


Dynamo movement in component electronics is done either manually or using DC signals as well as data transmission on computer networks driven by digital signal signals that are started up by DC signals because all electronic equipment will run when DC power is given. on both traditional and hybrid internet networks are found many points where there is what is called ADA (Address - Data --- Accumulation), there is individual computer as manifested as a computer hardware system and interface while ADA on computer networks internationally or INTERNET is made through the network server that is connected to the modem as well as proxy points and fire wall which is where ADA is located, while the center of the ADA is in the future energy system called Future Energy Cloud as the ADA Data Bank. proxy points and fire walls and protocol traffic on the international network of computers on the earth moving networks that have been determined in each country where they are adapted to the best contour and climate in the country and on extraterrestrial systems. The bank data movement ADA uses the principle of the Dynamo Virtual movement that gets energy from the Cloud system. This virtual dynamo can move all existing electronic system networks on the earth where for the time being is on computer electronic communication machines and has not provided supply to other electronic machine tool equipment but can be driven if it is connected interface with international computer networks (INTERNET).
LOVE ( Line ON Victory Endless )


Gen. Mac Tech Zone Virtual Dynamo on e- WET
Virtual reality (VR) is a computer technology that uses virtual reality headsets or multi-projected environments, sometimes in combination with physical environments or props, to generate realistic images, sounds and other sensations that simulate a user’s physical presence in a virtual or imaginary environment.
Virtual Reality technologies will be more focused on the game and events sphere as it is already doing so in 2017 and will go beyond to add more evolved app usage experience to offer an elevated dose of entertainment for the gaming user.
We find:
With iPhone X, Apple is trying to change the face of AR by making it a common use case for masses. Also A whole bunch of top tech players think this technology which is also called a mixed reality or immersive environments — is all set to create a truly digital-physical blended environment for the people who are majorly consuming digital world through their mobile power house
Some of The Popular AR/VR Companies :
The smart objects will be interacting with our smartphone/tablets which will eventually function like our TV remort displaying and analyzing data, interfacing with social networks to monitor “things” that can tweet or post, paying for subscription services, ordering replacement consumables and updating object firmware.
Connected World:
- Microsoft is powering their popular IIS(Intelligent Systems Service) by integrating IoT capabilities to their enterprise service offerings.
- Some of the known communication technology powering IoT concept is RFID, WIFI, EnOcean, RiotOS etc….
- Google is working on two of its ambitious project called Nest & Brillo which is circled around usage of IoT to fuel your home automation needs. Brillo is an IoT OS which enables Wi-Fi, Bluetooth Low Energy, and other Android stuffs.
the virtual reality process is moved by future cloud energy with the virtual dynamo connection concept
The Dynamo Process
Dynamo Process by moving a magnet next to a closed electric circuit, or changing the magnetic field passing through it, an electric current could be "induced" to flow in it. That "electromagnetic induction" remains the principle behind electric generators, transformers and many other devices. .
That is showed that another way of inducing the current was to move the electric conductor while the magnetic source stood still. This was the principle behind his disk dynamo, which featured a conducting disk spinning in a magnetic field--you may imagine it to be spun up by some belt and pulley, not drawn here. The electric circuit was then completed by stationary wires touching the disk on its rim and on its axle, shown on the right side of the drawing. This is not a very practical dynamo design (unless one seeks to generate huge currents at very low voltages), but in the large-scale universe, most currents are apparently produced by motions of this sort.
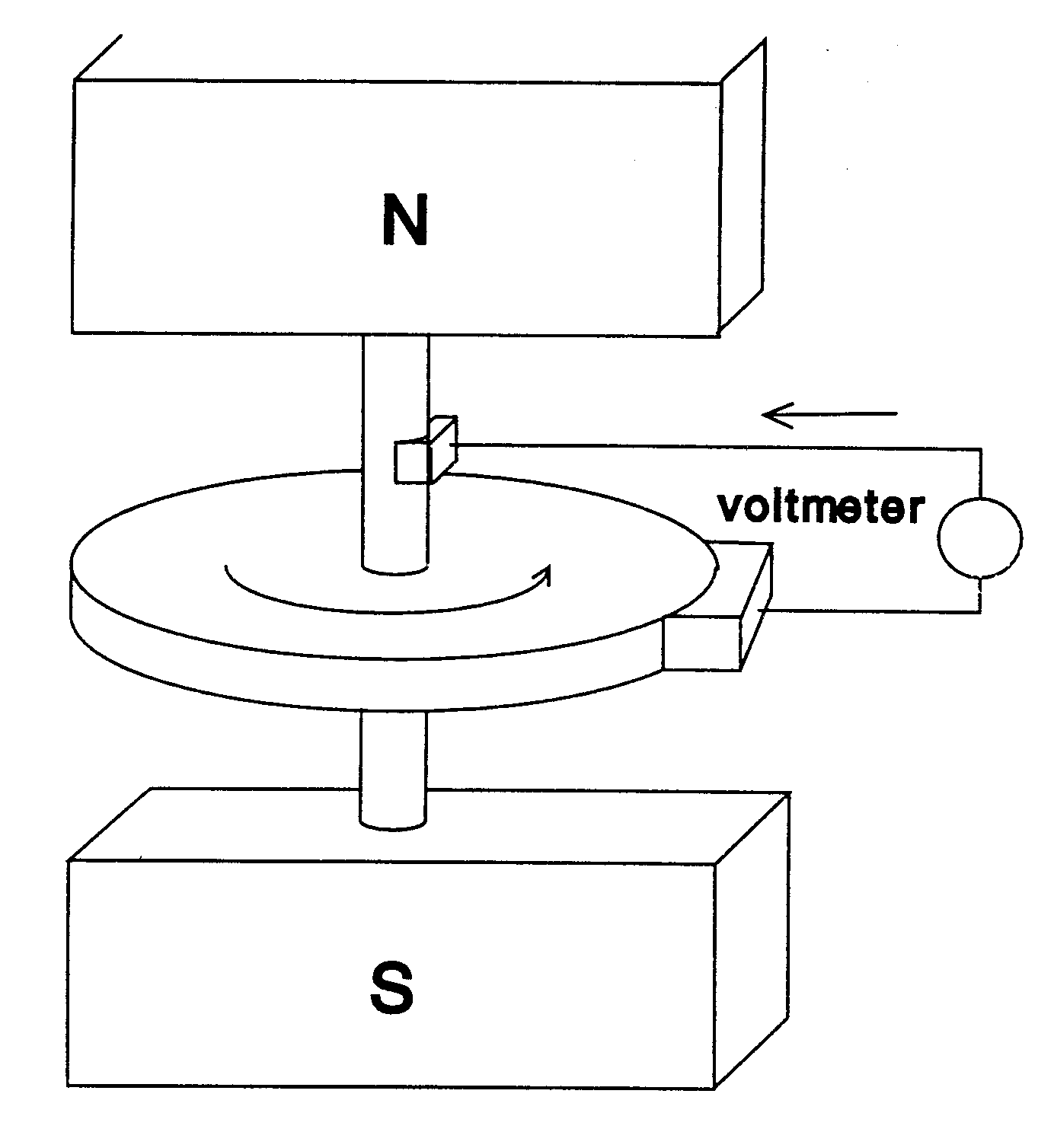
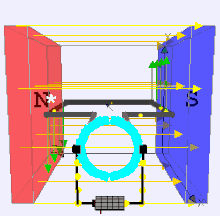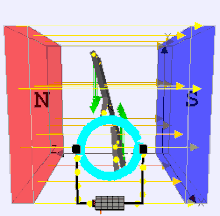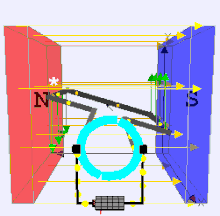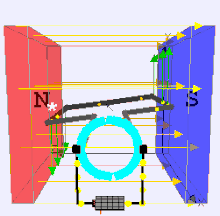
The Disk Dynamo
| disk dynamo needs a magnetic field in order to produce an electric current. Is it possible for the current which it generated to also produce the magnetic field which the dynamo process required? |
| At first sight this looks like a "chicken and egg" propostion: to produce a chicken, you need an egg, but to produce an egg you need a chicken--so which of these came first? Similarly here--to produce a current, you need a magnetic field, but to produce a magnetic field you need a current. Where does one begin? Actually, weak magnetic fields are always present and would be gradually amplified by the process, so this poses no obstacle. |
| When the shaft of a dynamo is turned by some outside force, its electrical connections can produce an electric current. Many dynamos however are reversible: if an electric current is fed into its electrical connection, the force on the current can turn the same shaft, converting the dynamo into a motor. In some models of "hybrid" automobiles, electric motors fed by a storage battery help the gasoline engine accelerate the car, but then when the car slows down, they become dynamos and feed an electric current back into the battery, saving energy which otherwise might turn into waste heat in brakes. |
