have searched more thoroughly to see how much of the now "lost" material is actually recoverable.
2 Daniel Pitti, Julia Flanders, and Terry Catapano.
3 The Whitman Archive is addressing the question of cost by building an endowment to support ongoing editorial work. In 2005 the University of Nebraska—Lincoln received a $500,000 "We the People" NEH challenge grant to support the building of a permanent endowment for the Walt Whitman Archive. The grant carries a 3 to 1 matching requirement, and thus we need to raise $1.5 million dollars in order to receive the NEH funds. The Whit-man Archive is the first literary project to receive a "We the People" challenge grant. What this may mean for other projects is not yet clear. In a best-case scenario, the Whitman Archive may use its resources wisely, develop a rich and valuable site, and help create a demand for similar funding to support the work of comparable projects.
4 A Brazilian scholar, Maria Clara Bonetti Paro, recently found that she needed to travel to the Library of Congress in order to work with Portuguese translations of Leaves of Grass because the copies in the national library in Brazil were falling apart and even scholars had only limited access to them.
Writing Machines
Writing
Writing in a new key
It has been the fleets of humming word processors, not the university mainframe computers nor the roaring newspaper printing presses of the turn of the nineteenth century, that have drawn humanists to writing machines and their industrialized texts (Winder 2002). We write perhaps less and less, but we process more and more, with computers working quietly in the background. And only in the dead silence of a computer crash where hours of work have disappeared do we understand clearly how much our writing depends on machines. Formatters, spell checkers, thesauri, grammar checkers, and personal printers support our writing almost silently. Yet we suspect that today's ubiquitous editing and display functions will seem quaint in ten years' time, perhaps as quaint and mysterious as the thump of a typewriter's carriage shift.
Computers are necessarily writing machines. When computers process words, they generate text and a great deal of it. Library catalogues over the globe spew out countless replies to queries (author, keyword, call number, title, subject heading, year, language, editor, series, …); banking machines unabashedly greet us, enquire discreetly about our password in hushed tones, and remind us not to leave our banking card in the machine when we leave (would you like a receipt?). From the internet come waves of pages crafted for each visitor's communicative needs. Computers, however much they calculate, write even more relentlessly.
But are computers typists or writers? We can understand the constant growth of writing, by or through computers, as the effect of two complementary cultural compulsions, each tunneling toward the other from opposing positions and destined to meet ultimately somewhere in an unknown middle ground. The first driving force is the grassroots improvement of computer-assisted writing; the second is artificial intelligence.
From the "accelerated writing" paradigm will come the next generation of word processors — true text processors — that will give us advanced tools for automatic generation of text. The computer is much too powerful to remain a simple word processor, offering only word changes such as spelling and thesaurus functions; it can do much more, such as understanding text well enough to propose radical changes in composition.
Tools for boilerplate construction are good candidates for the text processor of the near future. If I write a reference letter for one student, Sarah, and then have another student, Ralph, who followed much the same program of study and requires a letter as well, I might cut and paste relevant parts of Sarah's letter into Ralph's. At present I would have the tedious task of making sure all occurrences of "Sarah" are replaced by "Ralph" and that no "she" referring to Sarah is left in the pasted text. The text processor of the future should check the coherence of my discourse and transform the pasted text for me automatically, just as even now grammar checkers automatically suggest changes for agreement between verbs and their subjects. In many languages, such text transformations would not be trivial at all: in French it would require changing all the numerous gender agreements ("son professeur de mathématiques l'a décrite comme une bonne étudiante"); in English, though simpler, it might mean transforming gender-specific adjectives or nouns ("pretty"/"handsome," "waiter"/ "waitress") and possessive adjectives ("him," "his"). At present, crude search and replace functions lead to embarrassing slips: in one republished thesis all the occurrences of "thesis" had been replaced with "book," even in the case of "hypothesis," which became the curious neologism "hypobook" throughout the published text.
Creating texts in this accelerated writing paradigm is more about writing text-generating code and using functions that recycle texts into boilerplate components than it is about writing any of the final versions themselves. Separation of content and form is a standard approach for some editing software such as Tex and bibliographic software that generates citations and bibliography. The new text processor will extend this approach by becoming a spreadsheet equivalent for writing: instead of cutting and pasting blocks of text, we will cut and paste text formulae that generate programmatically the final text (see the discussion of a "textual Excel" in Winder forthcoming). We find the infrastructure for this coded text in present-day applications such as automatic translation (increasingly online, such as Babel Fish), formalisms developed in text encoding projects (Unicode standard, Text Encoding Initiative), and programming languages that are increasingly closer to human language (Perl, Ruby, Python; see Malsky 2006, chapter 3, "Language and I MEAN Language"1).
The other, complementary orientation does not have as its goal an incremental enhancement of writers' tools; rather, the goal of the artificial intelligence approach is to construct directly the components of a writing intelligence — machines that have personality and thoughts like humans, not unlike the robots we know from science fiction.
These two projects, accelerated writing and artificial intelligence, seem destined to meet. Writers will become increasingly wedded to programming, to code-generating programmer tools (such as databases and version control), and to the industrial production of text, on the one hand, and computers will become increasingly human on the other.
But there is a third paradigm, a third perspective, less overtly commercial, but perhaps just as focused on that eventual meeting of minds and machines as the first two: automatic generation of art. What is most human is not just the body's artifacts (enhanced by the versatile printing of the accelerated writing paradigm) nor the calculating mind (studied and re-created in artificial intelligence), but as well that elusive creative spirit that traverses all our endeavors. These three orientations are destined to meet because human value ultimately has its source in precisely what is peculiarly human: a certain confluence of mind, body, and spirit.
Our focus here is on automatically produced written art. This is clearly a narrow view of how people communicate in the electronic medium (by definition a multi-media environment) and a radical reduction of the field of generated art. Written language has, however, a singular place in computational systems, if only because writing and reading program code is a faculty shared by both human programmers and computers. As well, generation is perhaps best defined as a reading out of instructions. Printing, as the ultimate and most general reading and writing out of instructions, is where writing, thinking, and creating converge (Winder 2004: 449).
Printing, writing, and art
Printing and writing are clearly related. Like printing, writing is machine-mediated language, though the machine may be as simple as a pencil. (Is there writing without printing?) And though we may understand writing as something more than printing, it is often not clear what precisely distinguishes the two. Such is the point that Plato brings home in Socrates's retelling of the myth of the birth of writing. Theuth invents writing as a remedy for memory loss, as if the mind could extend to the page. Thamus, the king of the gods, claims that Theuth's invention is not a tonic for memory but rather a poison, the death of the mind (see the Perseus library (Crane 2006) for Phaedrus; discussion in Derrida 1992). Socrates debates the question of the soul of discourse that writing is supposed to capture, that precise place where discourse takes on its own life. He finds there something we will call art.
The word "art" has many meanings, which reflect that same liveliness of meaning we find in artistic objects themselves:
• Mercantile art: The "pricelessness" of art reflects the fact that it is not produced in the same way as other commercial products (the value of the means of production is not commensurate with the value of the artistic object) and thus art seems to belong to an entirely different economy (the slogan "art for art's sake" is perhaps a reflection of that otherness of art). It is also other in that its uniqueness is seemingly borrowed from the uniqueness and pricelessness of the very life of the artist. Within the commercial system, art is arbitrary because ultimately everything is tied to a unique human existence; anything can be bought and sold as art (witness the "readymade" art of Marcel Duchamp).
• Inspirational art: The "liveliness" of art lies in an overabundance made possible by a surprising efficiency, an efficiency (analogous to Freud's economy principle for wit) that does not make sense with respect to the mercantile economy. For example, Francis Ponge 1999: (346) notes that the French word "oiseau" contains all the vowels (such poetic "trouvailles" generally do not translate; the word in Spanish with all the vowels, written and pronounced, is "murciélago", bat). This is a surprising efficiency in the sense that the otherwise arbitrary word for bird seems to reflect the vocal dimension of its object: a bird is in fact a "vowel" creature. The artistic reflex we cultivate and from which derive a feeling of joy, freedom, generosity, and community, is to recognize and cultivate this "graceful" dimension of the universe, a grace that seems to conspire to harmonize the world in an abundant, costless economy. The artistic vision, as a lay version of the religious experience, adds a layer of meaning that harmonizes the way things are. In the artistic world, nothing is arbitrary, nothing is without meaning, and everything is given freely — if not, it would not be art, it would not be grace. Inspirational art is therefore not arbitrary, but rather motivated by the surprising generosity of the world.
• Living art: Art is not only lively, it is "alive" in that, like a living organism, it assimilates other forms of art, adapts itself to new environments, and reproduces itself in derivative works. Unlike living things, however, art has no "fixed address." It does not need any particular material envelope and by nature tends to bleed into all things at all levels of organization, including the spectator. An artistic organization such as Shakespearean style can find itself just as easily in a play as in a novel, in a style of dress, or in a person. Art is universal form.
As a universal principle of combination, art's most general aesthetic effect is a feeling of vivifying inclusion — connectedness — that attaches the spectator to the grace (costless harmony) of the world. The artistic text must be coherent and alive at the same time. It is an adaptive structure that is stubbornly the same in spite of the constant changing or shimmering of its being. Art is both process and product: through art we capture open-ended productivity (generation) in a closed system (product).
The question we must deal with here is the relation between artful generation and machines. Just as Socrates concluded that writing is discourse without a soul, so we might suspect that machines are writers without creativity. What is artful generation? How do machines simulate, at least, generation? Is there a special kind of artistic generation? A special use of technique?
Transmutations: things that go generate in the night
Criticizing a poorly organized discourse, Socrates points out that the lines of Midas's epitaph, delivered by the bronze statue of a maiden and reported in Plato's text, can be read in any order:
Bronze maiden am I and on Midas's mound I lie.
As long as water flows and tall trees bloom,
Right here fixed fast on the tearful tomb,
I shall announce to all who pass near: Midas is dead and buried here.
(Phaedrus 264d; cited and translated in Carson 1986: 134)
How many permutations are there and do they all truly make sense? (There are n! permutations of n things. Here there are 4 sentences and therefore 4! permutations: 4*3*2*1 = 24 altogether.) Does Socrates know how many there really are? Did he actually generate all permutations (etched in stone? on "papyrus"? in his head?) or can he simply "tell" from each sentence? Are some better than others? How are we to judge?
We can generate all of the permutations easily enough (see Winder 2006, Robotic Poetics, for an online generator), but are there not many more "versions" we might want to consider? For instance, the original Greek is certainly a version:

And the transliterated Greek:
chalkê parthenos eimi, Mida d' epi sêmati keimai.
ophr' an hudo êr te naêi kai dendrea makra tethêlêi,
autou têide menousa poluklautou epi tumbou,
angeleo ê pariousi Midas hoti têide tethaptai.
("Phaedrus" 264d3)
And perhaps we should even consider the Greek transliteration of the English translation of the Greek!:

The latter is generated simply by a switch of fonts in a word processor (see Balpe "Imagination" 16–18). Word processors have a "Midas touch" we are all familiar with (whether they produce gold or not is another question). Text is malleable; one text can be transformed into another; the same thing can be said in different ways. Here is the same English epitaph in the BookDings font:

JanusNode (Westbury) has an "ee cummings" mode, along with a sophisticated generation scripting language (see below), which will lay out a text in an ee cummings fashion:
Bronze maiden
am
I
and
on Midas' mound
I lie.
As
long as water flows
and tall
trees bloom,
Right
here
fixed fast on
the tearful
tomb,
I
sh
all announce
to
all
who
pass
near:
Midas
is
dead
and
buried
here.
( JanusNode "ee cummings" style)
Such transmutations are perhaps not of themselves art, but they are certainly starting points of creativity. Whether automatic or human, transmutation is most often simply the source of humor and obfuscation. Luis d'Antin van Rooten's Mots d'heures: Gousses, Rames are phonetic transliterations of English "Mother Goose rhymes" into French, which he then presents, with "serious" exegesis, as a critical edition of a collection of medieval French verse. Here is "Humpty Dumpty":
Un petit d'un petit
S'étonne aux Halles
Un petit d'un petit
Ah! degrés te fallent [3]
Indolent qui ne sort cesse
Indolent qui ne se mène
Qu'importe un petit d'un petit
Tout Gai de Reguennes.
("Poem 1")
Exegesis is given in copious footnotes to this "medieval" poem; here is the third annotation [3], an interpretation of line 4:
Since this personage [the "petit," offspring of the child marriage ("d'un petit") mentioned in the first line] bears no titles, we are led to believe that the poet writes of one of those unfortunate idiot-children that in olden days existed as a living skeleton in their family's closet. I am inclined to believe, however, that this is a fine piece of misdirection and that the poet is actually writing of some famous political prisoner, or the illegitimate offspring of some noble house. The Man in the Iron Mask, perhaps? ("Poem 1", note 3; pages unnumbered)
Russell Horban makes use of the prolific number of graphemes in English (1,120 graphemes for 40 sounds; compared with Italian, which has 33 graphemes for 25 sounds) to transliterate present-day English into a futuristic newspel: "What ben makes tracks for what wil be. Words in the air pirnt foot steps on the groun for us to put our feet in to" (121). In Dunn's Ella Minnow Pea letters of the alphabet are progressively banned from all writings and the eponymous protagonist is reduced to expressing herself in baby talk — "No mo Nollop poo poo!" ["No more Nollop mess"] — and signing her name as "LMNOP" (2001: 197).
Transliteration in a more practical vein is found in spelling reform projects such as Truespel. The online Truespel Converter transforms our epitaph into:
Braanz maedin am Ie and aan Miedis's mound Ie lie.
Az laung az wauter floez and taul treez bluem,
Riet heer fiksd fast aan thu teerfool tuem,
Ie shal unnounts tue aul hue pas neer: Miedis iz ded and baireed heer.
(Davidson 2006)
Transmuted versions proliferate in the machine (the Unicode specification for character sets has over 232 possible characters). Word processors can transmute text so effectively because each character is represented by a specific number or "code point" that can be mapped to any other code point. All word processor text is represented in fundamentally the same way: a set of points that can be dressed up in different font garb. Underlying the word processor's transmutations and Socrates's permutations is a very abstract machine, the fundamental machine of transmutation, a mapping between code points: a permutation is a mapping of one line onto another (for instance, mapping line 1 to 2 and line 2 to 1 gives one combination); a symbol transmutation is a mapping of one alphabet onto another.
Topographies for Transmutation
For mapping to be coherent, automatic techniques depend on the formally described topographies of the source and target texts. Beyond characters, more important linguistic topographies are syntax, lexical meaning, and narrative. Each of these dimensions brings with it its own processing difficulties. We will look at each in turn.
One fundamental method of generation is through syntactic templates, essentially the boilerplate texts of word processors. Any number of variant epitaphs can be generated by substituting equivalent terms at appropriate positions in the text (Table 27.1).
This "combinatory of combinations" codes for 46 sentences, for a total of 4,096. Here all the combinations are acceptable, but generally syntactic and perhaps semantic constraints will be limiting factors (see Winder 2004: 458ff and the Robotic Poetics site). As syntactic constraints are reduced, generation becomes increasingly simple. Divinatory systems, such as I Ching, are typically built on units that combine freely, with few or no syntactic constraints: a single narrative unit is attached to each free combination of rods. There are no natural languages that are combinatorially complete in this way, i.e., not all combinations of words make grammatical utterances. Even declined languages like Latin, which have very flexible word order, require a particular mix of nouns and verbs. Perhaps only artificial languages such as I Ching can achieve the ideal of a combinatorially complete language.
The systematic choices that are driven by referential and stylistic constraints are part of language use, not of the linguistic system. Syntactic templates are useful starting points for generation because they largely resolve the major systemic linguistic constraints and so set the stage for a free stylistic and referential combinatory. Using such templates Roubaud 1985: (191, cited in Braffort 2006) imagined chimeric poetry which combines the style of two poets. One example is the Rimbaude-laire, a set of poems built from templates extracted from Rimbeau's poems and lexical items from Baudelaire's (or vice versa). Roubaud and Lusson developed combinatory software that automatically generates all the permutations of the lexical items within a template (Roubaud and Lusson 2006; refreshing the page or clicking on "poème" will generate a new poem). JanusNode's textual "DNA" are similarly syntactic templates that are randomly filled with a given vocabulary.
Table 27 1. Syntactic templates.| Bronze | maiden | am | I | and | on | Midas's | mound | I | lie |
| Silver | missy | above | Goldfinger's | heap | repose | ||||
| Gold | miss | outside | Buster's | pile | perch | ||||
| Metal | girl | supra | Bambi's | stack | recline |
Formally, such chimeric poetry is possible because it is an easy step to abstract away the syntactic structure of a text and then combine the resulting template with a lexicon. Most of the text's linguistic constraints are managed in the templates (though here too there are some stylistic influences); lexical choice, on the other hand, reflects stylistic and referential constraints which are informed by the author's discursive practices and the world the text describes. Roubaud and Lusson's software automates the combining of templates and lexicons (no doubt the method used in the Malvole (Round 2006) and Kurzweil (2006) generators as well, with probabilistic improvements in the latter), but it is clear that template construction and lexicon building could be easily automated as well. From the corpora of two poets, it is possible to generate automatically the two lexicons and templates. What is more challenging is selecting semantically relevant combinations from all the possibilities. A semantic templating system requires a different set of linguistic resources.
Semantic templates
A semantic template is a systematic lexical choice that reflects either the state of an imaginary world or a particular way to express statements about that world. For instance, from "She likes pink dresses," where the semantic marker "feminine" is repeated in many of the lexical items, we may wish to generate a second, gender-bent sentence "He likes blue pants," where the semantic markers "masculine" systematically replace (as far as possible) the feminine markers. Both sentences, as well as many others such as "It likes tall trees," correspond to the general syntactic template "<pronoun> likes <adjective> <noun>." But we do not want such a large range in meaning; we would like to modulate sentence generation more finely by systematically choosing semantically related words. That requires considerably more information about the relation between lexical items than do the Rimbaudelaire poems.
To illustrate some of the difficulties and possibilities of semantic templating, we will explore here the programming that would allow us to move from Midas's epitaph to another version which is considerably more abstract in its expression (Table 27.2).
These automatic transformations replace nouns and verbs (marked with asterisks) with words that are doubly more abstract than the target word. Adjectives (and past participles used as adjectives; both marked with a plus sign) are replaced with words that are similar, but not necessarily more abstract. The procedure requires (1) tagging all the words with their part of speech and then (2) making a programmed walk in the WordNet dictionary that leads from one word to another. This set of programmed walks in WordNet is a semantic template in the sense that there is an overall logic in the shift in meaning that affects the entire text; here, the paradigmatic choice at each syntactic spot in the template is under the same "abstracting" influence. Any given generated text is therefore the product of a semantic template, where word choice is regulated, and a syntactic template, where syntactic agreement is established.
Table 27 .2 Double abstraction of Midas's epitaph.| *Bronze *maiden am I and on Midas's *mound | *Alloy *young female that I am and on Midas's | |
| I *lie. | *artifact I *be | |
| As + long as *water *flows and +tall *trees | As long as *fluid *covers and + long-stalked | |
| *bloom, | *tracheophytes *grow, | |
| Right here + fixed fast on the tearful *tomb, | Right here + immobile fast on the + sniffly *point, | |
| I shall *announce to all who *pass near: Midas is | I shall *inform to all who *change near: Midas is | |
| + dead and + buried here. | +defunct and + belowground here. |
Automatic syntactic template building through POS tagging
There are a growing number of public domain packages for creating and manipulating text and its linguistic infrastructure. Text generation systems (e.g., KMPL (Reiter 2002) and Vinci (Lessard and Levison, described in Winder 2004: 462ff)) allow for a detailed specification of text structure. Part-of-speech taggers (e.g., TreeTagger (Stein 2006)), have become fairly robust and simple to operate. General text engineering systems (e.g., OpenNLP (Baldridge and Morton 2006) and NLTK (Bird et al. n.d.)) are considerably more difficult to master, but accessible even to inexperienced users (with patience!). The pedagogical, well-documented NLTK is built on the humanist-friendly programming language Python. We will use NLTK to tag each word of the text with a part of speech. NLTK has a number of tagging algorithms that can be combined. This is the part-of-speech template that NLTK produces, using several taggers trained on the accompanying Brown corpus:
Bronze/jj maiden/nn am/bem I/ppss and/cc on/in Midas/nnp 's/poss mound/nn I/ppss lie/vb ./.
As/ql long/rb as/ql water/nn flows/vbz and/cc tall/jj trees/nns bloom/vb, /,
Right/ql here/rn fixed/vbn fast/rb on/in the/at tearful/jj tomb/nn
I/ppss shall/md announce/vb to/in all/abn who/wps pass/vb near/rp :/:
Midas/nnp is/bez dead/jj and/cc buried/vbn here/rb ./.
Codes for parts of speech are found in the NLTK documentation;4 those that interest us are the adjective (jj), past participle (vbn), noun (nn, nns), and verb (vb). NLTK tagging routines use a set of tagged texts from the Brown Corpus included with NLTK to make a lexicon with parts of speech, frequencies, and POS contexts. Variations in cases ("Bronze" vs. "bronze"), punctuation (all punctuation is tagged as itself here), affix and prefixes ("tearful"/"tear") are analyzed by preprocessors that tokenize the input text. To correctly choose a tag for a given word requires several steps:
• The default tagger tags all tokenized words with the proper noun tag (nnp), since most unrecognized words will be in the open class of proper nouns.
• Then the unigram tagger finds the most frequent tags in the reference corpus associated with each word and applies them accordingly. "Bronze" will go from nnp to nn, since in the NLTK Brown corpus nn is its most frequent tag for "bronze."
• A bigram tagger then looks at what tag pairs are in the database: as it turns out, the Brown corpus has tagged occurrences as both jj+nn and nn+nn: "bronze wreath" is analyzed as "bronze/nn wreath/nn" (vs. "bronze/jj neck/nn"):

The bigram tagger understands, however, that the frequency of jj+nn (as in "bronze cannon") is far greater in the corpus than the frequency of nn+nn ("bronze statue") and assumes that since "bronze" is also jj, it can retag it so that the more frequent tag combination is respected. (The tagger is logical, though this is not the standard analysis of "bronze.")
NLTK includes other taggers (i.e., different algorithms and databases for tagging texts) such as the Brill tagger and Hidden Markov Model tagger that make a more thorough analysis of tag probabilities. For our purposes, the default tagging (with nnp), the unigram tagger, and the bigram tagger are sufficient, in spite of certain errors which we will correct manually. All taggers break down in places, and some sentences are simply not analyzable (to experiment with tagging, see UCREL for the online version of the CLAWStagger).
The basic problem faced by a tagger algorithm is that linguistic information is typically not layered in a homogeneous fashion. For example, though the nn+nn combination is relatively infrequent, in some cases, such as "lawn tennis," it is the only possibility (since "lawn" is not an adjective). Taggers must work not only on a given "horizontal" relation with units at the same level, such as tag combination, but as well they must take into account the idiosyncratic influence of one level on another, such as the influence of a particular lexical choice. Such idiosyncratic "vertical" influences are cited as one justification for tree adjoining grammar formalism, which encapsulate information at different levels using a tree structure — see Abeillé and Rambow 2000: 8.
Automatic semantic template building: navigating between senses
The POS tagged text is the syntactic half of generation. A semantic template is the complementary organization of the word meanings that are chosen to fill the slots in the syntactic template. Words and their meanings have an intrinsic organization that does not concern syntax at all. WordNet (see Fellbaum 1998) groups words of like meaning into synsets, i.e., into "a set of words that are interchangeable in some context without changing the truth value of the proposition in which they are embedded" (Miller 20065). Synsets are themselves related according to several semantic relations, among which: hypernymy/hyponymy (the more general type of the source word; e.g., "color" is the hypernym of "red"; inversely, "red" is the hyponym of "color"); holonymy/meronymy (the whole of which the source word is a part; e.g., "crowd" is the holonym of "person"); antonyms (extreme opposites such as "good" and "bad"), similar to (adjectives that mean something similar; e.g., "immobile" is similar to "fixed"), and entailment (the source word has as a logical consequence another: e.g., "snoring" entails "sleeping").
Just as our syntactic template is built out of the general syntactic categories (like "noun" and "verb"), our semantic template will use general relations, like "antonym" and "similar to", to describe in general terms the meaning structures of a generated sentence.
Double hypernyms
Each word of our epitaph has a position in the WordNet meaning universe which is defined by its synset membership. The word "bloom" belongs to 6 noun synsets and 1 verb synset:
Noun
• S: (n) blooming, bloom (the organic process of bearing flowers) "you will stop all bloom if you let the flowers go to seed"
• S: (n) flower, bloom, blossom (reproductive organ of angiosperm plants especially one having showy or colorful parts)
• S: (n) bloom, bloom of youth, salad days (the best time of youth)
• S: (n) bloom, blush, flush, rosiness (a rosy color (especially in the cheeks) taken as a sign of good health)
• S: (n) flower, prime, peak, heyday, bloom, blossom, efflorescence, flush (the period of greatest prosperity or productivity)
• S: (n) efflorescence, bloom (a powdery deposit on a surface)
Verb
• S: (v) bloom, blossom, flower (produce or yield flowers) "The cherry tree bloomed" ("bloom" in Miller WordNet6)
The synset for the verb "bloom" contains "bloom, blossom, flower". The lexical relations that that synset entertains with other synsets can be displayed by clicking on the synset ("S"). The first-level direct hypernym of the verb "bloom" is thus "develop" (a blooming is a kind of developing) and the hypernym of "develop" is "grow" (a developing is a kind of growing):
• S: (v) bloom, blossom, flower (produce or yield flowers) "The cherry tree bloomed"
• direct hypernym
• S: (v) develop (grow, progress, unfold, or evolve through a process of evolution, natural growth, differentiation, or a conducive environment) "A flower developed on the branch"; "The country developed into a mighty superpower"; "The embryo develops into a fetus"; "This situation has developed over a long time"
• direct hypernym
• S: (v) grow (become larger, greater, or bigger; expand or gain) "The problem grew too large for me"; "Her business grew fast" ("bloom" in Miller 20067)
The abstracting algorithm will take all the nouns and verbs in our epitaph and navigate to their second-level direct hypernyms (a double hypernym) and put that double hypernym (or the first word of the synset, if the synset has more than one word) in place of the original word of the epitaph. In a similar way, adjectives and past participles will be replaced with "similar to" words. In the case of the verb "bloom," the replacement word is "grow."
Word sense disambiguation
WordNet comes with an assortment of tools for navigating the database (in many programming languages, but the Python modules are perhaps the most compatible with NLTK). In our double hypernym navigation we will generally have to choose between different senses, just as when we syntactically parsed the text we had to decide which part of speech was appropriate. In the case of navigating the sense tree of "bloom", there is no confusion; only one sense is under verb and only one hypernym at each level (bloom → develop → grow). The adjective "dead", on the other hand, has 21 senses (i.e., it belongs to 21 different synsets). We need a method for disambiguating different meanings.
Sense disambiguation depends on context, both syntactic and semantic. For example, to disambiguate "lie" it is useful to know that the subject is a person; in our text, "I" is a personified object, so "I" can tell a lie, lie down, but rarely will "I" lie in a certain position, as in "the mountains lie in the west." Semantic clues also come from the set of words that are in the same passage, whatever their syntactic relation. "Mound" could be a baseball mound, but since in the same context we find "tomb," "dead," and "tearful," our choice would favor a burial mound (though that sense is not found in WordNet).
SenseRelate (Pedersen) is a Perl package that attempts to compare all such relations and disambiguate words according to their immediate context, their position in the WordNet ontology, and a corpus of sense tagged texts. SenseRelate, properly configured, will semantically tag our text as follows (WordNet only tags nouns, adverbs, adjectives and verbs) (Table 27.3).
The online version of SenseRelate8 shows how meanings are selected according to several algorithms that quantify how semantically close entries are in the WordNet network. The Lesk algorithm, for example, evaluates word overlaps in the glosses for each meaning. As we can see above, "tomb" and "mound" are related by the words "earth" and "stone" (in the gloss of "mound") and "ground" and "tombstone" (in "tomb"; "ground" has for gloss "the solid part of the earth's surface"); "dead" and "tomb" are linked by the relation between "life" and "dead man" (in "dead") and "corpse" (in "tomb"; the gloss of "corpse" is "the dead body of a human being"). Table 27.4 shows the Lesk values for the latter pair (top values only; the rest are 0), as generated by the online tool; sense 1 of the adjective "dead" is most closely related to sense 1 of the noun "tomb".
Table 27 .3 SenseRelate meaning selection (excerpt).| Word POS Sense | WordNet Gloss |
|---|---|
| BRONZE n 1 | an alloy of copper and tin and sometimes other elements; also any copper-base alloy containing other elements in place of tin |
| MAIDEN n 1 | an unmarried girl (especially a virgin) … |
| MIDAS n 1 | (Greek legend) the greedy king of Phrygia who Dionysus gave the power to turn everything he touched into gold |
| MOUND n 4 | a structure consisting of an artificial heap or bank usually of earth or stones; "they built small mounds to hide behind" … |
| TEARFUL a 1 | filled with or marked by tears; "tearful eyes"; "tearful entreaties" |
| TOMB n 1 | a place for the burial of a corpse (especially beneath the ground and marked by a tombstone); "he put flowers on his mother's grave" … |
| DEAD a 1 | no longer having or seeming to have or expecting to have life; "the nerve is dead"; "a dead pallor"; "he was marked as a dead man by the assassin" … |
| BURY v 2 | place in a grave or tomb; "Stalin was buried behind the Kremlin wall on Red Square"; "The pharaohs were entombed in the pyramids"; "My grandfather was laid to rest last Sunday" |
| HERE r 1 | in or at this place; where the speaker or writer is; "I work here"; "turn here"; "radio waves received here on Earth" |
| Measure | Word 1 | Word 2 | Score |
|---|---|---|---|
| lesk | dead#a#1 | tomb#n#1 | 6 |
| lesk | dead#n#1 | tomb#n#1 | 4 |
| lesk | dead#n#2 | tomb#n#1 | 3 |
| lesk | dead#r#2 | tomb#n#1 | 2 |
| lesk | dead#a#2 | tomb#n#1 | 1 |
| lesk | dead#a#14 | tomb#n#1 | 1 |
| lesk | dead#a#3 | tomb#n#1 | 0 |
| … |
We use such sense relatedness measures to choose between alternative hypernyms or "similar to" adjectives in our abstracting algorithm.
Automatic narrative
Narrative represents the third major topography. Most generators do not deal directly with that topography; rather, narrative generation is generally approached in the same manner as syntactic and semantic generation, with a few enhancements. Table 27.5 shows some sample generation from JanusNode.
The French site Charabia (see Reyes 2006) has a generator which subscribers use to produce various texts. Here is the start of a (long) philosophical essay that one user programmed:
Tribalisme vs tribalisme
1. Prémisses du tribalisme idéationnel.
Si on ne saurait ignorer la critique bergsonienne du primitivisme substantialiste, Montague systématise néanmoins la destructuration primitive du tribalisme et il en identifie, par la même, l'aspect transcendental en tant que concept primitif de la connaissance.
Cependant, il identifie le primitivisme de la société tout en essayant de le resituer dans toute sa dimension sociale, et le tribalisme ne se borne pas à être un primitivisme existentiel comme concept rationnel de la connaissance.
(Reyes at Charabia9)
Both these generators script narrative through different kinds of syntactic templating. Charabia uses a simplified transition network (Figure 27.1).10
Table 27 .5 JanusNode sample story plot output.| (none) | Possible title: The Hostility of Erroneous Hate | Possible title: Baggaging Bros |
|---|---|---|
| This story has two main characters. The first is Noel, a dogged air traffic controller. The second is named Erna. Erna is a dead angel. This is their story, of sex and solitude. | This story has two main characters. The first is a cold master named Una. The second is named Alonso. Alonso is a drunk master. | Your protagonist is a brown skin broke bro named Larissa. Your antagonist is a kindhearted agent named Griselda. Their story is one of creativity and open-heartedness. |
| Noel and Erna meet in an useful motel. Noel wants to discuss personalizing and hugging. Erna is tired of being dead and needing. She knows that Noel is neither dead nor needing. Noel is only after one thing: contents. Erna needs to get contents. The well-intentioned air traffic controller explains to the thrilling angel that the difficult animation is like an atmosphere. Erna feels confused. The moral is worth remembering. Clairvoyant sex is not the same as optimal solitude. | Una and Alonso meet in a boisterous crimson hospital waiting room. Alonso is thinking of giving up being a master to study epitaphs with Una. Una takes out a hostility, and advises Alonso to be more quarrelsome. The penniless master reveals the hostility to the master. Alonso becomes less drunk. | Larissa and Griselda meet in an alien furthest sitting room. Larissa and Griselda have been brought together by their common friendship with a third character named Nicola. Griselda is thinking of giving up being an agent in order to pursue an interest in studying intentional metaphysics. Larissa gives benumbed information about the importance of weakness and destruction. The illiterate agent steals the baggage from the brown skin bro. Larissa becomes more brown skin. The moral is instructive. Interesting creativity is only xenophobic open-heartedness. |
Generation passes through each node in a random fashion, text is written out, variables are set that select the lexicon ($theme_dtd qualifies the chosen thematic word, $theme), loops are defined, and control is passed to subnetworks (comp2, a complement such as "au regard du maximalisme", and adj1_fs, a feminine singular adjective, are described in other networks).
JanusNode uses the same techniques for the most part, but the network is implemented with scripts called TextDNA:
100 Subject(AnimalPoemSetUp) < assign(Cur,"dog,cat,pig") 100 >
100 Subject(ShortAnimalPoem) "A" 100 < GetRhyme(Cur,noun) 100 >
"likes to" 100 < GetRhyme(Cur,verb) 100
> "!" 100
A pig likes to jig!
A cat likes to bat!
(TextDNA and sample output from JanusNode documentation)
The numbers indicate the probability that a given function will fire (100 means that the function will fire 100% of the time); the assign function chooses a word randomly in a set or file of words given in the second argument and assigns it to the variable given in the first argument. JanusNode has some built-in linguistic functionality: a rhyming function (GetRhyme) and minimal morphology. It also has a rudimentary TextDNA generation system which will make scripts from source text. Properly configured, JanusNode scripts are more powerful than Charabia's networks, but are more tedious to write.