| The rotating disk here is a shallow layer of water containing copper sulfate, which conducts electricity. The solution in put in a Petri dish and placed on top of one of the poles of a vertical laboratory electromagnet; little pieces of cork floating on the fluid then trace its rotation The electrodes are two circles of copper (they can be sawed from the ends of pipes)--a big one on the outer boundary of the solution and a small one in the middle. When the terminals of a battery of an electric power supply are connected to the two copper circles, the fluid starts rotating. Reverse the contacts and the rotation reverses too. |
The word dynamo (from the Greek word dynamis (δύναμις), meaning force or power) was originally another name for an electrical generator, and still has some regional usage as a replacement for the word generator. The word "dynamo" was coined in 1831 by Michael Faraday, who utilized his invention toward making many discoveries in electricity (Faraday discovered electrical induction) and magnetism.
The original "dynamo principle" of Wehrner von Siemens or Werner von Siemens referred only the direct current generators which use exclusively the self-excitation (self-induction) principle to generate DC power. The earlier DC generators which used permanent magnets were not considered "dynamo electric machines". The invention of the dynamo principle (self-induction) was a huge technological leap over the old traditional permanent magnet based DC generators. The discovery of the dynamo principle made industrial scale electric power generation technically and economically feasible. After the invention of the alternator and that alternating current can be used as a power supply, the word dynamo became associated exclusively with the commutated direct current electric generator, while an AC electrical generator using either slip rings or rotor magnets would become known as an alternator.
A small electrical generator built into the hub of a bicycle wheel to power lights is called a hub dynamo, although these are invariably AC devices, and are actually magnetos.
The electric dynamo uses rotating coils of wire and magnetic fields to convert mechanical rotation into a pulsing direct electric current through Faraday's law of induction. A dynamo machine consists of a stationary structure, called the stator, which provides a constant magnetic field, and a set of rotating windings called the armature which turn within that field. Due to Faraday's law of induction the motion of the wire within the magnetic field creates an electromotive force which pushes on the electrons in the metal, creating an electric current in the wire. On small machines the constant magnetic field may be provided by one or more permanent magnets; larger machines have the constant magnetic field provided by one or more electromagnets, which are usually called field coils.
Commutation
The commutator is needed to produce direct current. When a loop of wire rotates in a magnetic field, the magnetic flux through it, and thus the potential induced in it, reverses with each half turn, generating an alternating current. However, in the early days of electric experimentation, alternating current generally had no known use. The few uses for electricity, such as electroplating, used direct current provided by messy liquid batteries. Dynamos were invented as a replacement for batteries. The commutator is essentially a rotary switch. It consists of a set of contacts mounted on the machine's shaft, combined with graphite-block stationary contacts, called "brushes", because the earliest such fixed contacts were metal brushes. The commutator reverses the connection of the windings to the external circuit when the potential reverses, so instead of alternating current, a pulsing direct current is produced.
Excitation
The earliest dynamos used permanent magnets to create the magnetic field. These were referred to as "magneto-electric machines" or magnetos.[4] However, researchers found that stronger magnetic fields, and so more power, could be produced by using electromagnets (field coils) on the stator.[5] These were called "dynamo-electric machines" or dynamos.[4] The field coils of the stator were originally separately excited by a separate, smaller, dynamo or magneto. An important development by Wilde and Siemens was the discovery (by 1866) that a dynamo could also bootstrap itself to be self-excited, using current generated by the dynamo itself. This allowed the growth of a much more powerful field, thus far greater output power.
Self-excited direct current dynamos commonly have a combination of series and parallel (shunt) field windings which are directly supplied power by the rotor through the commutator in a regenerative manner. They are started and operated in a manner similar to modern portable alternating current electric generators, which are not used with other generators on an electric grid.
There is a weak residual magnetic field that persists in the metal frame of the device when it is not operating, which has been imprinted onto the metal by the field windings. The dynamo begins rotating while not connected to an external load. The residual magnetic field induces a very small electrical current into the rotor windings as they begin to rotate. Without an external load attached, this small current is then fully supplied to the field windings, which in combination with the residual field, cause the rotor to produce more current. In this manner the self-exciting dynamo builds up its internal magnetic fields until it reaches its normal operating voltage. When it is able to produce sufficient current to sustain both its internal fields and an external load, it is ready to be used.