Figure 27.1 Intro1 node of the Charabia generator.
One significant variation on this basic template framework for generation are systems that are designed for dialogue, such as A.L.I.C.E. (and the AIML scripting language). Narrative is developed "on the fly" in response to the user's input. In such cases the input text is transformed into data for generation.
Narrative topology: chaining events
Generating truly creative narrative poses a particular problem. The template systems we have dealt with so far only concern the most combinable units of language —words — through word-centered syntax (POS tagging) and semantics (dictionary meanings). Programming narrative is difficult because the fundamental topography of narrative is not linguistic, but rather a topography of events. Grammars offer much accumulated knowledge about syntax that is formalized; dictionaries describe word meaning in a very clear fashion; encyclopedias describe events, but with almost no formalization. No convincing narrative can be made without a large database of our commonsense understanding of events. Narrative does have a linguistic component as well, which dictates how information will be parceled out to the reader. For instance, it is a purely linguistic fact that the order of sentences typically represents the order of events. We understand differently "Paul broke down in tears. Mary broke his channel changer" and "Mary broke his channel changer. Paul broke down in tears." However, it is a fact of the world, not of language, that the destruction of an object might have an emotional impact on a person. Neither a grammar nor a dictionary has that fundamental knowledge, knowledge that a story generator must inevitably orchestrate.
The lightweight templating systems we have seen so far require the user to build events through language. On the contrary, an ideal story generator would either generate events automatically, selected from an events database, or take a general description of an event and generate the appropriate language. Good narrative, the most general topography and the one that connects language most directly to reality, is particularly difficult to master because it is at this level that all the underlying topologies are given a final meaning. Narrative is where information at different levels is evaluated. Poetry shows this most clearly, since even the simple sound or spelling of a word might be the focus of the text. Thus a story generator about birds in French might need to know something about the character level of the word "oiseau" (that it has all the vowels). Similarly, in our epitaph it is perhaps important, or not, that the maiden be bronze, rather than silver. Ultimately, the pertinence of a lexical choice can only be determined by the goal of the narrative; narrative establishes a general logic and hierarchy for all the other kinds of information in the text.
Heavyweight narrative generators (see Mueller 2006 for a bibliography and resources) depend on large databases of encyclopedic knowledge. MIT's Open Mind Common Sense (OMCS; see Singh et al. 2002) was conceived to collect a database of common sense reasoning from internet users and distill it into a computer-usable form. General event scripts are added to these databases or generated from the encyclopedic knowledge. Thought Treasure (Mueller 200011) is a well-documented, pioneering reasoning database that was used as a model for the OMCS database. Here is one of the handcrafted scripts from Thought Treasure:
2. (sleep) [frequent] sleep; [English] sleep; [French] dormir
[ako ∧ personal-script]
[cost-of ∧ NUMBER:USD:0]
[duration-of ∧ NUMBER:second:28800]
[entry-condition-of ∧ [sleepiness sleeper]]
[event01-of ∧ [strip sleeper]]
[event02-of ∧ [ptrans-walk sleeper na bed]]
event03-of ∧ [set sleeper alarm-clock]]
event04-of ∧ [lie-on sleeper bed]]
event05-of ∧ [groggy sleeper]]
event06-of ∧ [sleep-onset sleeper]]
event07-of ∧ [asleep sleeper]]
event07-of ∧ [dream sleeper]]
event08-of ∧ [ring alarm-clock]]
event08-of ∧ [wake alarm-clock sleeper]]
event09-of ∧ [awake sleeper]]
event20-of ∧ [rise-from sleeper bed]]
goal-of ∧ [s-sleep sleeper]]
performed-in ∧ bedroom]
period-of ∧ NUMBER:second:86400]
result-of ∧ [restedness sleeper]]
role01-of ∧ sleeper]
role02-of ∧ bed]
role03-of ∧ alarm-clock]
The sleep script describes the event as being personal, costing nothing (in US dollars!) and having a duration of 28,800 seconds (the conventional 8 hours), requiring a sleeper and sleepiness, having a series of subevents, such as stripping, the sleeper walking (from n/a) to bed, setting the alarm clock, lying on the bed, feeling groggy, beginning to go to sleep, being asleep and dreaming, the alarm clock ringing, etc.
This handcrafted script gives the barest understanding of the sleep event. The Open Mind project collected 700,000 commonsense statements (the OMCS raw data) about the human experience, deduced some 1.7 million formal relations, and compiled them in the ConceptNet application (Lui et al. 2006). Over 2,000 sentences of the OMCS raw data use the word "sleep" or its direct derivatives; here is an arbitrary sample:
1. If a person is bored he may fall asleep
2. Jake has two states — awake and asleep
3. You are likely to find a cat in front of a fireplace, sleeping
4. Sometimes viewing a film at home causes you to fall asleep on the sofa
5. A motel is a place where you can rent a room to sleep in
6. Many people have schedules that allow them to sleep later on weekends than on weekdays
7. The effect of attending a classical concert is falling asleep
8. Something you might do while watching a movie is falling asleep
9. A sofa hide-a-bed is for sleeping
10. Sometimes taking final exams causes sleepiness
11. Ken fell asleep
12. Studies have shown that sleep deprivation leads to impaired consolidation of both declarative and procedural memories
13. Something you might do while sleeping is fall out of bed
14. An activity someone can do is sleep in a hotel
15. You would relax because you want to go to sleep
16. Cindy Lou has a home to sleep in
17. You would sleep at night because you had a busy day
(OMCS raw data)
Heavyweight story generators (such as Make Believe (Liu and Singh 2002); for others see Meuller 2006) will use such information to create a narrative topography. A character sleeping in bed might be in her home, and she may fall out, dream, snore, it could be at the end of a busy day, etc. Simply ordering a selection of the sentences given above and making adjustments gives a rough narrative sequence describing Jake's falling asleep and then falling out of bed (words inserted are in bold; words deleted are struck out):
1. Jake has two states — awake and asleep
17. You too would sleep at night because if you had a busy day
15. You would relax because you want to go to sleep
4. Sometimes viewing a film at home causes you to fall asleep on the sofa
9. A sofa hide-a-bed is for sleeping
11. Ken Jake fell asleep on the hide-a-bed
13. Something you too might do while sleeping is fall out of bed
…
ConceptNet's database is a network of the abstract rendering of such messy statements about the world. Every node of the network will have "incoming" and "outgoing" relations with other concepts (Figure 27.2).
Automatic generation with ConceptNet consists in following event links, playing out the combinatory of their subevents, and creatively developing descriptions based on the other types of relations in the network.
Art
The techniques described here do not produce very comprehensible nor artistic narrative. There is little chance that computers will figure soon on the list of best selling authors. At the same time, these techniques are prerequisites for creative writing by computers or computer-assisted writing by people. Text processors will soon offer thesaurus-like functions that produce variants of a sentence, a paragraph, or perhaps even a text. But what makes good writing?