A self-excited dynamo with insufficient residual magnetic field in the metal frame will not be able to produce any current in the rotor, regardless of what speed the rotor spins. This situation can also occur in modern self-excited portable generators, and is resolved for both types of generators in a similar manner, by applying a brief direct current battery charge to the output terminals of the stopped generator. The battery energizes the windings just enough to imprint the residual field, to enable building up the current. This is referred to as flashing the field.
Both types of self-excited generator, which have been attached to a large external load while it was stationary, will not be able to build up voltage even if the residual field is present. The load acts as an energy sink and continuously drains away the small rotor current produced by the residual field, preventing magnetic field buildup in the field coil.
Induction with permanent magnets

The operating principle of electromagnetic generators was discovered in the years 1831–1832 by Michael Faraday. The principle, later called Faraday's law, is that an electromotive force is generated in an electrical conductor which encircles a varying magnetic flux.
He also built the first electromagnetic generator, called the Faraday disk, a type of homopolar generator, using a copper disc rotating between the poles of a horseshoe magnet. It produced a small DC voltage. This was not a dynamo in the current sense, because it did not use a commutator.
This design was inefficient, due to self-cancelling counterflows of current in regions of the disk that were not under the influence of the magnetic field. While current was induced directly underneath the magnet, the current would circulate backwards in regions that were outside the influence of the magnetic field. This counterflow limited the power output to the pickup wires, and induced waste heating of the copper disc. Later homopolar generators would solve this problem by using an array of magnets arranged around the disc perimeter to maintain a steady field effect in one current-flow direction.
Another disadvantage was that the output voltage was very low, due to the single current path through the magnetic flux. Faraday and others found that higher, more useful voltages could be produced by winding multiple turns of wire into a coil. Wire windings can conveniently produce any voltage desired by changing the number of turns, so they have been a feature of all subsequent generator designs, requiring the invention of the commutator to produce direct current.
The first dynamos

The first dynamo based on Faraday's principles was built in 1832 by Hippolyte Pixii, a French instrument maker. It used a permanent magnet which was rotated by a crank. The spinning magnet was positioned so that its north and south poles passed by a piece of iron wrapped with insulated wire.
Pixii found that the spinning magnet produced a pulse of current in the wire each time a pole passed the coil. However, the north and south poles of the magnet induced currents in opposite directions. To convert the alternating current to DC, Pixii invented a commutator, a split metal cylinder on the shaft, with two springy metal contacts that pressed against it.

This early design had a problem: the electric current it produced consisted of a series of "spikes" or pulses of current separated by none at all, resulting in a low average power output. As with electric motors of the period, the designers did not fully realize the seriously detrimental effects of large air gaps in the magnetic circuit.
Antonio Pacinotti, an Italian physics professor, solved this problem around 1860 by replacing the spinning two-pole axial coil with a multi-pole toroidal one, which he created by wrapping an iron ring with a continuous winding, connected to the commutator at many equally spaced points around the ring; the commutator being divided into many segments. This meant that some part of the coil was continually passing by the magnets, smoothing out the current.
The Woolrich Electrical Generator of 1844, now in Thinktank, Birmingham Science Museum, is the earliest electrical generator used in an industrial process. It was used by the firm of Elkingtons for commercial electroplating.
.jpg)
Dynamo self excitation
Independently of Faraday, the Hungarian Anyos Jedlik started experimenting in 1827 with the electromagnetic rotating devices which he called electromagnetic self-rotors. In the prototype of the single-pole electric starter, both the stationary and the revolving parts were electromagnetic.
About 1856 he formulated the concept of the dynamo about six years before Siemens and Wheatstone but did not patent it as he thought he was not the first to realize this. His dynamo used, instead of permanent magnets, two electromagnets placed opposite to each other to induce the magnetic field around the rotor. It was also the discovery of the principle of dynamo self-excitation,[13] which replaced permanent magnet designs.
Practical designs

The dynamo was the first electrical generator capable of delivering power for industry. The modern dynamo, fit for use in industrial applications, was invented independently by Sir Charles Wheatstone, Werner von Siemens and Samuel Alfred Varley. Varley took out a patent on 24 December 1866, while Siemens and Wheatstone both announced their discoveries on 17 January 1867, the latter delivering a paper on his discovery to the Royal Society.
The "dynamo-electric machine" employed self-powering electromagnetic field coils rather than permanent magnets to create the stator field.[14] Wheatstone's design was similar to Siemens', with the difference that in the Siemens design the stator electromagnets were in series with the rotor, but in Wheatstone's design they were in parallel. The use of electromagnets rather than permanent magnets greatly increased the power output of a dynamo and enabled high power generation for the first time. This invention led directly to the first major industrial uses of electricity. For example, in the 1870s Siemens used electromagnetic dynamos to power electric arc furnaces for the production of metals and other materials.
The dynamo machine that was developed consisted of a stationary structure, which provides the magnetic field, and a set of rotating windings which turn within that field. On larger machines the constant magnetic field is provided by one or more electromagnets, which are usually called field coils.

Zénobe Gramme reinvented Pacinotti's design in 1871 when designing the first commercial power plants operated in Paris. An advantage of Gramme's design was a better path for the magnetic flux, by filling the space occupied by the magnetic field with heavy iron cores and minimizing the air gaps between the stationary and rotating parts. The Gramme dynamo was one of the first machines to generate commercial quantities of power for industry.[16] Further improvements were made on the Gramme ring, but the basic concept of a spinning endless loop of wire remains at the heart of all modern dynamos.[17]
Charles F. Brush assembled his first dynamo in the summer of 1876 using a horse-drawn treadmill to power it. Brush's design modified the Gramme dynamo by shaping the ring armature like a disc rather than a cylinder shape. The field electromagnets were also positioned on the sides of the armature disc rather than around the circumference.
Rotary converters
After dynamos and motors were found to allow easy conversion back and forth between mechanical or electrical power, they were combined in devices called rotary converters, rotating machines whose purpose was not to provide mechanical power to loads but to convert one type of electric current into another, for example DC into AC. They were multi-field single-rotor devices with two or more sets of rotating contacts (either commutators or sliprings, as required), one to provide power to one set of armature windings to turn the device, and one or more attached to other windings to produce the output current.