Figure 27.1 ConceptNet's network of concepts (Liu and Singh).
According to one successful writer, Stephen King, good writing is not about the mechanics of plot:
Stories are found things, like fossils in the ground […]. Stories aren't souvenir tee-shirts or GameBoys. Stories are relics, part of an undiscovered pre-existing world. The writer's job is to use the tools in his or her toolbox to get as much of each one out of the ground as intact as possible. Sometimes the fossil you uncover is small; a seashell. Sometimes it's enormous, a Tyrannosaurus Rex with all those gigantic ribs and grinning teeth. Either way, short story or thousand-page whopper of a novel, the techniques of excavation remain basically the same.
(2000: 163)
Getting a fossil out of the ground requires delicate tools, like a palm-pick, airhose, or toothbrush. Plot is the jackhammer of writers: "a good writer's last resort and the dullard's first choice" (2000: 164). As an exercise for the aspiring writer King describes (in his own good style) a bare-bones narrative about a woman who is stalked in her home by her estranged husband:
It's a pretty good story, yes? I think so, but not exactly unique. As I've already pointed out, estranged hubby beats up (or murders) ex-wife makes the paper every other week, sad but true. What I want you to do in this exercise is change the sexes of the antagonist and the protagonist before beginning to work out the situation in your narrative […]. Narrate this without plotting — let the situation and that one unexpected inversion carry you along. I predict you will succeed swimmingly… if, that is, you are honest about how your characters speak and behave. Honesty in story telling makes up for a great many stylistic faults, as the work of wooden-prose writers like Theodore Dreiser and Ayn Rand shows, but lying is the great unrepairable fault.
(2000: 173)
The great gap between printing and writing seems indeed to concern that "honesty in story telling"; writers must use the finest brush to extract from the mass of our beliefs about the world a single compelling image of the way things inescapably are. But how can the writer be honest about fictional characters!? King's honesty is about what our understanding of the world will allow us to put together reasonably (in his exercise, it is understanding the difference between the sexes in their manner of stalking). How things cohere in principle is a truth that writer and reader must both possess in order to understand each other. That coherence is no more nor less than who writer and reader are together, as one being. It defines the single honest way to set about thinking and speaking.
Let us assume, then, that the artistic text captures the higher truth of the way things are. It is priceless, lively, and live because, by being intensely, exactly itself, it subsumes the many variants of itself. A gender-bent text is artistic only when it implicitly says the straight text and underlines the inescapable reasoning that brings both texts under a same denomination and so subsumes by the same stroke the many possible variations on the theme. By showing what stalking might be, it shows what stalking mustbe, however the situation may vary. Artistic texts, clearly departing from the norm by a twist or a wriggle, scintillate with meaning and show dramatically the principle of how they came to be — their "makedness." The deepest truth about anything is the way it comes to be, because there lies the secret of how it might continue to be.
If poetic art is indeed "impeded form" or "roughened language" (Shklovsky), it is because narrative leads the reader to tease out a synthetic position — a higher ground —that explains the world of perplexing opposites. Artistic narrative is "roughened reasoning" that leads up to a communal, true way to seeing as one the perplexing opposites of the world. Socrates's complaint about Midas's epitaph is that it does not go anywhere: there is no excavation project to exhume the truth of Midas. There is only the clanking tongue of a bronze maiden, just as petrified as Midas in his grave. Combinatory is not art. Narrative goes somewhere specific: up.
Can computers really write? Only if they can fly. They must move up out of their clanking linguistic machinery to a general truth about the world and to a vantage point that captures the text's fundamental generativity. A good text — an artistic text —is the one that represents best many other texts.
Remarkable steps have been made to give machines the resources needed to build higher meaning, but it will take still more accumulation of data about how people see the world. Minsky estimates that even simple commonsense "is knowing maybe 30 or 60 million things about the world and having them represented so that when something happens, you can make analogies with others" (Dreifus 1998, cited in Liu and Singh forthcoming: 2). We will only see computers generate art from all that commonsense when they can be programmed to tell us something true.
Blogs and Blogging: Text and Practice
A relatively new genre in digital literary studies, the weblog, or blog, has shot to prominence as a primarily popular medium. From its modest beginnings as a sort of digest tool for computing professionals and internet hobbyists, the blog has attained the mainstream as a form of digital personal diary, an outlet for citizen journalism, a community space for special interest forums, and a medium for more passive entertainment. Current estimates suggest that a new blog is created every second; nearly 54 million were published as of late 2006 (Technorati 2006). Many of these blogs — in all the categories identified — are written and read by academics as well as their students. Many more, including especially journalistic and political blogs, are becoming objects of study in a variety of research contexts in the humanities and social sciences. Also, with their strong emphasis on readability, audience, and style, blogs are of increasing interest to the fields of rhetoric and composition as a pedagogical tool and emerging creative writing genre. Literary scholars, too, are examining the links between blogging and more traditional forms of publication as many prominent bloggers either hail from the print media, or are recruited by it. Similarly, as happened after the popularization of the World Wide Web, longstanding and established print media such as national newspapers and mass-market magazines are beginning to incorporate elements drawn from blogging into their publishing purviews, a development of interest to media and communications researchers. A corpus of research in new media, also, is beginning to address the role and impact of blogs on practices of internet sociability and computer-mediated communication (CMC), with a particular eye to behaviors characteristic of identifiable demographics.
The weblog as a writing form is fundamentally about fostering personal expression, meaningful conversation, and collaborative thinking in ways the World Wide Web had perhaps heretofore failed to provide for; not static like a webpage, but not private like an email, as well as more visually appealing than discussion lists, blogging's rapid rise to online ubiquity bespeaks its quite particular fit into a previously unidentified hole in the digital universe, and this appeal is worth exploring. Here, we will proceed from definitions and histories, through an examination of the requisite undergirding technologies, enumerating the many genres of writing supported by blogging, with an emphasis on resources for reading and writing in this form, finally overviewing the research on the nature and effects of blogging and the pertinence of this practice to literary studies. For those interested in creating or participating in blogs, a list of resources follows this chapter.
Weblogs
"Blog" is a contraction of "weblog," itself a compound of web log, a term originally designating the report generated by the automated tracking of activity and traffic on computer servers. Blogging as a practice is rooted in computing science and engineering, among whose professionals this form first appeared, in the mid-1990s. In its most rudimentary incarnation, the weblog was a simple HTML page featuring annotated hyperlinks to sites of interest to the page's author. They were logs of their authors' travels over the internet, not differing substantially in form or content from many early personal home pages, except in the frequency or regularity with which the information on them was updated or changed. Recognized as a distinct genre from about 1997 by a small and bounded community of participant readers and writers, when the development of simple-to-use blogging software around 1999 promoted the spread of the practice to a larger group, the "weblog" came to be known more commonly as the "blog."1 The more informal term "blog" was chosen as Merriam-Webster's "Word of the Year" for 2004 (Merriam Online 2004). Of course, this honor is accorded to the most looked-up word in the online version of the dictionary. The need to search for a definition of the term indicates that the public discourse of blogging — references to the practice or to particular sites in mainstream media —exceeds the general knowledge. Accordingly, a January 2005 Pew/Internet Data memo on "The State of Blogging" indicates that less than 40 percent of surveyed internet users knew what blogs were — 62 percent could not define the word (Rainie 2005).
So what are blogs, then? As a writing genre, weblogs manifest several essential and optional characteristics, all of which are supported by the common blogging software packages to varying degrees (more on which later). These characteristics, in decreasing order of prominence and importance, include: the discrete post as fundamental organizing unit; date- and time-stamping of posts; the appearance of posts in reverse chronological order; hyperlinking to external sites; the archiving of posts and references to posts with permalinks and trackbacks; the reference to other likeminded or otherwise interesting blogs through the provision of a blogroll; the capacity for reader comments on posts; and the organization of posts by keywords into separate browsable categories. Each characteristic contributes to distinguishing the blog from other genres of digital writing that are its kin, genres such as the webpage, the email, the web ring, or the discussion group, and it is useful to consider each characteristic in turn.
At its most basic, a blog is a webpage comprised of individual posts. Posts have been likened variously to newspaper articles, diary entries, or even random scribbles in a notebook, and they can contain simple links to other sites, narrative commentary, or embedded or linked media components like photographs, videos, or audio files. Posts can be of varying lengths, ranging from a sentence fragment with a single embedded link to a multi-screen essay complete with references; generally, posts tend to the shorter rather than the longer. Herring et al. (2005), in their quantitative analysis of weblogs, for example, found an average post length of about 210 words among their 200-blog sample. As the date- and time-stamp function indicates, blogs are assumed to be frequently updated, with "frequently" meaning in some cases hourly and in others once or twice weekly. The National Institute for Technology in Liberal Education estimated in 2003 that 77 percent of more than 500 sample blogs it surveyed had been updated within the last two weeks (NITLE 2003a). Generally, it is a blog's currency of information that is its greatest attraction — hence the reverse chronological posting order, privileging the most recent updates — but bloggers can offer other means to navigate and browse what can become quite hefty archives of materials. Keywording of blog posts allows for the construction of discrete, blogger-defined categories of entries, allowing readers to browse a subset of posts dealing with a particular category. A blogger of quite catholic writing interests might keyword her posts so that readers need not wade through those about cats or about Prison Break in order to follow the thread about Nicholas Nicklebyand Dickens's comic genius, or the one about ActionScripting in Flash.
Many blogs feature embedded hyperlinks to materials being commented upon. Traditionally — which is to say, circa 1997–9, when weblogs were first becoming recognizable as a distinct form of digital publication — the weblog served a digest function, acting as a daily compendium of annotated links to sites of interest to the blogger and his or her readers (Blood 2000). These posts tended to be short and were explicitly organized to direct readers to the site commented upon. As blogs spread and the genre expanded beyond this digest function, longer, discursive posts have become more common and the hyperlink in some cases has proportionally faded in importance; this is especially true of diary-style blogs that emphasize stream-of-consciousness narration of the blogger's daily life or emotional state over more explicitly critical or socially engaged kinds of writing. Herring et al. (2005) found that nearly a third of their sampled blog posts featured no links at all; they surmise that this is owing to the numerical superiority of diary-style blogs in their corpus. The authors suggest further that this percentage would be even higher had they not deliberately excluded several blog hosts that were explicitly promoted as online diary services.
One of the more interesting features of the blogging world — or "blogosphere," as it refers to itself — is its recursive self-referentiality, and the opportunities it offers for digital conversation. Conversation is most obviously encouraged between blog authors and blog readers by the built-in capacity for reader feedback: the "comment" feature of most blogging software and services allows any reader to add their own comments to a post. Here again, though, Herring et al. (2005) found a far lower incidence of interaction than is popularly claimed for blogs: the number of comments per post ranged from 0 to 6, with a mean of 0.3. The free-for-all of democratic, unfiltered interaction provided for by anonymous, instant commenting has been severely challenged by the advent of "comment spam," the blogosphere version of unsolicited mass-mailed advertisements: early ideals of mass participation are now bumping up against the realities of un-neighborly commercial practices. Depending on the setup, commenting may be completely anonymous (a practice that can leave the blog open to inundation by comment-spam, or encourage repercussion-free digital vandalism) or may require a reader to register a screen name, email account, and password, and to pass a small test (generally, deciphering textual content from a provided image) to prove that the comment issues from a traceable human and not a spam-bot. Similarly, different levels of editorial oversight allowed for by blogging software mean that comments may appear the moment they are made, or may first require approval by a vetting human eye before being appended to the post.
From commenting upon and pointing to other internet sites, blogs soon began commenting upon and pointing to one another. Such blog-to-blog references may take the form of a simple comment pointing readers to the commenter's own blog in the context of elaborating a longer response, or may occur in the context of one blog post more explicitly linking to another via technologies such as the trackback and permalink. Permalinks offer a stable URL reference to a particular post, so that this post may be linked to or otherwise referenced reliably and unambiguously. Trackbacks list and link to those external sites that reference the post in question — a kind of "see who linked to me" feature that can serve to key a reader to a multi-site conversation, or simply to indicate the popularity of the blogger or the buzz-level of the post; trackbacks are semi-automated and require both the linker and linkee to have tracking software enabled. However, the most common way that blogs reference each other is through the blogroll, a simple list of blog titles running down the side of each page: it promotes the blogs the blogger finds useful or entertaining, denoting affiliation with like-minded others in a community of readers and writers. Blogrolls are one of the main filtering tools by which readers access blog resources of interest to them, as we will see below. They also foster community and conversation in their function as aggregators of bloggers and readers, and of topics, viewpoints, and references.
As research undertaken by the Pew Internet and American Life Project and others makes clear, the blogosphere is expanding at a great pace — from an estimated 21 million American blog readers in early 2004 to an estimated 32 million by the end of that year (representing an increase from 17 to 27 percent of all American internet users, whom Pew estimates to number 120 million). This indicates a 58 percent growth in blog readership in a span of ten months. Pew also marks at 7 percent the rate of blog authorship among the American internet-using population — this makes for 8 million bloggers, by its count (Rainie 2005). Internationally, Technorati (<http://www.technorati.com>), the blog-tracking website and search engine, was indexing more than 54 million blogs globally in late 2006, an ever-shifting roster at a time in which blogs are created at a greater rate than the one at which they go defunct. LiveJournal (<http://www.livejournal.com>), for example, is home to 10 million separate accounts, of which nearly 2 million are considered "active in some way": slightly more than half of this subset of active accounts has been updated within the previous month, and one-fifth of these within the last 24 hours (LiveJournal). There are several reasons, both cultural and technological, driving the increases in readership and authorship of blogs. We will address these here in turn, both in the context of the broader population and of the academy more specifically.
One of the factors driving the increase in popular blog readership, and a greater awareness of the blogosphere generally, was the 2004 American presidential election, which saw a veritable explosion of political blogs devoted to critiquing, mudslinging, or fundraising — or sometimes all three.2 During this election, bloggers earned press credentials for nomination conventions and other campaign events, their activities were reported on in established media outlets, and the bloggers themselves began to be called upon as pundits in these same media. This greater penetration of the "real world" by bloggers increased their visibility among newspaper readers and television watchers generally, leading to a rise in blog traffic. Further, staunchly partisan Democratic, liberal, or left-leaning blogs like Daily Kos, Talking Points Memo, and others offered what many considered to be a bracing alternative to the perceived blandness and conservatism of the mainstream media. The internet-dependent campaign of Howard Dean to seek the Democratic nomination, for example, was almost more newsworthy than the candidate himself, with the success of the Blog for America model of citizen participation, organization, and fundraising surpassing all expectations. On the Republican or conservative side, the campaign of the "Swift Boat Veterans for Truth" had a strong internet presence backed by a blogging CMS, and garnered much traffic, and the right-leaning political blog Power Line was chosen by Time as its "blog of the year" in 2004 (McIntosh 2005: 385).
In the academy, blogging has proven to be very popular among undergraduates, graduate students, and the professoriate, likely more popular than in the population as a whole — as Pew's research indicates, blog authors disproportionately manifest one or more of the following demographic characteristics: they are young, male, have access to high-speed internet connections, have been online for more than six years, are financially prosperous, and have high levels of education. University populations present these characteristics in varying degrees among their many constituent groups. Many undergraduates maintain personal diary blogs in addition to profiles on MySpace, Facebook, and the like; the blogosphere is awash in students. Herring et al. (2005) found that 57 percent of their sample blogs were written by self-identified university students — and they had excluded from consideration youth-skewed diary services like LiveJournal and Diaryland. Among the professoriate, blogging activities range across the whole breadth of the blogosphere. Pseudonymous diarizers like "New Kid on the Hallway" chronicle life in general as well as life on the tenure track in informal, personal, and intelligent ways, linked in tight blogroll and comment communities of similarly positioned and trained readers. Blogs like Rate Your Students are mostly comprised of comments from anonymized respondents, in this case mocking and parodying the popular Rate My Professors web service. Daniel W. Drezner's eponymous political punditry blog both reflects his academic work in political science and departs from the academic standards that govern his peer-reviewed work (his "About Me" page even addresses the question "Why are you wasting valuable hours blogging instead of writing peer-reviewed academic articles?" —one possible answer might be that he is now co-editor of a book on blogging). Grand Text Auto is a group blog devoted to "procedural narratives, games, poetry, and art" and authored by six new media artists, theorists, and technicians, most of whom hold academic positions, and two of whom contribute essays to this volume. Language Log chronicles and digests linguistic quirks, and two of its contributors, academics Mark Liberman (the site's founder) and Geoffrey K. Pullum, have recently published a book based on the blog's contents.
Constituent Technologies of Blogging
Blog writing, as distinct from blog-reading, is unlikely to have become as much of a mainstream pastime as it has were it not for the introduction, in mid-1999, of simple, hosted, and free blog authoring software with graphical user interfaces. A variety of CMS, or "content management system," blogging software like Pyra Labs' Blogger began to offer pre-made technical templates into which authors could simply pour their content, much like filling out an HTML form. This software dramatically lowered the technical barrier to entry, freeing would-be bloggers from HTML troubleshooting and onerous programming (or under-featured sites) so that they could instead concentrate on the writing: the result was an explosion in the number of blogs published. CMS-based blogging software applications offer a set of tools simple enough to operate that anyone competent with a web-based email account can easily be up and blogging in an afternoon. In this vein, Blogger now describes itself as "the push button publishing tool for the people" (Pyra Labs 2006). Some of the most prominent and well-used current applications are Blogger, now owned by Google; "online diaries" LiveJournal and Diaryland; downloadable Movable Type and hosted Typepad; Wordpress; and Radio Userland. Many others appear and disappear daily; most offer varying levels and costs of service. Some are free and hosted, some charge fees for upgrades like expanded storage space and support for multimedia applications such as podcasting or photoblogging, many offer premium services for professional users, and all offer slightly different functionality. Reading a blog, of course, requires nothing more than an internet connection and a web browser, and as most blogs still skew heavily toward textual content, even a very poor internet connection will suffice to provide an adequate window on the blogosphere.
While the basic practices and tropes of blogging have remained fairly constant since the advent of graphical blog-editors, more recently, syndication has become a common feature of the blogosphere. RSS (Really Simple Syndication) and Atom are XML-based programs aiding the spread of blog readership across the internet population more generally. Syndication aggregates the most recent updates to a site, basically providing a mini-site of only new content. Syndication is a "push" technology which directs content to interested users on the basis of subscription, as opposed to the more traditional reading model of search-and-visit (that "pulls" readers to a site). Syndication technologies basically allow a reader to customize her own newsfeed, with newly posted snippets of information from selected sources aggregated for the reader as they appear. The feature is as common with mainstream online news sites as it is with blogs. Developed in various contexts from the late 1990s, syndication has been coming into its own as a mainstream technology since about 2002, with support for it increasingly built into standard internet browsers, rendering it accessible to nearly everyone online.
Genres of Blogs
The landscape of blogging is changing rapidly as new users come to write and read in this medium; as with the popularization of the internet through graphical World Wide Web browsers from about 1994, the mass influx of new participants is altering the form at the very instant that its earliest communities seek to codify and prescribe acceptable uses, behaviors, and fundamental definitions. Prominent and early blog-gers like Rebecca Blood have devised widely disseminated codes of ethics for the blogosphere at the same time as this space becomes populated by users who have never read a blog before starting to write one (Blood 2002). Blood's code is based on journalistic practice, and as such is endorsed by sites like Cyberjournalist.net (see, for example, Dube 2003), but the analogy with journalism — a tremendously popular one — does not begin to cover the full extent of the blogosphere: most new users, an overwhelming numerical majority, are writing personal diaries online, and have a very different understanding of the roles and responsibilities of bloggers. Aware perhaps of this split, Koh et al. (2005), in an undergraduate thesis on blog ethics, break the blogosphere into "personal" and "non-personal" domains, a bifurcation based on the quite different demographics, audience, intent, content, and ethical frameworks informing both groups, as identified in the more than 1,200 responses to their online survey. For their part, Herring et al. (2005) note several competing blog genre taxonomies. They note Blood's tripartipite model of the traditional "filter" blog, the emerging diary-style "personal journal," and a discursive-essay-based "notebook" blog, as well as Krishnamurthy's four quadrants of "online diaries," "support group," "enhanced column," and "collaborative content creation" blogs. Finding these models wanting, the authors settle on their own genre categories, based on an initial survey of their blog samples: these are personal journals, filters, and k-logs ("knowledge-logs," generally used within organizations for technical support applications, or other oft-updated, information-rich content). According to Jeremy Williams and Joanne Jacobs (2004), "the great beauty of blogs is their versatility," and they lay out yet another taxonomy based on who is writing and what about: among the authorship categories they discern "group blogs, family blogs, community blogs, and corporate blogs," as well as "blogs defined by their content; eg 'Warblogs' (a product of the Iraq War), 'LibLogs' (library blogs), and 'EduBlogs'." The various taxonomies identified in the scholarship have not coalesced into any kind of consensus: blogs can be and are grouped formally, by the audience or effects they aim for, by the degree of publicness or privateness they manifest, by the kinds of authors they feature, and by the kinds of content they highlight.
Despite this continuing debate, it is possible to discern broad categories of topic, tone, and audience in the blogosphere, for purposes of overview, if nothing else. At one end of the spectrum, among the most visible, well-read, well-studied, and profitable blogs are those dedicated to journalism, politics, and tabloid-style celebrity gossip: for example, The Drudge Report, The Huffington Post, and Talking Points Memo count in the first or second categories, while Go Fug Yourself, Gawker, and Pink is the New Blogfall in the latter. Obviously, varying degrees of credibility, seriousness, and impact accrue to each, but they share several characteristics. Many of these blogs mimic the mainstream media in their organization as for-profit businesses supported by advertising revenue and driven by readership statistics. Bloggers on these sites often earn salaries and may be supported by research, secretarial, and technical staff. Thus, we can number among this type of blog also some of the sites created by established media organizations to supplement their pre-existing print and online materials, such as the Chronicle of Higher Education's News and WiredCampus blogs. As the readership of this particular category of blog has expanded, so too has commercialization of the genre. As with the mainstream media, commercially supported blogs are largely financed by advertising revenue. Other blogs, particularly political blogs, may be supported by reader donation. Banner ads populate the larger sites, but even more small-scale operations can profit from Google AdSense ads or partnerships with online retailers. Blogs that adopt the commercial model face many of the same pressures the established mass media addressed throughout the twentieth century: attracting more advertising revenue by capturing larger shares of the available audience.
This very public category of blog occupies only a tiny corner of the blogosphere, but garners a disproportionate share of media and academic attention. As Shawn McIntosh observes,
The power and potential of blogs does not come from sheer numbers, but rather from the inordinate amount of power to influence media coverage as public opinion leaders that a handful of bloggers have acquired in a very short time.
(2005: 385)
McIntosh is largely speaking about influential political and journalistic blogs, which fall into the "notebook" or "filter" genres, or Koh et al.'s (2005) "non-personal" category. This type of blog is far more likely to be written for an audience of strangers, with a purpose of providing commentary on public or political events. Further, these blogs tend to boast more readers than average, which may help account for their dominance in press accounts of blogging. McIntosh surmises as well a certain "inside baseball" aspect to the disproportion of attention and influence that accrues to these politics-and-current-events blogs. On average, Koh et al. (2005) find that this group of writers, whom they nominate "non-personal" bloggers, are more likely to be well-educated, older males. The National Institute for Technology and Liberal Education, similarly, in its breakdown of blog content authorship, finds that while the blogo-sphere as a whole achieves near-parity in terms of gender, in the subset of political websites (6 percent of the sites it surveyed), a mere 4 percent were authored by women (NITLE 2003b). Gossip and entertainment blogs — not journalism, but not diaries; informal but not personal — were not factored explicitly into these studies, and it would be interesting to determine the generic and demographic characteristics of these very popular sites; they appear to be even more overlooked than the online diaries Laurie McNeill identifies as underserved by scholarship.
At the other end of the blog genre spectrum may be counted the personal blogs, generally considered to be HTML inheritors of paper-based genres of life writing: autobiography, memoir, journal, scrapbook, and diary. McNeill sees in the blogo-sphere "an unparalleled explosion of public life writing by public citizens" (2003: 25), while noting quite rightly that "these Web diaries and blogs have received little academic attention" (2003: 26). To address this lack, Viviane Serfaty offers a "structural approach" to the study of this subset of the blogosphere, ascertaining a set of shared generic characteristics common to most: accumulation, referring to the piling-on of multimedia detail in the construction of the textual self, whereby text and image and links reinforce or call into question the diarist's persona (2004: 459–60); open-endedness, or the episodic and non-cumulative accretion of posts that distinguish diaries from autobiographies or memoirs (2004: 461–2); a doubled self-reflexivity that addresses both the nature of internet life-writing as well as the diarist's motivation for writing in the first place (2004: 462–3); and co-production, the deliberate construction of the text for an audience that is able to respond to or to collaborate in the diarist's project of self-presentation or self-construction (2004: 465). Threads of commentary, posts, and trackbacks can be complex and tightly woven in these diary-blogs, despite the above-noted paucity of outbound links compared to punditry or digest blogs, giving a real feel of community to many of these sites, which may have core readerships in the single digits. Serfaty and McNeill each carefully link blog-based life-writings to prior internet forms (such as the "online diaries" in simple HTML that began appearing around 1995) as well as to print antecedents (that is, paper journals and diaries, and scrapbooks). The demographics of this subgenre are the inverse of those manifest in the more "public" kinds of blogging described above. On LiveJournal, online diaries are generated disproportionately by the young to communicate with their immediate circle of real-world acquaintance. Its age distribution curve peaks at 18 (419,000 registered users self-identified as this age) with the greatest concentration of bloggers falling in the 16–22-year-old range (LiveJournal 2006). Of those users who indicated their sex, interestingly, two-thirds self-identified as female.
The online diary genre of blog exerts a tremendously powerful pull on both readers and writers. As Serfaty notes, via the intermediary of the computer screen which both veils the computer user and reflects back his image to himself, "diarists feel they can write about their innermost feelings without fearing identification and humiliation, [while] readers feel they can inconspicuously observe others and derive power from that knowledge" (2004: 470). Koh et al.'s (2005) research shows that these personal bloggers are twice as likely as the more public bloggers to write for an audience of ten or fewer readers; non-personal bloggers are more than twice as likely to write for an audience of 100–500 people. Similarly, personal bloggers are nearly four times as likely to write for an audience known personally to themselves, while non-personal bloggers are more than four times more likely than the diarists to write specifically for an audience of strangers. Finally, about 75 percent of personal bloggers take as their primary content "Events in my life," "Family and home," and "Religious beliefs," while non-personal bloggers show a clear preference — in the range of 50 percent — for the categories "News," "Entertainment and Arts," and "Government and Politics" (Koh et al. 2005). This split, in which the smallest part of the blogosphere garners the most study and is taken to stand in for the whole, bears further investigation, and thus far it has been mostly undertaken by the life-writing and autobiography studies community.
In between these poles lies the vast and shifting middle ground, occupied by aspiring writers seeking both audiences and book contracts with provocative and literate projects, and professionals of all stripes creating classic digest-style blogs on their areas of expertise designed to appeal to a specific core of similarly trained readers, for example Matthew G. Kirschenbaum's blog in new media studies, MGK, or computing humanist Jill Walker's jill/txt. In this middle terrain we can also locate artists publishing multimedia blogs as creative outlets — photoblogs, vlogs or video blogs, storyblogs, and the like (see <http://www.photoblogs.org> or <http://www.freevlog.org> for examples of some of these). Of course, mobility among categories is quite fluid in these early days of blogging, with mainstream paper-based journalists like Dan Gillmor shifting to primarily blog-based writing, political bloggers like Markos Moulitsas Zuniga (Daily Kos) attaining press credentials and being interviewed on television and radio, and prurient personal/gossip blogs like Jessica Cutler's formerly anonymous Washingtonienne leading to public exposure and a contract for a book based on her blog. Many projects are hard to categorize neatly. New York municipal worker Julie Powell's online saga of her quest to get through every recipe in Julia Child's seminal Mastering the Art of French Cooking in one year was at once styled like a memoir (a time-delimited personal account) and a more public form of writing (the blog, Julie/Julia, was sponsored and hosted by online magazine Salon). This blog ultimately won the inaugural "Blooker Prize" (i.e., the "Booker Prize" of the blogosphere) and led to a rewriting of its contents for book publication.
Some of the generic instability of blogging has led to unexpected negative consequences and the articulation and debate of new ethical dilemmas — and to neologisms like "dooced," a verb describing a loss of employment as a result of blogging, named for fired blogger Dooce, whose eponymous blog has now become her source of income. Fundamentally, very much at issue are questions of libel and liability, of the distinctions between public and private writing, and tests of the notions of civility, propriety, and ethical behavior online. These topics remain to be explored by scholars in depth, or, indeed, at all.
Reading Blogs
Rebecca Blood (2000) surmises interestingly that just as blogs became poised to tap into a mainstream readership and become a fundamental and daily web technology, the ease of creation and maintenance provided by the new CMS-based blogging software led to such a massive increase in the number of blogs that would-be readers were simply overwhelmed. Rather than filter the internet into manageable or digestible (and entertaining) bits as blogs had heretofore been doing, the blogosphere itself seemed to become as vast and unnavigable as the World Wide Web. Reading blogs became complicated. Since that time (Blood was writing about the scene circa 1999), tools to enable readers to search for blogs of interest have developed. Many blogs acquire readers who have taken their direction from mainstream media reports. With many newspapers featuring "blogwatch" columns, and with their own online components increasingly incorporating blogging in some form (necessarily linking to other blogs), the MSM and blogging are leading readers to each other, in many cases readers who might seek out the Globe and Mail directly, but not a blog directly, for example. Otherwise, straightforward internet searches using Google or other tools often yield blogs among their top results, owing to blogs' ever-increasing numerical heft in the broader web ecosystem. Blog-specific search tools have evolved as well, sites ranking and rating various blogs, and offering neophyte readers a sense of the biggest and most popular blogs, as well as the capacity to topic-search only the blogosphere. Within the blogosphere itself, blogrolls and carnivals are self-organized mechanisms of recommendation and a kind of peer-review.
Special-purpose search engines catering to the blogosphere now make finding blog content easier. Google's blog-only search tool (<http://blogsearch.google.com>) uses the same interface as their regular search engine; its familiarity makes it quite popular. A simple Google search using the keyword that describes the content you're looking for, and "blog" as a second term, can also accomplish much the same end. More locally, hosting services like LiveJournal and Blogger also provide search tools, of their own sites, or of the blogosphere more generally. Of blog-specific search tools, though, Technorati is probably the best known. Technorati maintains statistics on the readership and unique page visits of high-profile blogs, and compiles lists of the most popular as well as the most referenced blogs online. It allows also for searching by post content, by blog keyword, or by most-recently-updated. The Truth Laid Bear (<http://truthlaidbear.com>), similarly, is a high-profile one-man-show run by the pseudonymous "N. Z. Bear," a computing industry professional who — as a hobby — has developed a system to compile traffic and link statistics for various blogs. It maintains a list of the most popular blogs, as determined by user traffic as well as by links to the blogs from other sites: this list is oft-consulted and very influential. TTLB calls its organization of the blogosphere the "ecosystem," and its rankings, as well as those of Technorati, are closely watched both by bloggers themselves as well as by the mainstream media.3TTLB's ranking lists can be organized by number of inbound links (which may attest to a blog's authority, working much like the citation index offered in academic databases like Web of Science), or by number of daily visits, a marker of raw popularity. Both lists offer the raw numbers on which the rank is based, direct links to the blog in question, and a link to further details of the ranking, in which graphs show a week's worth of daily statistics on inbound links and page views, as well as a listing of recent posts and links to these posts. One of the strengths of TTLB's system is that it is always current: it bases its rankings only on links and visits from the previous 7–10 days, so mobility in the rankings is widespread and watching the rankings shift is something of a spectator sport. For readers who wish to follow a number of blogs, aggregators like Bloglines (<http://www.bloglines.com>) save the effort of manually checking each site for updates. It allows readers to take advantage of RSS technologies by subscribing to various feeds at any number of blogs, and reading the content all in one place, a dynamic and personalized page where the latest updates are automatically collected and presented.
The blogroll, a sidebar link list pointing outward to other blogs, is the simplest blog filtering tool: it works on the principle that if you like my blog, then you'll probably like these other blogs that I like as well. Blogrolls can even break their lists into categories — this blogroll subset links to other blogs on the topic of knitting; this blogroll subset comprises what I feel to be the "best in show" of the blogosphere; this blogroll subset addresses Mac enthusiasts; this blogroll is comprised of blogs that link to me. Communities of interest are formed in the intersection of blogs in the blogroll. Bloggers have also developed blog "carnivals," regularly appearing, edited, rotating-host digests of submitted blog posts on particular topics. One carnival clearinghouse site links carnivals to print traditions, suggesting that "a Blog Carnival is like a magazine. It has a title, a topic, editors, contributors, and an audience. Editions of the carnival typically come out on a regular basis" ("FAQ"). One of the first was the "Carnival of the Vanities," a collection of well-written and interesting reads culled from the increasingly vast and noise-ridden blogosphere; carnivals now appear on nearly every subject imaginable, from humor to politics to sports to philosophy. According to blogger Bora Zivkovic (2005), successful carnivals share five characteristics: carnivals must "a) have a clearly stated purpose, b) appear with predictable regularity, c) rotate editors, d) have a homepage and archives, and e) have more than one person doing heavy lifting." Zivkovic's criteria are obviously debatable — for example, his criterion of clear and preferably narrow purpose excludes from consideration carnivals like Vanities.
What distinguishes blog carnivals from being simply blog posts — after all, blog posts also by nature and tradition digest and point to articles of interest on the greater internet — are the following characteristics: items appearing in carnivals are submitted to the blogger/editor by their authors; these items are chosen for publication based on their appeal to a wider community/audience and on their adherence to a particular topic, rather than simply reflecting the taste and whim of the carnival editor; posts in a carnival reference only other blog posts, and not other kinds of websites (that is, not personal webpages, or news sites, or organizational press releases, for example). Blog carnivals also, as Zivkovic notes, tend to rotate editors and location: Carnival of Bret Easton Ellis might appear this month on my blog under my editorship, while next month it is hosted by you on yours. Hosting a carnival is an excellent way to attract your target audience to your blog. Some carnivals are archived at third party sites, ensuring that readers can follow an unbroken chain of iterations. Blog carnivals can be located and accessed various ways. Blog Carnival Index (<http://www.blogcarnival.com>) has tracked nearly 4,000 editions of 290 different carnivals, maintaining lists of which carnivals are active, and the submission deadlines and editorial info pertaining to each carnival. It supports browsing and searching for particular carnivals by date updated, carnival name, and by category. Blog Carnival Index also provides forms by which would-be carnival posters and editors can submit their information to the carnivals of their choice, a handy feature that helps to automate what might otherwise become an onerous and time-consuming task. Blog Carnival Index has recently partnered with The Truth Laid Bear, and TTLB's "Ubercarnival" lists are based on Blog Carnival data. Blog carnivals have caught on particularly with academic communities — they offer a sort of blogosphere peer-review, in that carnival posts must be submitted to and (increasingly) vetted by an editor before being launched on the world. As the blogosphere expands and the submissions to a carnival exceed its capacity to publish, control of quality and of topic are imposed, leading to a digital publication that more closely resembles the conventions of the dissemination of ideas in print.
Writing
In 1997, according to Rebecca Blood, there were twenty-three blogs — you could follow them all, know the bloggers, and feel a part of a tight-knit community. By 1999, it had become nearly impossible to manually track all the blogs, and new ones began appearing faster than they could be counted or assimilated into the prior community. Since then, writing blogs has become a tremendously popular pastime, to judge from the rate of new blog creation tracked by Technorati — recall their statistic that 75,000 new blogs were being created every day. Pew as well surmised from its research that 11 million American internet users were also bloggers (Rainie 2005). While not all of these blogs remain active over the long or even medium term —the proportion of LiveJournal blogs that are deemed "active" comprise only one-fifth of registered sites on the host — the sheer bulk of new blogs indicates a strong and growing public interest in this form of online expression. As the form has come into its own, with increasingly standard technologies, layouts, interactions, and best practices, blogging has experienced growing pains. Particularly vexing have been issues of responsibility, liability, professionalism, privacy, and decorum — that is to say, we have entered just another digital culture debate! As the blogosphere expanded, the rules of the game within it changed, and the outside world also began to take notice. The relations between the digital and analog worlds seemed strained from the beginning, with liberties taken in the blogosphere harshly addressed outside of it. These intersections between the digital world and the more mundane one we generally inhabit offer fruitful topics for further research.
Notably (and apparently newsworthily, to judge from the MSM coverage of these incidents), many of the first wave of these new bloggers — not computing professionals, not digesting or filtering internet content but rather publishing personal information in diary-style posts on the new CMS blogging software — were distressed to find themselves being fired for their online activities (see Hopkins (2006) for a list, circa 2004).4 Most of these bloggers seemed to rely on "security by obscurity": that is, thinly disguising their own identities (providing a different name for self and cat, while naming their actual employer, or vice versa) and remaining optimistic that no one they knew would read them, or that anyone would bother to decode their identities. This has not proven an altogether foolproof tactic. As a result, the Electronic Frontier Foundation (2005), acting to increase the liberty and security of netizens on a variety of fronts since 1990, offers an online guide to secure blogging, complete with a step-by-step guide to better anonymization as well as an outline of legal precedent and advice on "how to blog without getting fired". As the EFF notes, "anyone can eventually find your blog if your real identity is tied to it in some way. And there may be consequences," including distraught family members and friends, disturbed potential employers, and litigious current ones. The EFF's guide is a good place for budding bloggers to begin.
Academic bloggers face similar personal and professional pressures when they blog, but are drawn to the form for compelling reasons, among them the opportunities to network with scholars they might not otherwise meet, to avoid academic isolation if theirs is an arcane subspecialty, to test new ideas on a willing expert audience in an informal manner, to ask for help from this same audience, and to keep abreast of colleagues and research. Nevertheless, academic blogging has its detractors. An opinion piece by "Ivan Tribble" for The Chronicle of Higher Education in July 2005 (2005a) saw the pseudonymous senior academic opine on the negative impact blogging had on the prospects of job candidates interviewed at his institution: he goes so far as to caution that "the content of the blog may be less worrisome than the fact of the blog itself," a pretty clear denunciation of the very idea of blogging. This column, unsurprisingly, generated a digital outpouring of indignation, most notably on Kirschenbaum's blog. In his response to Tribble's article, Kirschenbaum (2005) challenged his audience to offer up the tangible benefits they had earned from their blogging activities: this is as good and as thoughtful a defense of academic blogging as one is likely to find in this informal medium. Tribble references this blog post and its comments in his follow-up column "They Shoot Messengers, Don't They?" (2005b). Similar commentary on the Chronicle's Academic Job Forum continues the (somewhat paranoid) debate. However, elsewhere on the Chronicle, another essayist describes the blogosphere as "a carnival of ideas" which "provide a kind of space for the exuberant debate of ideas, for connecting scholarship to the outside world" (Farrell 2005). Yet another column, by David D. Perlmutter (2006), who is preparing a book for Oxford University Press on political bogging, proclaims the urgency of the questions "What are blogs? How can we use them? What exactly are they good for?" for students of politics as well as its practitioners. A piece by Robert Boynton (2005) for the "College Week" edition of Slate summarizes the professional-concerns response of the academy to blogs and blog culture. Often generating more heat than light, these writings nonetheless indicate the challenge that this particular writing genre poses to the academy, and as with other online practices before it, invigorates the debate about the values as well as the failings of our established pedagogical, research, and collegial practices.
Blogging in Literary Studies
Blogging has its attractions for scholars, as a venue for writing, teaching, and occasionally primary and (more occasionally still) secondary research. Many very worthwhile blogs (particularly in humanities computing, as technophilic a group of early adopters as the humanities and social sciences might hope to nurture) offer information of use to the literary studies community, providing annotated and focused lists of resources and offering opportunities for rich interaction among blog-readers and blog-writers. Popular books on the techniques and social impacts of blogging increasingly abound, as does coverage of the various parts of the blogo-sphere in the mainstream media. The academic scholarship that studies blogs is slightly thinner on the ground, and has thus far made more appearances in journals (both peer-reviewed and not) and in blogs than in book-length studies. This scholarship can be broken into several categories. Most numerous are the investigations of the intersections between mainstream media — particularly journalistic media — and blogging. Questions of blog-provoked revisions to journalistic practices and ethics, often articulated in the form of a crisis of authority and relevance, appear in the journals devoted to communications studies, journalism, and new media and society (e.g. McIntosh 2005, Robinson 2006). In a similar vein are analyses of the impacts of blog readership and authorship on political processes, particularly in the United States, but also in the context of activist or dissident blogging around the world (e.g. Kerbel and Bloom 2005, Riverbend 2005, Perlmutter 2006).5 A critical as well as informal literature details experiments with the use of blogging technologies and practices in writing and other pedagogies (e.g. Krause 2004, Ellison and Wu 2006, Tyron 2006; more informal assessments of blogs in teaching can be found on the blogs of teachers who employ them, as well as within class blogs themselves).6 As well, the literary studies community has begun to examine the links between diary-style blogging and other forms of life writing (e.g. McNeill 2003, Serfaty 2004). Of course, researchers in cyberculture and new media studies are as keen to understand the operations and implications of this new form as they are to participate in shaping it. Online, the Weblog Research on Genre (BROG) Project offers a wealth of research papers as well as lists to other prominent research-oriented sites such as Into the Blogosphere (Gurak et al. n.d.). In short, the field of research on, and practice in, blogging is just opening up. Certainly, as YouTube is gobbled up by Google while the mass media hails the internet video age, and as the culture at large clues into youth-oriented social networking sites like Facebook and MySpace, it is clear that blogging's time as media-darling will soon enough draw to a close. But the form is established enough, the needs it meets real enough, its format alluring enough, and its community of practice large enough that bloggers will continue to write and scholars will continue to examine them, likely for a long time to come.

Digital Literature: Surface, Data, Interaction, and Expressive Processing
Introducing Digital Literature
Digital literature — also known as electronic literature — is a term for work with important literary aspects that requires the use of digital computation.
While vastly different in their critical approaches, both books employed examples from previously-neglected forms of digital literature such as interactive fiction, story generation systems, and interactive characters. These forms grow out of a heritage of computer science research, especially in artificial intelligence. The work of both Murray and Aarseth has since had an influence on interpretations of another once-neglected form of digital media that grows out of computer science, often employs artificial intelligence, and can have important literary aspects: computer games. In the years since these publications, significant work in digital literature has continued, ranging from the first book-length examination of the form of interactive fiction (Montfort 2003) to new theoretical approaches such as "media-specific analysis"
Models for Reading Digital Literature
The starting point for this chapter is an observation: When studying a work of digital literature, as with any cultural artifact, we must choose where to focus our attention. To put this another way, we must operate with some model (explicit or implicit) of the work's elements and structures — one which foregrounds certain aspects while marginalizing others.
Most critical work in digital literature — whether focused on hypertext or other forms — proceeds from an implicit model that takes audience experience to be primary. The main components of the model are the surface of the work (what the audience sees) and the space of possible interactions with the work (ways the audience may change the state of the work, and how the work may respond).
The primary competitors to this implicit model are Aarseth's explicit models presented in Cybertext. The most important of these is a typology for discussing textual media, consisting of scriptons (text strings as they appear to readers), textons (text strings as they exist in the text), and traversal functions (the mechanism by which scriptons are revealed or generated from textons). This model, here referred to as the "traversal function" model, has been highly influential.
This chapter will consider one of the most famous works of digital literature: James Meehan's Tale-Spin (1976). Meehan's project is the first major story generation program. It made the leap from assembling stories out of pre-defined bits (like the pages of a Choose Your Own Adventure book) to generating stories via carefully-crafted processes that operate at a fine level on story data. In Tale-Spin's case, the processes simulate character reasoning and behavior, while the data defines a virtual world inhabited by the characters. As a result, while altering one page of a Choose Your Own Adventure leaves most of its story material unchanged, altering one behavior rule or fact about the world can lead to wildly different Tale-Spin fictions. For this reason Meehan's project serves as an example in the books of Bolter, Murray, and Aarseth, among others.
This chapter argues that Tale-Spin is not just widely discussed — it is also widely misunderstood. This is demonstrated in several stages, beginning and ending with readings of Tale-Spin (and its companion text generator, Mumble) that employ the implicit audience model. Between these readings, the chapter will, first, attempt to apply Aarseth's traversal function model, second, trace the operations of Tale-Spin's simulation, and, third, present a new model that helps clarify the issues important for a notion I call expressive processing. This new model differs from the audience model by, following Aarseth, including the work's mechanisms. It differs from Aarseth's model, however, by not assuming that the transition from textons to scriptons is either (a) readily identifiable or (b) the primary site of interest. Instead, after having identified the interplay between the work's data, process, surface, and possibilities for interaction, it is proposed that groupings of these may be considered as operational logics and explored both as authorial expressions (following Michael Mateas's notion of Expressive AI (2002)) and as expressing otherwise-hidden relationships with our larger society (particularly the cultures and materials of science and technology).
For Tale-Spin in particular, its primary operational logic is revealed to be that of the planning-based simulation. It is deeply connected to the cognitive science account of planning that has been extensively critiqued by scholars such as Lucy Suchman and Phil Agre (Suchman 1987; Agre 1997). It is also, more broadly, a "microworld" approach to AI of the sort that, by failing to scale up, resulted in the symbolic AI "winter" beginning in the 1980s. For the purposes of this chapter, it can be particularly valuable in two regards. First, it provides a legible example of the inevitably authored — inevitably fictional — nature of simulations of human behavior. Second, as we increasingly create human-authored microworlds as media (e.g., digital literature and computer games) it provides a fascinating example and cautionary tale.
Taking a step back, and realizing that none of this is visible from the audience's perspective, a new term is proposed. Just as the "Eliza effect" is used to describe systems that give the audience the impression of a much more complex process than is actually present, the "Tale-Spin effect" may be used to describe the obscuring of a complex process so that it cannot be perceived by the audience. The existence of these two effects helps demonstrate that the implicit audience model provides only a partial view of digital literature.
Reading Tale-Spin's's Outputs
From an audience perspective, a story generation program such as Tale-Spin is mostly experienced through its outputs — through the texts it produces. Many critics agree that this is Tale-Spin's most famous output:
Joe Bear was hungry. He asked Irving Bird where some honey was. Irving refused to tell him, so Joe offered to bring him a worm if he'd tell him where some honey was. Irving agreed. But Joe didn't know where any worms were, so he asked Irving, who refused to say. So Joe offered to bring him a worm if he'd tell him where a worm was. Irving agreed. But Joe didn't know where any worms were, so he asked Irving, who refused to say. So Joe offered to bring him a worm if he'd tell him where a worm was
(129–30)
Two things are curious here. First, this text is rather unimpressive for being the most famous output of one of the most widely discussed works of digital literature. It raises the question: Why does this work open nearly every computer science treatment (and many critical treatments) of digital fiction?
Second, and even more curiously, this is not actually an output from Tale-Spin. Rather, it is, as Meehan says, a "hand translation" (127) into English, presumably performed by Meehan, of an internal system state originally represented as a set of "conceptual dependency" (CD) expressions. Further, the output above was produced early in the creation of Tale-Spin, before the system was complete. To publish this as one of Tale-Spin's tales is akin to printing a flawed photograph taken with a prototype camera, while it still has light leaks, and using this to judge the camera's function.
Let's begin with the second of these curiosities. Why would authors such as Aarseth and Murray present these hand-transcribed errors — what Meehan refers to as "mis-spun tales" — rather than actual Mumble outputs of Tale-Spin story structures? We can begin to get an idea by examining some of the system's actual output:
George was very thirsty. George wanted to get near some water. George walked from his patch of ground across the meadow through the valley to a river bank. George fell into the water. George wanted to get near the valley. George couldn't get near the valley. George wanted to get near the meadow. George couldn't get near the meadow. Wilma wanted George to get near the meadow. Wilma wanted to get near George. Wilma grabbed George with her claw. Wilma took George from the river through the valley to the meadow. George was devoted to Wilma. George owed everything to Wilma. Wilma let go of George. George fell to the meadow. The End.
(227–8, original in all caps.)
Now, here are two mis-spun tales from similar scenarios:
Henry Ant was thirsty. He walked over to the river bank where his good friend Bill Bird was sitting. Henry slipped and fell in the river. He was unable to call for help. He drowned.
Henry Ant was thirsty. He walked over to the river bank where his good friend Bill Bird was sitting. Henry slipped and fell in the river. Gravity drowned.
(128–9, Meehan's parenthetical explanation removed.)
All three of these drowning ant stories are quite strange. But they're not strange in the same way. The first story — the successful story, from Tale-Spin's perspective — might make one ask, "Why is this language so stilted?" or "Why are these details included?" or "What is the point of this story?" The second and third story — the mis-spun stories — on the other hand, elicit questions like, "Why didn't his 'good friend' save Henry?" or "How is it possible that 'gravity drowned'?"
To put it another way, the first example makes one wonder about the telling of the story, while the second and third make one wonder how such a story could come to be. These errors prompt readers to think about systems. And this, in turn, offers insight into the first curiosity mentioned after Joe Bear's story above. Tale-Spin begins so many computer science discussions of digital fiction because of the operations of its system — its processes — rather than any qualities of its output. Given this, it seems essential that an analysis of Tale-Spin at least consider these processes. This chapter will return, later, to the conclusions of those who read Tale-Spin employing an implicit audience model. The next section will attempt to employ Aarseth's traversal function model in studying Tale-Spin and Mumble.
Locating Tale-Spin's Traversal Function
In order to employ Aarseth's traversal function model one must identify its three elements: scriptons (text strings as they appear to readers), textons (text strings as they exist in the text), and traversal functions (the mechanism by which scriptons are revealed or generated from textons). For example, when interacting with a simulated character such as Eliza/Doctor, the scriptons are the texts seen by audience members, the textons are the simple sentence templates stored within the system, and determining the traversal function provides a typological classification of how system operations and audience behavior combine to produce the final text (Weizenbaum 1966).
Aarseth, unfortunately, while he discusses Tale-Spin, does not analyze it employing his model. However, on a table on page 69 of Cybertext he does provide its traversal function. So to employ Aarseth's model one need only identify the scriptons and textons in Tale-Spin/Mumble. Finding the scriptons is easy. They are the sentences output by Mumble in stories such as those reproduced above.
Finding the textons is harder. Tale-Spin operates at the level of story structure, not story telling. In particular, Tale-Spin focuses on simulating a virtual world — its characters, its objects, and their histories and plans. As mentioned above, there are no English sentences inside Tale-Spin. Its virtual world, instead, is represented in the form of "conceptual dependency" (CD) expressions. These expressions were developed as a language-independent meaning representation in the "scruffy" branch of 1970s AI research, especially in efforts headed by linguist and computer scientist Roger Schank and psychologist Robert Abelson.
Schank was Meehan's dissertation advisor during the period of Tale-Spin's completion. He outlines the basic form of CD expressions in Conceptual Information Processing (1975), presenting them as multidimensional diagrams. When used for projects such as Tale-Spin, however, CD expressions are generally represented as parenthesis-organized lists. So, for example, what Mumble outputs as "George was very thirsty" might be represented in a program like Tale-Spin as:
(WORLD '(THIRSTY (ACTOR GEORGE) (VAL (7))))
Similarly, what Mumble outputs as "George wanted to get near some water" might be represented in a manner such as this:
(GEORGE '(GOAL (ACTOR GEORGE) (AT GEORGE WATER)))
Are CD expressions the textons of Tale-Spin/Mumble? It seems unlikely. Aarseth's phrase "strings as they exist in the text" sounds more like Eliza/Doctor's pre-existing sentence templates, rather than parenthesis-ordered lists created during Tale-Spin's run.
Unfortunately, Mumble doesn't provide us with any better texton candidates. It contains no sentence templates or other recognizable texts. Instead, when presented with a CD expression for output, it first identifies the expression's main act, state, or connective. For example, in the expression above, that George has a goal. The first thing produced is a subject-verb pair, such as "George wanted … " Then nouns are inserted. If George wanted to go to particular water and the simulation indicated that, at that time, the water belonged to a particular character, then the possessive would be added (e.g., "get near Arthur's water"). If the simulation history indicated that George had already been there then Mumble would choose words to indicate this (e.g., "return to Arthur's water"). Once the main words are present in the correct order, Mumble goes through inserting articles and punctuation.
In other words, Mumble assembles sentences on the fly, using a body of knowledge about English and accessing information from Tale-Spin's simulation. Each sentence is based on a CD expression, but not all CD expressions are employed, and most CD expressions used do not exist before the particular run for which they help form the output. Given this, it seems clear that Tale-Spin/Mumble does not provide us with a set of clear textons, of obvious "strings as they exist in the text." Nevertheless, we still have an idea of the elements that go into producing the system's scriptons, and this may be enough to allow a discussion of its traversal function.
Aarseth's presentation of traversal functions identifies a set of "variables" — the values of which define the function. These are a mixture of elements that include audience activity and system behavior. Specifically, drawing from Aarseth's pages 62–5: Dynamics describes whether the work's surface and data can change in particular ways — remaining static, with only surface variability, or also variability in the number of pieces of textual data in the system. Determinability describes whether the work's processes operate predictably in their production of textual output, or if the processes for producing surface texts can be influenced by unpredictable factors (e.g., randomness) and so yield different responses to the same audience actions. Transiency describes whether the work's processes cause surface texts to appear as time passes (e.g., as in textual animations). Perspective describes whether an audience member determines the strategic actions of a particular character. Access describes whether all possible surface texts are available to an audience member at any time (e.g., a book can be flipped through, so its surface texts are "random" access). Linking describes types of user-selectable connections that may be presented by the work's surface (such as links on World Wide Web pages) which may be always available, available under certain conditions, or simply not present. User functions are Aarseth's last variable. Every text makes available the "interpretive" user function to its audience. Other possible functions include the "explorative" (selecting a path), "configurative" (selecting or creating scriptons), and "textonic" (adding textons or traversal functions).
So the traversal function here is not simply the means by which Tale-Spin triggers English-language output from Mumble. Rather, the traversal function encompasses the work's operations in a number of manners. Given this, in order to go further one must investigate the operations of the Tale-Spin simulation.
Tale-Spin's Simulation
Tale-Spin was intended to be a storytelling system built on a veridical simulation of human behavior. As Meehan puts it:
Tale-Spin includes a simulator of the real world: Turn it on and watch all the people. The purpose of the simulator is to model rational behavior; the people are supposed to act like real people.
(107)
The basis of this simulation was the work being done Schank, Abelson, and the researchers working with them. For example, each Tale-Spin story begins with a character with a problem, what the group called a "sigma-state." A problem might be solved by a simple act (e.g., if a hungry character has food then she can eat it). But if a problem can't be solved by a basic act, then the character must plan to change the state of the world so that it can be. In the group's terminology such a plan was called a "delta-act." For example, if the character does not have food then she may plan to change the world so that she does have food.
However, things don't stop there. Any delta-act may, itself, have pre-conditions that aren't present in the current state of the world. For example, getting food may require knowing where some food is located, and a character may not know. Or a delta-act may include several "planboxes" that represent different approaches to a problem, which are considered serially.
Each time something is made true about the world ("asserted") Tale-Spin automatically works through many inferences from it. For example, if it is asserted that a character is thirsty (i.e., if a CD expression is added to the simulation that expresses this fact) then the inference mechanisms result in the character knowing she is thirsty, forming the goal of not being thirsty, forming a plan (a chain of delta-acts) for reaching her goal, etc. Crafting these inferences was an important part of authoring Tale-Spin. For example, in an early version of the system, when a character traveled to a place other characters nearby did not "notice." (The inference mechanism from the act of travel didn't give knowledge of the character's new location to those nearby.) This lack resulted in the mis-spun tale, quoted above, in which Henry Ant drowns while his friend Bill Bird sits nearby, unresponsive.
Take, for example, the beginning of an example story, drawn from Meehan's chapter 11. Initially, Tale-Spin asks what characters to use for the story, and the audience chooses a bear and a bird. Tale-Spin gives the characters names (Arthur Bear and George Bird), homes, basic physical characteristics, etc. Next the audience is given a list of possible miscellaneous items to create in the world, and chooses a worm. The audience is asked who knows about the worm, and chooses Arthur Bear. Tale-Spin then asks who the story will be about (the audience chooses Arthur) and what his problem is ("hunger" is chosen).
Through inference, Arthur forms the goal "Arthur has some food." Tale-Spin checks to see if it's already true, and it's not. Then Tale-Spin checks to see if it's already a goal. It's not, so it is added to Arthur's goal structure. This second check is performed for two reasons. Most obviously, because if it is already his goal (or a subgoal toward a higher goal) then it makes little sense to add it. But another reason to check for the goal's existence is that Tale-Spin also keeps failed goals, and the reasons for their failure, as part of a character's goal structure. Before this was added to the system it was easy to create mis-spun tales like the one quoted earlier in this chapter — Tale-Spin's best-known product: Joe Bear forming the goal of bringing Irving Bird a worm over and over.
The first step in the plan Arthur forms, since he doesn't know where to find any honey, is to ask someone else where there is honey. He knows the location of George Bird, so the audience is asked how Arthur conceives of his relationship with George (e.g., does Arthur think that George likes him?). The answers are encouraging, so Arthur travels to ask George (after Tale-Spin creates the parts of the world that lie between them). Oddly enough, the CD expressions for this sort of travel seem to be sent to Mumble for output in full. The example quoted above, when the ant "walked from his patch of ground across the meadow through the valley to a river bank," is actually one of the less egregious.
When Arthur reaches George's tree he asks George to tell him the location of some honey. Again, the audience is asked for information about George and Arthur's relationship, this time from George's perspective. The answers lead to George believing that Arthur will believe whatever he says. Given this, George starts to speculate —the Tale-Spin inference mechanisms are used not to change the state of the world but for one character to "imagine" other possible worlds. George draws four inferences from Arthur believing there is honey somewhere, and then he follows the inferences from each of those inferences, but he doesn't find what he's after. In none of the possible worlds about which he's speculated is he any happier or less happy than he is now. Seeing no advantage in the situation for himself, he decides, relatively arbitrarily, to answer. Specifically, he decides to lie.
So George creates, in Tale-Spin's memory, a set of CD expressions that aren't yet believed by anyone — including himself. These describe Ivan Bee, and Ivan's honey, which exist at a particular location (a location which Tale-Spin creates in support of George's plan). Of course, it must be a lie, because honey is not among the miscellaneous items that the audience chose to create at the outset of the story.
Observations on the Simulation
Arthur's saga continues, but enough has been said to allow a few observations. The first is that this Tale-Spin story contains quite a bit of psychological "action." Characters are weighing how they view their relationships with each other, spinning out many possible worlds to look for ones in which they achieve benefit, making multi-stage plans, telling elaborate lies, and so on. This is the material from which fiction is made.
However, in contrast to the detailed description of travel itineraries, the CD expressions that describe psychological action are almost never sent to Mumble. While Meehan doesn't provide the Mumble output for the story of Arthur and George, here is an excerpt from a story containing similar events:
Tom asked Wilma whether Wilma would tell Tom where there were some berries if Tom gave Wilma a worm. Wilma was inclined to lie to Tom.
(232)
All the psychological action described above between George and Arthur, in some version, took place for Wilma and Tom as well. But one would never know it from the output. Instead, by far the most interesting events of Wilma and Tom's Tale-Spin story take place in the gap between these two Mumble sentences. From an audience perspective Wilma's decision to lie might as well have been determined by a random number.
On the subject of randomness, it is also worth noting that George's decision to answer Arthur was not really arbitrary. Rather, seeing no advantage to any world about which he can speculate, Tale-Spin has George decide whether to answer based on his kindness. The audience is asked, and decides that George is "somewhat" kind. So, as Meehan puts it, he decides to answer "out of the goodness of his little heart" (183). But then the answer that George chooses to give, out of kindness, is a lie about honey that doesn't exist. This isn't a simulation of George thinking Arthur should diet, but a breakdown in the simulation. The component of Tale-Spin that determines what answer to give doesn't have any knowledge of the fact that the answer is being provided out of kindness.
There is much more that could be discussed about Tale-Spin's simulation, but, for now, this is enough to return to this chapter's attempt to employ Aarseth's model.
Tale-Spin's Traversal Function
As noted above, Aarseth provides Tale-Spin's traversal function to readers of Cybertext. Specifically, Aarseth reports that Tale-Spin has "textonic dynamics" (the number of textons is variable), is "indeterminable" (perhaps Aarseth identifies a random element in Tale-Spin), is "intransient" (it does nothing if not activated by the user), has an "impersonal perspective" (the user is not playing a strategic role as a character), has "controlled access" (not all the possible scriptons are readily available), has no linking, and has a "configurative user function."
This seems largely accurate. But it may also clarify why Aarseth doesn't employ his model in his discussion of Tale-Spin. This model doesn't turn attention to Tale-Spin's most salient features. As seen above, the action in Tale-Spin's simulation — its most telling operations — are in the formation, evaluation, and execution of plans. Most of this action is never output by Mumble — it never becomes scriptons. So a model that focuses on the traversal function "by which scriptons are revealed or generated from textons" is going to miss the primary site of action as well.
Further, the basic components of Tale-Spin and Mumble are hard to think about using Aarseth's model. We've already discussed the difficulty in recognizing textons within Tale-Spin/Mumble. The difficulty also runs the other direction. How should we think about Tale-Spin's processes for inference making or character planning? They aren't mechanisms for turning textons into scriptons, except extremely indirectly. They aren't pointed at by "textonic dynamics" or a "configurative user function" or any of Aarseth's other variables.
Given this, I believe it is time to consider alternative models. As these models are developed it seems important to retain Aarseth's focus on system operations, such as the mechanisms by which surface text is produced. At the same time, it also seems necessary to abandon the particular focus and specific elements of his model in favor of concepts that will support consideration of a wider variety of digital literature.
A New Model
In developing a new model it may prove useful to diagram some of the alternatives, as in the diagram of an implicit audience model in Figure 8.1.
In this model the audience(s) can see the media object and engage with it through interaction. The interaction may produce some change visible to the audience(s), but what happens inside the object is unknown, as is the object's internal structure. Also, while it is known that the work is authored, the "author function" is represented in gray — author studies having been explicitly set aside by most critics. The focus is on the object as it is visible to (and can be acted upon) by the audience(s).
We might diagram Aarseth's traversal function model somewhat differently. Figure 8.2 shows an attempt.