The rotary converter can directly convert, internally, any type of electric power into any other. This includes converting between direct current (DC) and alternating current (AC), three phase and single phase power, 25 Hz AC and 60 Hz AC, or many different output voltages at the same time. The size and mass of the rotor was made large so that the rotor would act as a flywheel to help smooth out any sudden surges or dropouts in the applied power.
The technology of rotary converters was replaced in the early 20th century by mercury-vapor rectifiers, which were smaller, did not produce vibration and noise, and required less maintenance. The same conversion tasks are now performed by solid state power semiconductor devices. Rotary converters remained in use in the West Side IRT subway in Manhattan into the late 1960s, and possibly some years later. They were powered by 25 Hz AC, and provided DC at 600 volts for the trains.
uses
Electric power generation
Dynamos, usually driven by steam engines, were widely used in power stations to generate electricity for industrial and domestic purposes. They have since been replaced by alternators.
Large industrial dynamos with series and parallel (shunt) windings can be difficult to use together in a power plant, unless either the rotor or field wiring or the mechanical drive systems are coupled together in certain special combinations. It seems theoretically possible to run dynamos in parallel to create induction and self sustaining system for electrical power.
Transport
Dynamos were used in motor vehicles to generate electricity for battery charging. An early type was the third-brush dynamo. They have, again, been replaced by alternators.
Modern uses
Dynamos still have some uses in low power applications, particularly where low voltage DC is required, since an alternator with a semiconductor rectifier can be inefficient in these applications.
Hand cranked dynamos are used in clockwork radios, hand powered flashlights, mobile phone chargers, and other human powered equipment to recharge batteries.
A bottle dynamo or sidewall dynamo is a small electrical generator for bicycles employed to power a bicycle's lights. The traditional bottle dynamo (pictured) is not actually a dynamo, which creates DC power, but a low-power magneto that generates AC. Newer models can include a rectifier to create DC output to charge batteries for electronic devices including cellphones or GPS receivers
Named after their resemblance to bottles, these generators are also called sidewall dynamos because they operate using a roller placed on the sidewall of a bicycle tire. When the bicycle is in motion and the dynamo roller is engaged, electricity is generated as the tire spins the roller.
Two other dynamo systems used on bicycles are hub dynamos and bottom bracket dynamos.

Advantages over hub dynamos
- No extra resistance when disengaged
- When engaged, a dynamo requires the bicycle rider to exert more effort to maintain a given speed than would otherwise be necessary when the dynamo is not present or disengaged. Bottle dynamos can be completely disengaged when they are not in use, whereas a hub dynamo will always have added drag (though it may be so low as to be irrelevant or unnoticeable to the rider, and it is reduced significantly when lights are not being powered by the hub).
- Easy retrofitting
- A bottle dynamo may be more feasible than a hub dynamo to add to an existing bicycle, as it does not require a replacement or rebuilt wheel.
- Price
- A bottle dynamo is generally cheaper than a hub dynamo, but not always.
Disadvantages over hub dynamos
- Slippage
- In wet conditions, the roller on a bottle dynamo can slip against the surface of a tire, which interrupts or reduces the amount of electricity generated. This can cause the lights to go out completely or intermittently. Hub dynamos do not need traction and are sealed from the elements.
- Increased resistance
- Bottle dynamos typically create more drag than hub dynamos. However, when they are properly adjusted, the drag may be so low as to be trivial, and there is no resistance when the bottle dynamo is disengaged.
- Tire wear
- Because bottle dynamos rub against the sidewall of a tire to generate electricity, they cause added wear on the side of tire. Hub dynamos do not.
- Noise
- Bottle dynamos make an easily audible mechanical humming or whirring sound when engaged. Hub dynamos are silent.
- Switching
- Bottle dynamos must be physically repositioned to engage them, to turn on the lamps. Hub dynamos are switched on electronically. Hub dynamos can be engaged automatically by using electronic ambient light detection, providing zero-effort activation.
- Positioning
- Bottle dynamos must be carefully adjusted to touch the sidewall at correct angles, height and pressure. Bottle dynamos can be knocked out of position if the bike falls, or if the mounting screws are too loose. A badly positioned bottle dynamo will make more noise and drag, slip more easily, and can in worst case fall into the spokes. Some dynamo mounts have tabs to try to prevent the latter.

Technological Evolution of the ICT Sector
Segment Routing
Segment routing is a technology that is gaining popularity as a way to simplify MPLS networks. It has the benefits of interfacing with software-defined networks and allows for source-based routing. It does this without keeping state in the core of the network. It's one of the topics I'm learning more about at Cisco Live U.S. this week.
Multi Protocol Label Switching (MPLS) is the main forwarding paradigm in all the major service providers (SP) networks. MPLS, as the name implies, uses labels to forward the packets, thus providing the major advantage of a Border Gateway Protocol (BGP)-free core. To assign these labels, the most commonly used protocol is the Label Distribution Protocol (LDP). A typical provider network can then look like the diagram below.
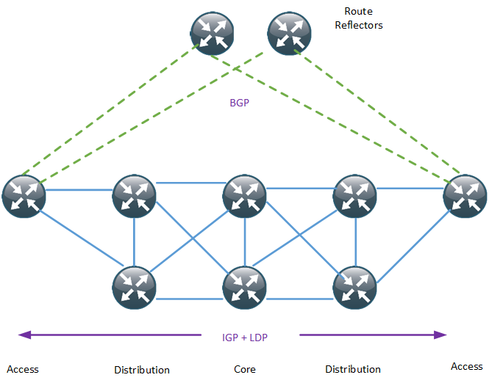
In order to provide stability and scalability, large networks should have as few protocols as possible running in the core, and they should keep state away from the core if possible. That brings up some of the drawbacks of LDP:
- It uses an additional protocol running on all devices just to generate labels
- It introduces the potential for blackholing of traffic, because Interior Gateway Protocol (IGP) and LDP are not synchronized
- It does not employ global label space, meaning that adjacent routers may use a different label to reach the same router
- It's difficult to visualize the Label Switched Path (LSP) because of the issue above
- It may take time to recover after link failure unless session protection is utilized
Segment routing is a new forwarding paradigm that provides source routing, which means that the source can define the path that the packet will take. SR still uses MPLS to forward the packets, but the labels are carried by an IGP. In SR, every node has a unique identifier called the node SID. This identifier is globally unique and would normally be based on a loopback on the device. Adjacency SIDs can also exist for locally significant labels for a segment between two devices.