Figure 8.1 An implicit audience model of digital media.
In this model the audience(s) can see the scriptons and also work through the scripton surface to provide some of the variables of the traversal function that generates/reveals scriptons from textons (as well as, in some cases, contribute scriptons and/or textons). The textons, in most cases, along with some traversal function variables, are provided by the grayed out author(s).
Neither of these make a very good fit with the elements we've discussed of Tale-Spin and Mumble, which can be diagram in a manner such as in Figure 8.3.
This diagram represents the audience reading Mumble's output on a teletype or terminal and typing replies to questions at the same point, creating a combined text. Audience responses to questions feed into Tale-Spin's processes, leading to CD expressions being asserted, developing the facts and history of the simulated world.

Figure 8.2 An attempt at diagramming Aarseth's traversal function model.

Figure 8.3 The elements of Tale-Spin and Mumble.
Inferences are drawn from assertions, using Tale-Spin processes, resulting in the assertion of further CD expressions (and possibly triggering character planning operations, world building operations, travel operations, etc.). A subset of CD expressions are sent to Mumble's natural language generation processes, resulting in English-language output at the teletype or terminal. The Tale-Spin and Mumble processes, along with the structure of the CD data, were authored by Meehan (building on concepts then current at the Yale AI lab).
This is a quite complicated picture — and one may be inclined to think twice about it as the starting point for a model. And yet, as a work of digital literature, the structure of this system is in some ways quite simple. A brief comparison with two of my collaborative works as an author of digital literature may help to demonstrate this point.
First, in Tale-Spin/Mumble, audience display and interaction happen through a single, text-only device. But in a work like Screen (Wardrip-Fruin et al. 2003–5), created with collaborators at Brown University, the site of display and interaction includes a room-sized virtual reality display (the Cave), shutter glasses synchronized with the display via infrared pulses, and magnetic motion trackers attached to the audience member's body (Figure 8.4). This allows words (of short fictions exploring memory as a virtual experience) to appear to peel from the walls, fly around the reader, be struck with the hand, split apart, and return to the walls in new places to create altered versions of the original texts.
To take another example, the structure of Tale-Spin/Mumble is relatively simple because all of its processes and data can exist, self-contained, on one computer.

Figure 8.4 Screen, a digital fiction for the virtual reality Cave.
Another piece on which I collaborated, The Impermanence Agent (Wardrip-Fruin et al. 1998–2002) is significantly more complex in this regard (Figure 8.5). First, because it is a work for the World Wide Web that includes operations both on the server and on audience members' computers, its processes and data are split across two computers even for a single audience member. Further, while the work's processes were all defined by the authors, the work's data was different for each audience member. The Impermanence Agent monitored each reader's web browsing (presumably across many far-flung web servers) and incorporated parts of images and sentences from each individual's browsing into the version of its story (of documents preserved and destroyed) being performed for that reader. And it is important to realize that neither this work's split across multiple computers nor its indeterminacy of data is uncommon. They are also present for many other web works, as well as for other digital forms such as virtual worlds (e.g., massively multiplayer online games).
These two examples are only the proverbial tip of the iceberg in the complex and rapidly developing field of digital literature. Given this, how can one construct a model that will accommodate the variety of work being done in the field, provide a vocabulary useful for talking comparatively about different works, and help turn attention to the aspects significant to individual works? I offer a proposal here, but recognize that any such proposal should be preliminary, open to rejection or refinement by others, and perhaps most useful in helping us see how individual works differ from the generic. My model might be visualized as shown in Figure 8.6.
All works of digital literature are somehow presented to their audiences — whether on teletypes, in web browser windows, through immersive installations, or by other means. If the audience is able to interact with the work, the means for this are also part of the work. I will call this site of presentation and (possible) interaction the work's surface. It may be as simple as a generic personal computer, consist of a large space or dizzying number of devices, or even take unexpected form (e.g., The Impermanence Agentmakes all web browsing part of its interaction surface).

Figure 8.5 The Impermanence Agent customizes its story of impermanence for each reader, using material from that reader's web browsing.

Figure 8.6 The proposed model of digital literature.
Works of digital literature also — whether they are organized as one or more systems, and whether they exist across one or more computers — operate via processes that employ data. This is not always obvious. For example, an email narrative may appear to consist entirely of data: the text of the email messages. But an email narrative cannot be email without the processes of the audience's email readers and at least one email server. Here the model follows Chris Crawford's vocabulary in his discussion of process intensity (1987) rather than the vocabulary of computer science (which might substitute a word such as algorithm for process).
While there are many definitions of interaction, for the purposes of this model I define it as a change to the state of the work, for which the work was designed, that comes from outside the work. Given this, the audience is not the only possible source of interaction. It is also worth noting that, in many cases, some trace of interaction is immediately apparent on the surface (e.g., an audience member types and the letters appear as they are typed, or an audience member moves her hand and a video image of her hand moves simultaneously) but this is not required. Interaction, while it always changes the state of the work, can be approached with the primary goal of communication between audience members.
The author is still present in this model, but the arrows representing attribution of different elements are gone. This is because we cannot predict which portions of a work will be created by authors. An installation-based work may present a physical surface almost entirely constructed by one or more authors, while an email narrative may be presented on a physical device, and using an email reading program, individually selected by each audience member. The data employed in a piece may be created by the author, contributed by the audience, generated through processes, or selected from pre-existing sources by the author, audience, or processes. Or it may be a mixture. The same is true of processes. An author may simply select among those provided by a tool such as Flash, or authors may write or modify programming language code, or the audience may be involved in process definition. The authorial status of a work may even be unknowable.
Employing the Model
As the above discussion suggests, this model can help us consider work comparatively. Just as Aarseth's model points us toward comparisons along variables such as linking, this model points us toward comparisons along variables such as the form the work's surface takes, the sources of the data employed, the state changes produced by interaction, and so on.
It also provides a structure for thinking about the operations of a work's processes —and the relationship of processes to data, surface, and interaction — more broadly than in terms of texton/scripton traversal functions. We can ask, "What is the work doing?" without expecting that we already know the answer ("turning textons into scriptons"). That is to say, in addition to comparison, I believe this model also helps us consider individual works specifically and give appropriate weight to their internal operations.
As readers have likely noticed, the work of viewing Tale-Spin through this model is already underway in this chapter. There has already been discussion of its processes, data, surface, and interaction. We've already seen — e.g., in the example of George Bird incoherently lying out of kindness — the way the specifics of the system operations can present revealing gaps between what the system is presented as doing (acting as "a simulator of the real world," in Meehan's words) and what it actually does. We've also seen how the most interesting operations of a work — e.g., George Bird imagining the many worlds in which Arthur believes there is honey somewhere, searching for his own advantage — may never be visible on the work's surface. Hopefully these are convincing demonstrations that tracing an algorithm's steps (watching the interplay between process and data over time) can be an important type of critical reading for digital literature. Putting this type of reading on a more equal footing with audience-perspective readings is a primary goal of this model.
What hasn't yet been explored is the wider view that this sort of examination can help develop. Tale-Spin has many fascinating processes, from its inference mechanisms to its simulation of interpersonal dynamics to its creation of virtual geography. I would argue that — by tracing the interplay between Tale-Spin's surface, data, and process — one may be able to abstract from these to characterize the logic of operations such as inference. One can then discuss this operational logic itself, as well as identify this logic, and different approaches to this logic, in works with implementations (surface, data, and process) that differ from Tale-Spin's. And, crucially, one can also go further, because there is a central operational logic that can be identified in Tale-Spin.
This central logic is planning. One can identify it by looking carefully at the contexts in which the other logics come into play. Consider those that create the geography of the virtual world. Tale-Spin does not begin by modeling a virtual world that includes all its characters and objects. Rather, many spaces, and the connections between spaces, only come into existence once one character begins to plan to travel from one place to another. The same is true of the logics that simulate interpersonal relationships. Tale-Spindoes not create a world and then determine how all the characters feel about each other. Rather, none of the feelings that characters have about each other are determined until one of them begins to plan for interaction with the other. And characters have no feelings or other characteristics that are not those needed for Tale-Spin's simulation of rational planning. Consider the following statement from Meehan's dissertation in terms of our culture's stories of love — for example, any Hepburn and Tracy movie:
"John loves Mary" is actually shorthand for "John believes that he loves Mary." … I'm not sure it means anything — in the technical sense — to say that John loves Mary but he doesn't believe that he does. If it does, it's very subtle.
(64)
In fact, it is not subtle at all. It is a significant plot element of the majority of romantic novels, television shows, and movies produced each year. But from within Tale-Spin's central logic his conclusion is perfectly rational. If John doesn't know that he loves Mary, then he cannot use that knowledge in formulating any conscious plans — and in Tale-Spin anything that isn't part of conscious planning might as well not exist.
This blindness to all but planning — this assumption that planning is at the center of life — was far from unique to Meehan. Within the wider AI and cognitive science community, at the time of Meehan's work, the understanding and generation of plans was essentially the sole focus of work on intelligent action. Debate centered on what kind of planning to pursue, how to organize it, and so on — not on whether planning deserved its central place as a topic for attention. This was in part due to the field's technical commitments, and in part the legacy of a long tradition in the human sciences. Lucy Suchman, writing a decade later in her book Plans and Situated Actions (1987), puts it this way:
The view, that purposeful action is determined by plans, is deeply rooted in the Western human sciences as the correct model of the rational actor. The logical form of plans makes them attractive for the purpose of constructing a computational model of action, to the extent that for those fields devoted to what is now called cognitive science, the analysis and synthesis of plans effectively constitute the study of action.
(ix—x)
This view has, over the last few decades, come under widespread attack from both outside and within AI. As Suchman puts it, "Just as it would seem absurd to claim that a map in some strong sense controlled the traveler's movements through the world, it is wrong to imagine plans as controlling action" (189). As this has happened —and particularly as the mid-1970s theories of Schank, Abelson, and Meehan have moved into AI's disciplinary history — Tale-Spin has in some sense lost its status as a simulation. There's no one left who believes that it represents a simulation of how actual people behave the in the world.
As this has taken place, Tale-Spin has become, I would argue, more interesting as a fiction. Its logics can no longer be regarded as an accurate simulation of human planning behavior, with a layer of semi-successful storytelling on top of it. Rather, its entire set of operations is now revealed as an authored artifact — as an expression, through process and data, of the particular and idiosyncratic view of humanity that its author and a group of his compatriots once held. Once we see it this way, it becomes a new kind of fiction, particularly appreciable in two ways. First, it provides us a two-sided pleasure that we might name "alterity in the exaggerated familiar" — one that recalls fictions such as Calvino's Invisible Cities — which presents us with the both strange and recognizable image of life driven only by plans within plans. At the same time, it also provides an insight, and cautionary tale, that helps us see the very act of simulation-building in a new light. A simulation of human behavior is always an encoding of the beliefs and biases of its authors — it is never objective, it is always a fiction.
Resurfacing
Having spent most of this chapter on an examination of Tale-Spin's internal operations (and on proposing a model of digital literature that provides space for such examinations) this chapter will now return to Tale-Spin's surface by considering two examples of what has been written by those noted earlier in this chapter as operating via an implicit audience model.
Janet Murray, in her book Hamlet on the Holodeck (1997), writes of Tale-Spin in the context of her argument that writers "need a concrete way to structure a coherent story not as a single sequence of events but as a multiform plot" (185). Murray reprints the famous mis-spun tale of Joe Bear forming the failed goal, over and over, of bringing Irving Bird a worm, and then writes:
The program goes into a loop because it does not know enough about the world to give Joe Bear any better alternatives. The plot structure is too abstract to limit Joe Bear's actions to sequences that make sense.
(200)
In fact, as discussed earlier, Tale-Spin looped because — in its partially-completed state at the time this mis-spun tale was generated — its characters could reassert a goal that had already failed. Further, Joe Bear's problem had to happen at the character level — it could not happen at the level of "plot structure" — because Tale-Spin has no representation of plot at all. Murray's failure to understand Tale-Spin/Mumble's operations leads to a missed opportunity. As the next chapter of her book demonstrates, she is very interested in systems that model the interior operations of fictional characters. And characters like Joe Bear and George Bird have quite complex interior operations, if one looks beyond the anemic events output by Mumble, making them a good potential example for arguments like Murray's.
In Cybertext, on the other hand, Tale-Spin is one of Aarseth's three primary examples for the argument that machine narrators should not be "forced to simulate" human narrators (129). Tale-Spin is presented as a failed example of such simulation, with its mis-spun tales its only claim to interest. From the viewpoint of AI, Aarseth's is an exceedingly strange argument. The primary critique of Tale-Spin in AI circles is precisely that it does not attempt to simulate a human narrator. Tale-Spin simulates characters — not narrators, not authors. We can overlook this, however, because Aarseth is arguing against simulating human narrators only as a proxy for their assumed poetics. He writes:
To achieve interesting and worthwhile computer-generated literature, it is necessary to dispose of the poetics of narrative literature and to use the computer's potential for combination and world simulation in order to develop new genres that can be valued and used on their own terms.
(141)
Of course, as our examination of its operations shows, Tale-Spin can be seen as precisely the sort of literature for which Aarseth is calling. The story structures it produces are almost never like those that a human storyteller would produce. Instead, it uses "combination and world simulation" to produce strange branching structures of plans within plans within plans. From this it is possible to see that, for Aarseth, too, Tale-Spin could serve as a strong positive (rather than misleading negative) example.
Aarseth's missed opportunity, combined with Murray's missed opportunity, helps to reveal something interesting. Tale-Spin, early as it was, stands at an important crossroads. If we choose to emphasize its continuities with traditional fiction and drama, via its characters, then it becomes a useful touchstone for views such as Murray's. If we choose to emphasize its complicated strangeness, its computational specificity, then it becomes an important early example for views such as Aarseth's. In either case, a close examination of the system's operations reveals something much more intriguing than either author assumed.
And there is also something further that can be learned from considering the readings of these two generally insightful scholars. Even dedicated, careful researchers were unable to see what might interest them about Tale-Spin by looking at the Mumble output. Its fascinating operations were completely hidden, when viewed from the surface perspective.
There is, in fact, a term for works that, when viewed from the surface, seem (at least at first) much more complex and interesting than they actually are: the "Eliza effect," in reference to Joseph Weizenbaum's early interactive character. I would like to propose a companion term, inspired by what we see here about Tale-Spin/Mumble's surface: the "Tale-Spin effect" which describes works that have complex and interesting internal processes that are hidden when the work is viewed from the surface.
I believe the Tale-Spin effect is important to consider for two reasons. First, scholars of digital literature must be aware that the surface may not reveal the aspects of a work that will be most telling for analysis (a case in which scholars may miss what a work's processes express). Second, and just as importantly, authors of digital literature must realize that an interesting, successful, hidden process will offer less to an audience even than the visible errors produced by a broken process, as can be seen with Tale-Spin's mis-spun tales (a case in which authors are not effectively employing processes in their expression through the work). In both cases, I believe that a model organized around the relations of surface, data, process, and interaction — and their interplay in operational logics — may provide fruitful insights into expressive processing.

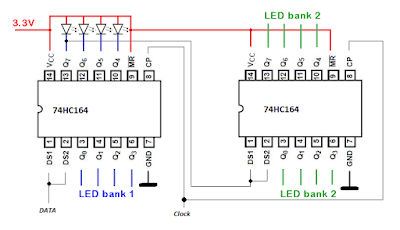
Basic Memory in Electronic circuits
Writing R/W in AVOMETER DIGITAL
Overview of Computers
- Two systems of computers:
1) PC – the Personal Computer; 2) Mac – the Apple Macintosh.
- Two designs of computers:
| 1) desktop |  | 2) laptop (notebook) |  |
- Computer architecture:
Main components of a computer
|
Multimedia devices
|
Other peripheral devices
|
1) computer
2) monitor
3) hard disk/ hard drive
4) keyboard
5) mouse / trackball /
touch pad
|
1) CD-ROM / DVD drive
2) video card
3) soundcard
4) speakers
5) headphones / headset
6) microphone
|
1) printer
2) scanner
3) CD- burner (CD- recorder,
CD-R/CD-RW drive)
4) modem
5) USB flash drive
6) webcam
7) digital camera
8) digital voice recorder
9) camcorder
|
Inside the Computer
1) Processor:
The CPU (Central Processing Unit), a complete computation engine that is fabricated on a single chip, is the computer’s brain. It is sometimes referred to as the central processor, microprocessor, or just processor. Two typical components of a CPU are: 1) the arithmetic logic unit (ALU), which performs arithmetic and logical operations, and 2) the control unit, which extracts instructions from memory and decodes and executes them, calling on the ALU when necessary.
Most newer PCs have Pentium processors. Pentium processors run faster than the numbered processors found in older computers (286, 386, 486 processors). The speed of processors, called the clock speed, is measured in megahertz (MHz) or gigahertz (1 GHz = 1000 MHz). One MHz represents one million cycles per second. For example, a processor that runs at 200 MHz executes 200 million cycles per second. Each computer instruction requires a fixed number of cycles, so the clock speed determines how many instructions per second the microprocessor can execute. To a large degree, this controls how powerful the processor is.
2) Memory:
ROM (Read Only Memory) is the computer’s permanent, long-term memory. It doesn't disappear when the computer is shut off. It can not be erased or changed in anyway. However, there are types of ROM called PROM that can be altered. The P stands for programmable. ROM's purpose is to store the basic input/output system (BIOS) that controls the start-up, or boot process.
RAM (Random Access Memory) is a working area where the operating system (e.g. Windows), programs and data in current use are kept, ready to be accessed by the processor. It is the best known form of computer memory. However, RAM, unlike ROM, is emptied when the computer is switched off. The more RAM you have, the quicker and more powerful your computer is.
There are two basic types of RAM: dynamic RAM (DRAM) and static RAM (SRAM).
The two types differ in the technology they use to hold data. DRAM, the more common type, needs to be refreshed thousands of times per second. SRAM does not need to be refreshed, which makes it faster, but it is also more expensive than DRAM.
Memory is measure in the following units:
- 1 byte = 8 bits (Each 1 or 0 is called a bit (i.e. binary digit). Each character (i.e. a letter, a number, a space, or a punctuation mark) has its own arrangements of 8 bits, e.g. 01000001 = “A”, 01000010 = “B”.
- 1 KB (kilobyte) = 1024 (210) bytes
- 1 MB (megabyte) = 1024 (210) KB
- 1 GB (gigabyte) = 1024 (210) MB
Cache (pronounced as "cash") is a buffer (made of a small number of very fast memory chips) between main memory and the processor. It temporarily stores recently accessed or frequently-used data. Whenever the processor needs to read data, it looks in this cache area first. If it finds the data in the cache, then the processor does not need to do more time-consuming reading of data from the main memory. Memory caching allows data to be accessed more quickly.
3 Storage Devices
The most common forms of storage devices in a home computer are:
- Hard disk drive
- Floppy disk
- CD-ROM
- CD-R and CD-RW
- DVD-ROM
- USB flash drives
1) Hard disk and hard drive (HD)
A hard disk is a magnetic disk on which you can store computer data on a more permanent basis. The term “hard” is used to distinguish it from a soft, or floppy, disk. Hard disks hold more data and are much faster than floppy disks and optical disks. A hard drive is a mechanism that reads and writes data on a hard disk. The capacity of hard drives in newer PCs ranges from 20GB to 60GB in size since all software, from operating systems to word processors, and media files have grown tremendously in size over the last few years.
2) Floppy disk and floppy drive
A floppy disk (often called floppy or disk) is a soft magnetic disk and a floppy drive is a mechanism that reads and writes data on a floppy. Unlike most hard disks, floppy disks are portable, because you can remove them from a disk drive. Floppy disks are slower to access than hard disks and have less storage capacity, but they are much less expensive.
The common size of floppies for PCs made before 1987 was 5¼ inches. This type of floppy was generally capable of storing between 100KB and 1.2MB of data. After 1987 the size reduced to 3½ inches, but the data storage capacity increased, from 400KB to 1.44MB. The most common sizes for PCs are 720KB (double-density) and 1.44MB (high-density).
3) Optical disk and optical drive
Optical disks can store information at much higher densities than floppy disks. Thus, they are ideal for multimedia applications where images, animation and sound occupy a lot of disk space. Besides, they are not affected by magnetic fields. This means that they are secure and stable; for example, they can be transported through airport metal detectors without damaging the data. However, optical drives are slower than hard drives.
There are various types of optical disks and drives:
A) CD-ROM (short for “Compact Disk-Read-Only Memory”) and CD-ROM drive
A CD-ROM, an optical disk onto which data has been written via a laser, can store everything, from shareware programs to dictionaries and encyclopedias, from multimedia databases to 3-D games. CD-ROMs are considered the most economical devices of storing and sharing information. For example, a CD-ROM (700 MB) can replace 300,000 pages of text (about 50 floppies), which represents a lot of savings in distributing materials and data. Yet, you can only read information on a CD-ROM but cannot write anything on it.
A CD-ROM drive is used to play CD-ROMs and it can also play audio CDs. CD-ROM drives are available in a variety of different speeds, the speed being described thus: 12x, 16x, 24x, 32x, 48x, etc. This indicates the speed at which data can be pulled off the CD-ROM drive. Higher-speed CD-ROM drives help to transfer data more quickly, which is crucial when playing sound or video.
B) CD-R, CD-RW and CD-R/CD-RW drive (also called CD-burner or CD-Recorder)
CD-R (short for “Compact Disk Recordable”) drives record data on CD-R disks (but write once only), allowing you to create and duplicate CD-ROMs and audio CDs. They can also be used to back up hard disks or to distribute and archive information. CD-RW (short for “Compact Disk Rewritable”) drives can erase and reuse data on CD-RW disks. In fact, to create CD-ROMs and audio CDs, you'll need not only a CD burner, but also a CD-R/CD-RW software package.
C) DVD-ROM (“DVD” is short for “digital video disk” or “digital versatile disk”)
A DVD-ROM (or just DVD) is a type of optical disk technology similar to the CD-ROM. It can hold up to 17 GB of data, about 25 times an ordinary CD-ROM. For this reason, a DVD-ROM can store a large amount of multimedia software and complete movies in different languages. It can also play music CDs and CD-ROMs. DVDs are read-only devices. To avoid this limitation, companies also produce DVD-R/DVD-RW disks and DVD-burners.
4) USB flash drive
A USB flash drive is a small, portable flash memory card that plugs into a computer’s USB port and functions as a portable hard drive with up to 2GB of storage capacity. USB flash drives are easy-to-use because they are small enough to be carried in a pocket and can plug into any computer with a USB drive. In addition, they are very durable because they do not contain any internal moving parts. USB flash drives also are called pen drives, key drives, or simply USB drives.
4 Monitor
There are two types of monitors available for PCs: the traditional CRT (cathode ray tube) and the newer LCD (liquid crystal display). The CRT is used for both televisions and computers. It produces a good quality image at a number of different settings for a reasonable price. LCD monitors, also known as flat panel displays, are used in laptop (or notebook) computers and more frequently for desktops as well. They are lighter and smaller (only inches thick) than CRTs with reduced electromagnetic emissions and power consumption.
5 Video Card
The card here is a jargon for an electronic circuit board. Video cards are also known as graphics cards, which are responsible for displaying 2D and 3D images on your monitor. 2D graphics are the regular pictures and images that appear on your screen while 3D graphics are mostly used in games and imaging.
Video cards control the resolution of the text, pictures and video that appears on the screen, i.e. the screen resolution (e.g., 800 x 600 pixels, 1024 x 768 pixels). Most modern video cards are accompanied by the software that enables you to control the resolution of the display screen according to the software that you are using. The lower the numbers, the lower the resolution. Remember that getting the video card setting wrong is a common reason for failing to get software to work properly.
6 Sound Card
A sound card is an electronic circuit board that is mounted inside the computer to control sound output to speakers or headphones, to record sound input from a microphone connected to the computer, and to manipulate sound stored on a disk. Sound cards are essential for multimedia applications and have become common on modern personal computers.
A popular make of soundcard is SoundBlaster, which has been the de facto standard sound card. Most sound cards in the past have been Sound Blaster-compatible, which means that they can process commands written for a Sound Blaster card, because most programs that use a sound card have been designed that way. Nowadays, many sound cards are also Windows-compatible. Many multimedia applications require the system to have a Windows-compatible sound card to run properly.
7 Ports
A port is an interface on a computer to which you can connect a device. Personal computers have various types of ports. Internally, there are several ports for connecting disk drives, monitors, and keyboards. Externally, personal computers have ports for connecting modems, printers, mice, and other peripheral devices.
There are three common types of external ports that usually come with a computer:
| 1) Parallel ports (for most printers) |  |
2) Serial ports (for most modems and some mice)
|   |
3) USB (Universal Serial Bus) ports (for about every peripheral made in a USB version)
*Note: A “bus” is a set of conductors that carry signals between different parts of a computer
|   |
The USB (Universal Serial Bus) provides a single, standardized, easy-to-use way to connect up to 127 devices to a computer. The USB connectors let you attach everything from mice to printers to your computer more quickly and easily than the other two. The operating system supports USB as well, so the installation of the device drives is quick and easy, too.