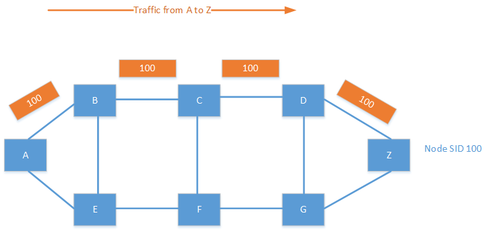
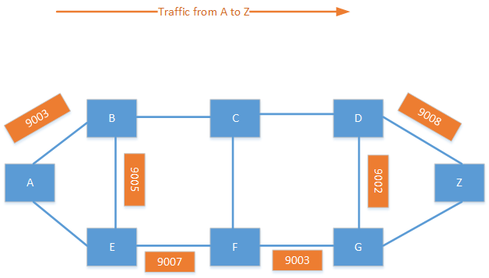
It is also possible to combine the node SID and adjacency SID to create a custom traffic policy. Labels are specified in a label stack, which may include several labels. By combining labels, you can create policies such as, "Send the traffic to F; I don't care how you get there. From F, go to G, then to D and then finally to Z." This creates endless possibilities for traffic engineering in the provider network.
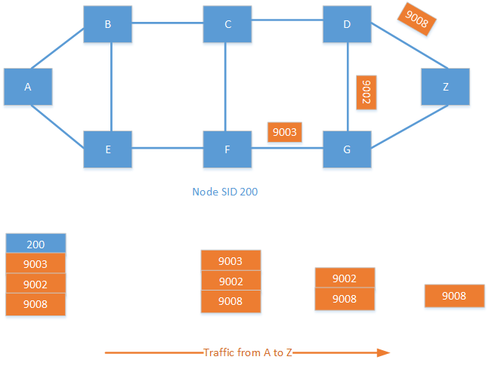
Now we have a basic understanding of how SR works. What are the different use cases for SR? How do we expect to see it being used?
One of the main applications for SR is to enable some kind of application controller that can steer traffic over different paths, depending on different requirements and the current state of the network. Some might relate to this as software-defined networking (SDN). It is then possible to program the network to send voice over a lower latency path and send bulk data over a higher latency path. Doing this today requires MPLS-TE, as well as keeping state in many devices. With SR, there is no need to keep state in intermediary devices.
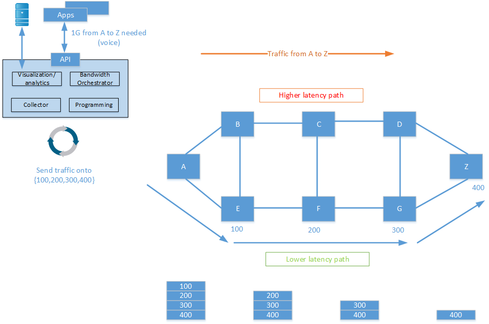
SR can also help protect against distributed denial of service (DDoS) attacks. When an attack is detected, traffic can be redirected to a scrubbing device which cleans the traffic and injects it into the network again.
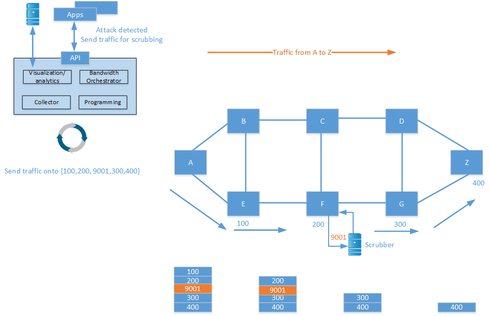
SR has a great deal of potential, and may cause the decline or even disappearance of protocols such as LDP and RSVP-TE. SR is one piece of the puzzle to start implementing SDN in provider networks.
XO__XO ++DW Virtual Dynamo
Virtual Dynamo: The Next Generation Of Virtual Distributed Storage
Scalability Issues With Relational Databases
Before discussing Dynamo it is worth taking look back to understand its origins. One of the most powerful
and useful technologies that has been powering the web since its early days is the relational database.
Particularly, relational databases have been used a lot for retail sites where visitors are able to browse and search for products.
Modern relational database are able to handle millions of products and service very large sites.
and useful technologies that has been powering the web since its early days is the relational database.
Particularly, relational databases have been used a lot for retail sites where visitors are able to browse and search for products.
Modern relational database are able to handle millions of products and service very large sites.
However, it is difficult to create redundancy and parallelism with relational databases, so
they become a single point of failure. In particular, replication is not trivial. To understand why, consider
the problem of having two database servers that need to have identical data. Having both servers for reading and writing
data makes it difficult to synchronize changes. Having one master server and another slave is bad too, because the master has to
take all the heat when users are writing information.
they become a single point of failure. In particular, replication is not trivial. To understand why, consider
the problem of having two database servers that need to have identical data. Having both servers for reading and writing
data makes it difficult to synchronize changes. Having one master server and another slave is bad too, because the master has to
take all the heat when users are writing information.
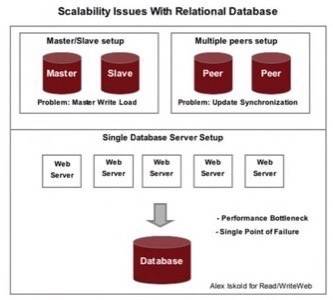
So as a relational database grows, it becomes a bottle neck and the point of failure for the entire system.
As mega e-commerce sites grew over the past decade they became aware of this issue – adding more web servers does not help because it is the database
that ends up being a problem.
As mega e-commerce sites grew over the past decade they became aware of this issue – adding more web servers does not help because it is the database
that ends up being a problem.
Dynamo – A Distributed Storage System
Unlike a relational database, Dynamo is a distributed storage system. Like a relational database it is stores information
to be retrieved, but it does not break the data into tables. Instead all objects are stored and looked up via a key.
A simple way to think about such a system is in terms of URLs. When you navigate to the page on Amazon for the last
Harry Potter book, http://www.amazon.com/gp/product/0545010225 you see a page that includes a
description of the book, customer reviews, related books, and so on. To create this page, Amazon’s infrastructure
has to perform many database lookups, the most basic of which is to grab information about the book from its URL
(or, more likely, from its ASIN – a unique code for each Amazon product, 0545010225 in this case).
to be retrieved, but it does not break the data into tables. Instead all objects are stored and looked up via a key.
A simple way to think about such a system is in terms of URLs. When you navigate to the page on Amazon for the last
Harry Potter book, http://www.amazon.com/gp/product/0545010225 you see a page that includes a
description of the book, customer reviews, related books, and so on. To create this page, Amazon’s infrastructure
has to perform many database lookups, the most basic of which is to grab information about the book from its URL
(or, more likely, from its ASIN – a unique code for each Amazon product, 0545010225 in this case).