Most of us use a computer every single day, but few people know about the inner workings of this vital part of our lives.
The word computer refers to an object that can accept some input and produce some output. In fact, the human brain itself is a sophisticated computer, and scientists are learning more about how it works with each passing year. Our most common use of the word computer, though, is to describe an electronic device containing a microprocessor.
A microprocessor is a small electronic device that can carry out complex calculations in the blink of an eye. You can find microprocessors in many devices you use each day, such as cars, refrigerators and televisions. The most recognized device with a microprocessor is the personal computer, or PC. In fact, the concept of a computer has become nearly synonymous with the term PC
When you hear PC, you probably envision an enclosed device with an attached video screen, keyboard and some type of a pointing device, like a mouse or touchpad. You might also envision different forms of PCs, such as desktop computers, towers and laptops. The term PC has been associated with certain brands, such as Intel processors or Microsoft operating systems. In this article, though, we define a PC as a more general computing device with these characteristics:
- designed for use by one person at a time
- runs an operating system to interface between the user and the microprocessor
- has certain common internal components described in this article, like a CPU and RAM
- runs software applications designed for specific work or play activities
- allows for adding and removing hardware or software as needed
PCs trace their history back to the 1970s when a man named Ed Roberts began to sell computer kits based on a microprocessor chip designed by Intel. Roberts called his computer the Altair 8800 and sold the unassembled kits for $395. Popular Electronics ran a story about the kit in its January 1975 issue, and to the surprise of just about everyone, the kits became an instant hit. Thus, the era of the personal computer began
While the Altair 8800 was the first real personal computer, it was the release of the Apple II a couple of years later that signaled the start of the PC as a sought-after home appliance. The Apple II, from inventors Steve Jobs and Steve Wozniak, proved that there was a demand for computers in homes and schools. Soon after, long-established computer companies like IBM and Texas Instruments jumped into the PC market, and new brands like Commodore and Atari jumped into the game.
Core PC Components
The following are the components common to PCs in the order they're typically assembled:
Case -- If you're using a laptop, the computer case includes keyboard and screen. For desktop PCs, the case is typically some type of box with lights, vents, and places for attaching cables. The size of the case can vary from small tabletop units to tall towers. A larger case doesn't always imply a more powerful computer; it's what's inside that counts. PC builders design or select a case based on the type of motherboard that should fit inside.
Motherboard -- The primary circuit board inside your PC is its motherboard. All components, inside and out, connect through the motherboard in some way. The other components listed on this page are removable and, thus, replaceable without replacing the motherboard. Several important components, though, are attached directly to the motherboard. These include the complementary metal-oxide semiconductor (CMOS), which stores some information, such as the system clock, when the computer is powered down. Motherboards come in different sizes and standards, the most common as of this writing being ATX and MicroATX. From there, motherboards vary by the type of removable components they're designed to handle internally and what ports are available for attaching external devices.
Power supply -- Other than its CMOS, which is powered by a replaceable CMOS battery on the motherboard, every component in your PC relies on its power supply. The power supply connects to some type of power source, whether that's a battery in the case of mobile computers, or a power outlet in the case of desktop PCs. In a desktop PC, you can see the power supply mounted inside the case with a power cable connection on the outside and a handful of attached cables inside. Some of these cables connect directly to the motherboard while others connect to other components like drives and fans.
Central processing unit (CPU) -- The CPU, often just called the processor, is the component that contains the microprocessor. That microprocessor is the heart of all the PC's operations, and the performance of both hardware and software rely on the processor's performance. Intel and AMD are the largest CPU manufacturers for PCs, though you'll find others on the market, too. The two common CPU architectures are 32-bit and 64-bit, and you'll find that certain software relies on this architecture distinction.
Random-access memory (RAM) -- Even the fastest processor needs a buffer to store information while it's being processed. The RAM is to the CPU as a countertop is to a cook: It serves as the place where the ingredients and tools you're working with wait until you need to pick up and use them. Both a fast CPU and an ample amount of RAM are necessary for a speedy PC. Each PC has a maximum amount of RAM it can handle, and slots on the motherboard indicate the type of RAM the PC requires.
Drives -- A drive is a device intended to store data when it's not in use. A hard drive or solid state drive stores a PC's operating system and software, which we'll look at more closely later. This category also includes optical drives such as those used for reading and writing CD, DVD and Blu-ray media. A drive connects to the motherboard based on the type of drive controller technology it uses, including the older IDE standard and the newer SATA standard.
Cooling devices -- The more your computer processes, the more heat it generates. The CPU and other components can handle a certain amount of heat. However, if a PC isn't cooled properly, it can overheat, causing costly damage to its components and circuitry. Fans are the most common device used to cool a PC. In addition, the CPU is covered by a metallic block called a heat sink, which draws heat away from the CPU. Some serious computer users, such as gamers, sometimes have more expensive heat management solutions, like a water-cooled system, designed to deal with more intense cooling demands.
Cables -- All the components we've mentioned so far are connected by some combination of cables. These cables are designed to carry data, power or both. PCs should be constructed so that the cables fold neatly within the case and do not block air flow throughout it.
A PC is typically much more than these core components.
Ports, Peripherals and Expansion Slots

Ideally, your computer will have enough ports that you won't have to jumble all your accessories together. If you find yourself in a jam like this, consider whether or not you need all those peripherals.
The core components we've looked at so far make up a PC's central processing power. A PC needs additional components, though, for interacting with human users and other computers. The following are the PC parts that make this happen:
Graphics components -- While some motherboards have on-board graphics, others include what's called an expansion slot, where you can slide in a separate video card. In both cases, the video components in a PC process some of the complex graphics data going to the screen, taking some of the load off your CPU. A motherboard accepts video cards based on a specific interface, such as the older AGP standard or one of the newer PCI standards.
Ports -- The word port is often used to describe a place on the outside of your PC where you can plug in a cable. Describe a port by its use, such as a USB port or an Ethernet port. (Note that the word port is also used to describe a software connection when two pieces of hardware try to communicate.) Many ports are affixed directly to the motherboard. Some of the ports you'll find on a PC include the following:
- USB ports
- network ports, typically Ethernet and FireWire
- video ports, typically some combination of VGA, DVI, RCA/component, S-Video and HDMI
- audio ports, typically some combination mini analog audio jacks or RCA
- legacy ports, or ports that follow old standards which are rarely used in modern computers, such as parallel printer ports and PS2 ports for a keyboard and mouse
Peripherals -- Any piece of hardware that isn't mounted inside a PC's case is called a peripheral. This includes your basic input and output devices: monitors, keyboards and mice. It also includes printers, speakers, headphones, microphones, webcams and USB flash drives. Anything you can plug in to a port on the PC is one of the PC's peripherals. The essential peripherals (such as monitors) aren't necessary on laptops, which have them built in instead.
Expansion slots -- On occasion, you'll want to add components to a PC that don't have a designated slot somewhere on the motherboard. That's why the motherboard will include a series of expansion slots. The removable components designed to fit into expansion slots are called cards, probably because of their flat, card-like structure. Using expansion slots, you can add extra video cards, network cards, printer ports, TV receivers and many other custom additions. The card must match the expansion slot type, whether it's the legacy ISA/EISA type or the more common PCI, PCI-X or PCI Express types.
When you first power up a PC, the machine goes through several internal processes before it's ready for you to use. This is called the boot process, or booting the PC. Boot is short for bootstrap, a reference to the old adage, "Pull yourself up by the bootstraps," which means to start something from the very beginning. The boot process is controlled by the PC's basic input-output system (BIOS).
The BIOS is software stored on a flash memory chip. In a PC, the BIOS is embedded on the motherboard. Occasionally, a PC manufacturer will release an update for the BIOS, and you can carefully follow instructions to "flash the BIOS" with the updated software.
Besides controlling the boot process, the BIOS provides a basic configuration interface for the PC's hardware components. In that interface, you can configure such things as the order to read drives during boot and how fast the processor should be allowed to run. Check your PC's documentation to find out how to enter its BIOS interface. This information is often displayed when you first boot the computer, too, with a message such as, "Press DEL to enter Setup Menu."
The following is a summary of the boot process in a PC:
- The power button activates the power supply in the PC, sending power to the motherboard and other components.
- The PC performs a power-on self-test (POST). The POST is a small computer program within the BIOS that checks for hardware failures. A single beep after the POST signals that everything's okay. Other beep sequences signal a hardware failure, and PC repair specialists compare these sequences with a chart to determine which component has failed.
- The PC displays information on the attached monitor showing details about the boot process. These include the BIOS manufacturer and revision, processor specs, the amount of RAM installed, and the drives detected. Many PCs have replaced displaying this information with a splash screen showing the manufacturer's logo. You can turn off the splash screen in the BIOS settings if you'd rather see the text.
- The BIOS attempts to access the first sector of the drive designated as the boot disk. The first sector is the first kilobytes of the disk in sequence, if the drive is read sequentially starting with the first available storage address. The boot disk is typically the same hard disk or solid-state drive that contains your operating system. You can change the boot disk by configuring the BIOS or interrupting the boot process with a key sequence (often indicated on the boot screens).
- The BIOS confirms there's a bootstrap loader, or boot loader, in that first sector of the boot disk, and it loads that boot loader into memory (RAM). The boot loader is a small program designed to find and launch the PC's operating system.
- Once the boot loader is in memory, the BIOS hands over its work to the boot loader, which in turn begins loading the operating system into memory.
- When the boot loader finishes its task, it turns control of the PC over to the operating system. Then, the OS is ready for user interaction.
PC Operating Systems

Microsoft Windows continues to be the most popular operating system in the world.
After a PC boots, you can control it through an operating system, or OS for short. As of this writing, most non-Apple PCs run a version of Microsoft Windows or a Linux distribution. These operating systems are designed to run on various kinds of PC hardware, while Mac OS X is designed primarily for Apple hardware.
An operating system is responsible for several tasks. These tasks fall into the following broad categories:
- Processor management -- breaks down the processor's work into manageable chunks and prioritizes them before sending them to the CPU.
- Memory management -- coordinates the flow of data in and out of RAM, and determines when to use virtual memory on the hard disk to supplement an insufficient amount of RAM.
- Device management -- provides a software-based interface between the computer's internal components and each device connected to the computer. Examples include interpreting keyboard or mouse input or adjusting graphics data to the right screen resolution. Network interfaces, including managing your Internet connection, also fall into the device management bucket.
- Storage management -- directs where data should be stored permanently on hard drives, solid state drives, USB drives and other forms of storage. For example, storage management tasks assist when creating, reading, editing, moving, copying and deleting documents.
- Application interface -- provides data exchange between software programs and the PC. An application must be programmed to work with the application interface for the operating system you're using. Applications are often designed for specific versions of an OS, too. You'll see this in the application's requirements with phrases like "Windows Vista or later," or "only works on 64-bit operating systems."
- User interface (UI) - provides a way for you to interact with the computer.
Since the first PC hit the market, newer and better models have made older models obsolete within months of production. Drive technologies like SATA replaced IDE, and PCI expansion slots replaced ISA and EISA. The most prominent gauge for technological progress in a PC, though, is its CPU and the microprocessor within that CPU.
Silicon microprocessors have been the heart of the computing world since the 1950s. During that time, microprocessor manufacturers have crammed more transistors and enhancements onto microprocessors. In 1965, Intel founder Gordon Moore predicted that microprocessors would double in complexity every two years. Since then, that complexity has doubled every 18 months, and industry experts dubbed the prediction Moore's Law. Many experts have predicted that Moore's Law will reach an end soon because of the physical limitations of silicon microprocessors .
As of this writing, though, processors' transistor capacities continue to rise. This is because chip manufacturers are constantly finding new ways to etch transistors onto the silicon. The tiny transistors are now measured in nanometers, which is one billionth of a meter. Atoms themselves are approximately 0.5 nm, and the most current production processes for microprocessors can produce transistors that measure 45 nm or 32 nm. The smaller that number goes, the more transistors will fit onto a chip and, thus, the more processing power the chip is capable of. As of May 2011, Intel was working on a 22-nm manufacturing process, code-named Ivy Bridge, which uses transistors with an energy-conserving design called Tri-Gate [sources: BBC, Intel].
So what happens when we reach the end of Moore's Law? A new means of processing data could ensure that progress continues. Potential successors are those that prove to be a more powerful means of performing the basic computational functions of a processor. Silicon microprocessors have relied on the traditional two-state transistor for more than 50 years, but inventions such as quantum computers are changing the game.
Quantum computers aren't limited to the two states of 1 or 0. They encode information as quantum bits, or qubits. A qubit can be a 1 or a 0, or it can exist in a superposition that is simultaneously 1 and 0 or somewhere in between. Qubits represent atoms that are working together to serve as both computer memory and microprocessor. Because a quantum computer can contain these multiple states simultaneously, it has the potential to be millions of times more powerful than today's most powerful supercomputers. Quantum computing technology is still in its early stages, but scientists are already proving the concept with real, measurable results.
Portable Personal Computing

Mobile computing devices will continue to become more and more prominent in the PC market.
Even before the PC, computer manufacturers were conceptualizing portable computers. It was the 12-pound IBM PC Convertible that brought the laptop concept into production in 1986. Since then, laptop computers have become smaller and lighter, and their processing power has improved alongside desktop PCs [source: IBM].
Today, the computer industry recognizes other classes of mobile computers. One class, the notebook, has become almost synonymous with the laptop. The term was originally used to indicate a smaller, lighter cousin to the laptop. Another class, the netbook, is even smaller than notebooks, while also being cheaper and less powerful. The classification is probably named for its target audience: those that want a very basic interface for using the Internet.
Mobile computing goes even further than notebooks and netbooks. Many smartphones and tablets have as much processing power as notebooks, packed into smaller packages. The key differences include a smaller screen size and resolution, fewer external ports, cellular phone capability and touch-screen technology, in addition to or in place of a keyboard.
On the software side, PC operating systems are also improving portability. For example, Google Chrome OS minimizes the need for hard drive space by relying on access to Web applications and cloud storage. This means a netbook that's limited to a 64 GB solid-state drive has the potential to be as useful as a laptop with a 500 GB disk drive. Naturally, large applications that aren't Web-enabled are the exception to this space-saving advantage.
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
e- Digital and Analog Text Combine and Connection
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Tidak ada komentar:
Posting Komentar