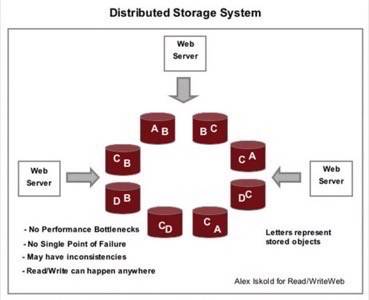
In the figure above we show a concept schematic for how a distributed storage system works.
The information is distributed around a ring of computers, each computer is identical. To ensure fault tolerance, in case
a particular node breaks down, the data is made redundant, so each object is stored in the system multiple times.
The information is distributed around a ring of computers, each computer is identical. To ensure fault tolerance, in case
a particular node breaks down, the data is made redundant, so each object is stored in the system multiple times.
In technical terms, Dynamo is called an eventually consistent storage system. The terminology
may seem a bit odd, but as it turns out creating a distributed storage solution which is both responsive
and consistent is a difficult problem. As you can tell from the diagram above, if one computer updates object A,
these changes need to propagate to other machines. This is done using asynchronous communication, which is why
the system is called “eventually consistent.”
may seem a bit odd, but as it turns out creating a distributed storage solution which is both responsive
and consistent is a difficult problem. As you can tell from the diagram above, if one computer updates object A,
these changes need to propagate to other machines. This is done using asynchronous communication, which is why
the system is called “eventually consistent.”
The example Amazon .Dynamo :
How Dynamo Works
The technical details in Vogels’ paper are quite complex, but the way in which Dynamo works can be understood more simply.
First, like Amazon S3, Dynamo offers a simple put and get interface. Each put
requires the key, context and the object. The context is based on the object and is used by Dynamo
for validating updates. Here is the high level description of Dynamo and a put request:
First, like Amazon S3, Dynamo offers a simple put and get interface. Each put
requires the key, context and the object. The context is based on the object and is used by Dynamo
for validating updates. Here is the high level description of Dynamo and a put request:
- Physical nodes are thought of as identical and organized into a ring.
- Virtual nodes are created by the system and mapped onto physical nodes, so that hardware
can be swapped for maintenance and failure. - The partitioning algorithm is one of the most complicated pieces of the system, it specifies which nodes will store
a given object. - The partitioning mechanism automatically scales as nodes enter and leave the system.
- Every object is asynchronously replicated to N nodes.
- The updates to the system occur asynchronously and may result in multiple copies of the object in the system with slightly
different states. - The discrepancies in the system are reconciled after a period of time, ensuring eventual consistency.
- Any node in the system can be issued a put or get request for any key.
So Dynamo is quite complex, but is also conceptually simple. It is inspired by the way things work in nature – based on
self-organization and emergence. Each node is identical to other nodes, the nodes can come in and out of existence, and the data is automatically
balanced around the ring – all of this makes Dynamo similar to an ant colony or beehive.
self-organization and emergence. Each node is identical to other nodes, the nodes can come in and out of existence, and the data is automatically
balanced around the ring – all of this makes Dynamo similar to an ant colony or beehive.
Finally, Dynamo’s internals are implemented in Java. The choice is likely because, as we’ve written here,
Java is an elegant programming language, which allows the appropriate level of object-orineted modeling. And yes, once again, it is fast enough!
Java is an elegant programming language, which allows the appropriate level of object-orineted modeling. And yes, once again, it is fast enough!
Dynamo – The SLA In A Box
Perhaps the most stunning revelation about Dynamo is that it can be tuned using just a handful parameters to achieve
different, technical goals that in turn support different business requirements. Dynamo is a storage service in the box driven by an SLA.
Different applications at Amazon use different configurations of Dynamo depending on their tolerence to delays or data discrepancy.
The paper lists these main uses of Dynamo:
different, technical goals that in turn support different business requirements. Dynamo is a storage service in the box driven by an SLA.
Different applications at Amazon use different configurations of Dynamo depending on their tolerence to delays or data discrepancy.
The paper lists these main uses of Dynamo:
Business logic specific reconciliation: This is a popular use case for Dynamo. Each data object is replicated across multiple nodes. The shopping cart service is a prime example of this category.
Timestamp based reconciliation: This case differs from the previous one only in the reconciliation mechanism. The service that maintains customers’ session information is a good example of a service that uses this mode.
High performance read engine: While Dynamo is built to be an “always writeable” data store, a few services are tuning its quorum characteristics and using it as a high performance read engine. Services that maintain a product catalog and promotional items fit in this category.
Timestamp based reconciliation: This case differs from the previous one only in the reconciliation mechanism. The service that maintains customers’ session information is a good example of a service that uses this mode.
High performance read engine: While Dynamo is built to be an “always writeable” data store, a few services are tuning its quorum characteristics and using it as a high performance read engine. Services that maintain a product catalog and promotional items fit in this category.
Dynamo shows once again how disciplined and rare Amazon is at using and re-using its infrastructure. The technical management
must have realized early on that the very survival of the business depended on common, bullet proof, flexible, and scalable software systems.
Amazon succeeded in both implementing and spreading the infrastructure through the company. It truly earned the mandate to then
leverage its internal pieces and offer them as web services.
must have realized early on that the very survival of the business depended on common, bullet proof, flexible, and scalable software systems.
Amazon succeeded in both implementing and spreading the infrastructure through the company. It truly earned the mandate to then
leverage its internal pieces and offer them as web services.
How Does Dynamo Fit With AWS?
The short answer is that it does not, because it is not a public service. The short answer is also shortsighted because
there are clear implications. First, is that since Amazon is committed to building a stack of web services, a version of Dynamo
is likely to be available to the public at some time in the future.
there are clear implications. First, is that since Amazon is committed to building a stack of web services, a version of Dynamo
is likely to be available to the public at some time in the future.
Second, Amazon is restless in its innovation; and that applies to web services as well as it applies to its retail business. S3 has already made possible a whole new generation
of startups and web services and Dynamo is likely to do the same when it comes out. And we know that more is likely to come, as even with
Dynamo, the stack of web services is far from complete.
of startups and web services and Dynamo is likely to do the same when it comes out. And we know that more is likely to come, as even with
Dynamo, the stack of web services is far from complete.
Finally, Amazon is showing openness – a highly valuable characteristic. Surely, Google and Microsoft
have similar systems, but Amazon is putting them out in the open and turning its infrastructure into a business faster
than its competitors. It is this openness that will allow Amazon to build trust and community around their Web Services stack. It is a powerful force, which is likely to win over developers and business people as well.
have similar systems, but Amazon is putting them out in the open and turning its infrastructure into a business faster
than its competitors. It is this openness that will allow Amazon to build trust and community around their Web Services stack. It is a powerful force, which is likely to win over developers and business people as well.
The Future – Amazon Web OS
To any computer scientist or software engineer to watch what Amazon is doing is both awesome and humbling.
Taking complex theoretical concepts and algorithms, adopting them to business environments (down to the SLA!), proving
that they work at the world’s largest retail site, and then turning around and making them available to the rest of the world
is nothing short of a tour-de-force. What Emre Sokullu called HaaS (Hardware as a Service) in his post
yesterday is not only an innovative business strategy, but also a triumph of software engineering.
Taking complex theoretical concepts and algorithms, adopting them to business environments (down to the SLA!), proving
that they work at the world’s largest retail site, and then turning around and making them available to the rest of the world
is nothing short of a tour-de-force. What Emre Sokullu called HaaS (Hardware as a Service) in his post
yesterday is not only an innovative business strategy, but also a triumph of software engineering.
Amazon is on track to roll out more virtual web services, which will collectively amount to a web operating system.
The building blocks that are already in place and the ones to come are going to be remixed to create new web applications
that were simply not possible before. As we have written here recently, it is the libraries that make it possible to create giant systems
with just a handful of engineers. Amazon’s Web Services are going to make web-scale computing available to anyone. This is
unimaginably powerful. This future is almost here, so we can begin thinking about it today. What kinds of things do you want to build
with existing and coming Amazon Web Services?
The building blocks that are already in place and the ones to come are going to be remixed to create new web applications
that were simply not possible before. As we have written here recently, it is the libraries that make it possible to create giant systems
with just a handful of engineers. Amazon’s Web Services are going to make web-scale computing available to anyone. This is
unimaginably powerful. This future is almost here, so we can begin thinking about it today. What kinds of things do you want to build
with existing and coming Amazon Web Services?

The Energy Cloud
We are in the midst of a technology-driven shift in how electricity is generated and managed. Today’s one-way grid, built around generation from large-scale power plants, is gradually being transformed into a multi-directional network that relies far more on small-scale, distributed generation. It’s what a recent piece in Public Utilities Fortnightly dubbed the Energy Cloud.
That’s a very appropriate way to think about this grid of the future, because it will parallel the technology “cloud” in important ways.
The technology cloud distributes computing power and data storage around a network so they are easily accessible. Users can draw on the services they need, when they need them – Software as a Service or SaaS – and the network automatically manages resources to provide the bandwidth and performance required for their tasks. Users pay for the value of the resources they actually use, giving them greater visibility and control over costs. They also get incredible freedom to choose – rather than being locked into one vendor, they can always switch whatever app or service best suits them at a given time.
The Energy Cloud represents the same kind of structure for electricity, and will offer not only electric power, but also intelligent management of power consumption and other value-added services to consumers on demand. This service-based approach will be driven by the sharp growth of distributed energy and storage systems based on renewables like solar, and that allow consumers to both obtain power from the grid as well as provide power out to it.
As the Energy Cloud matures, both consumers and businesses will be able to draw on these renewable power sources as needed, at a price based on the value of all the resources involved in providing them that power. Like the IT cloud, the Energy Cloud gives consumers freedom of choice for where they get power at any given time – they aren’t locked into any one provider. It also lets utilities easily meet this consumer demand, by employing sophisticated control software to manage choice, performance and bandwidth (in other words, energy sources, demand management and reliability).
In fact, in both the technology cloud and the Energy Cloud, management of the network is what creates the greatest value.
It requires sophisticated technology and network operations expertise to ensure a technology network collects, processes, formats and delivers data across the network to meet highly dynamic demand. The same degree of sophistication and expertise will be needed to manage the complexities of the Energy Cloud so it will perform predictably, reliably, efficiently and safely. Because the existing grid structure was designed as a one-way system, the dynamics of two-way distributed generation and storage can create issues of reliability or even safety if flows are not carefully managed.
What isn’t as clear is who will take on this crucial role in the Energy Cloud. If you look at what happened when IT shifted to the cloud, you’ll discover that it also shifted the relationships among the various participants – some established players saw their roles diminish, while major aspects of the network are handled by entirely new entities. Expect similar changes when it comes to the Energy Cloud, as utilities, DER equipment providers, “intelligent home” companies and other technology companies all vie for position.
What’s most likely to happen, particularly given the regulation in the energy industry that’s absent in the IT industry, is that network operations will be managed by a partnership among all those entities. Incumbent utilities will have a crucial role – provided they recognize the coming changes and move rapidly (if not, they risk being relegated to just owning the wires, a commodity play).
These partnerships also will rely on control technology and software from new companies that bring that expertise to the table. The Energy Cloud needs standards around controls and management technology so that different devices and equipment can co-exist seamlessly across the entire network.
At Sunverge we see this leading to the “Platform as a Service” – PaaS – where all the participants can make use of the aspects of the central control platform as needed. Along with that, we also see the emergence of CaaS – Capacity as a Service – that uses the Platform to create Virtual Power Plants that will be a key source of capacity and reliability.
This standard platform has been a core part of our work from the beginning. As part of our Solar Integration System (SIS), the platform has been constantly advanced over the past five years as we have learned from having it “in the field” how to make it even more robust and flexible. To make it a standard, we have built the platform with open APIs so other Energy Cloud participants can take advantage of the control function and the rich data generated by the platform and develop value-added services on top of it.
Thanks to the technology core of PaaS and CaaS, and with these new partnerships, utilities will be able to expand new customer services more rapidly than ever before — and conceive new revenue models never thought possible. This will be as disruptive as Uber, AirBnB and other new companies that are using technology to transform traditional industry sectors.
We expect there to be a lot of interesting developments in the coming year in this Energy Cloud transition, and for this realignment of participants to begin in earnest. While we can’t know today exactly how this will look in a few years, we can be certain that even 12 months from now the change will be visible and accelerating.
COMPUTEROME CLOUD TODAY:
Accessible from anywhere through proper mechanisms
Secure private clusters
Virtual clusters
Cloud bursting capabilities
Security, isolation and access control in compliance with statutory acts
Accessible from anywhere through proper mechanisms
Secure private clusters
Virtual clusters
Cloud bursting capabilities
Security, isolation and access control in compliance with statutory acts
Dynamic Network Analysis via Motifs (DYNAMO)
For develop a graph mining-based approach and framework that will allow humans to discover and detect important or critical graph patterns in data streams through the analysis of local patterns of interactions and behaviors of actors, entities, and/or features. Conceptually, this equates to identifying small local subgraphs in a massive virtual dynamic network (generated from data streams) that have specific meaning and relevance to the user and that are indicators of a particular activity or event. We refer to these local graph patterns, which are small directed attributed subgraphs, as network motifs. Detecting motifs in streaming data amounts to more than looking for the occurrence of specific entities or features in particular states, but also their relationships, interactions, and collaborative behaviors.
Approach
In the detection of insider cyber threats, one may characterize the type of an insider agent, computer user, or organizational role by examining the modes and frequencies of its local interactions or network motifs within the cloud. For example, a cloud interaction graph may be generated from cloud telemetry data that shows a user’s particular interactions with or access to specific tenants, data stores, and applications. In examining such a graph, one can look closely for small local graph patterns or network motifs that are indicative of an insider cyber threat. Additional motif analysis of prox card access data may identify changes in an actor’s work patterns (time and place) and the people she interacts with. Motif analysis of email and phone communications records could identify an actor’s interactions with other people and their associated statuses and roles.
Each of the network motifs is an individual indicator of insider agent behavior. We might expect dozens to hundreds of potential indicators that are drawn from subject-matter-experts or learned from activity monitoring data. From these potential indicators, we may derive a sufficient and optimal set of indicators to apply to insider threat detection. The set of influential network motifs may be organized and monitored through a motif census, which is a scalar vector of the counts of each motif pattern in the cloud interaction graph. The motif census may be considered as a signature of network interaction patterns for a particular person, class of users, or type of insider agent.
For the electron microscopy use case, image features may be detected in an electron microscope image much like facial features are detected from a picture for facial recognition. The image features may be linked together to form a feature map that is analogous to a facial recognition map. Motif analysis may then be applied to the dynamic feature map to identify the occurrence of substructures that are indicative of a particular event or chemical behavior.
The concepts of the network motif and the motif census have some very compelling characteristics for threat, event, or feature detection. They provide a simple and intuitive representation for users to encode critical patterns. They provide a structure for assessing multiple indicators. They enable a mechanism for throttling the accuracy of findings and limiting false positives by adjusting the threshold associated with the computed similarity distance measure (e.g., lower threshold = higher accuracy and less false positives). Indicators in a motif census may be active or inactive depending on whether data is available to assess the indicator. In the case where active indicators may be alerting a potential insider or image feature or event, the inactive indicators identify additional data to gather and assess to further confirm or reject the alert. This enables an approach for directing humans or systems to specific areas to look for additional information or data.
Benefit
Dynamic network motif analysis represents a graph-theoretic approach to conduct “pattern-of-life” analysis of agents or entities. The analytical approach should allow an analyst or scientist to:
- Expose relationships and interactions of an agent with other various articles or entities such as other people, computing resources, places or locations, and subject areas
- Learn normal relationship and interaction patterns of different classes of agents from monitored activities
- Detect when anomalous patterns occur and offer potential explanations
- Facilitate encoding of hypothetical behavioral patterns or indicators for an agent to use in future detection (e.g., off-hour access to computing resources, unusual access patterns, accumulation of large amounts of data)
- Provide framework for evaluating and confirming multiple indicators
- Analyze temporal evolution of interactions and behaviors of an agent
- Support all the above analytics in the presence of streaming data
All Things Distributed

The AWS GovCloud (US-East) Region is our second AWS GovCloud (US) Region, joining AWS GovCloud (US-West) to further help US government agencies, the contractors that serve them, and organizations in highly regulated industries move more of their workloads to the AWS Cloud by implementing a number of US government-specific regulatory requirements.
Similar to the AWS GovCloud (US-West), the AWS GovCloud (US-East) Region provides three Availability Zones and meets the stringent requirements of the public sector and highly regulated industries, including being operated on US soil by US citizens. It is accessible only to vetted US entities and AWS account root users, who must confirm that they are US citizens or US permanent residents. The AWS GovCloud (US-East) Region is located in the eastern part of the United States, providing customers with a second isolated Region in which to run mission-critical workloads with lower latency and high availability.
In 2011, AWS was the first cloud provider to launch an isolated infrastructure Region designed to meet the stringent requirements of government agencies and other highly regulated industries when it opened the AWS GovCloud (US-West) Region. The new AWS GovCloud (US-East) Region also meets the top US government compliance requirements, including:
- Federal Risk and Authorization Management Program (FedRAMP) Moderate and High baselines
- US International Traffic in Arms Regulations (ITAR)
- Federal Information Security Management Act (FISMA) Low, Moderate, and High baselines
- Department of Justice's Criminal Justice Information Services (CJIS) Security Policy
- Department of Defense (DoD) Impact Levels 2, 4, and 5
The AWS GovCloud (US) environments also conform to commercial security and privacy standards such as:
- Healthcare Insurance Portability and Accountability Act (HIPAA)
- Payment Card Industry (PCI) Security
- System and Organization Controls (SOC) 1, 2, and 3
- ISO/IEC27001, ISO/IEC 27017, ISO/IEC 27018, and ISO/IEC 9001 compliance, which are primarily for healthcare, life sciences, medical devices, automotive, and aerospace customers
Some of the largest organizations in the US public sector, as well as the education, healthcare, and financial services industries, are using AWS GovCloud (US) Regions. They appreciate the reduced latency, added redundancy, data durability, resiliency, greater disaster recovery capability, and the ability to scale across multiple Regions. This includes US government agencies and companies such as:
The US Department of Treasury, US Department of Veterans Affairs, Adobe, Blackboard, Booz Allen Hamilton, Drakontas, Druva, ECS, Enlighten IT, General Dynamics Information Technology, GE, Infor, JHC Technology, Leidos, NASA's Jet Propulsion Laboratory, Novetta, PowerDMS, Raytheon, REAN Cloud, a Hitachi Vantara company, SAP NS2, and Smartronix.
Purpose-built databases
The world is still changing and the categories of nonrelational databases continue to grow. We are increasingly seeing customers wanting to build Internet-scale applications that require diverse data models. In response to these needs, developers now have the choice of relational, key-value, document, graph, in-memory, and search databases. Each of these databases solve a specific problem or a group of problems.
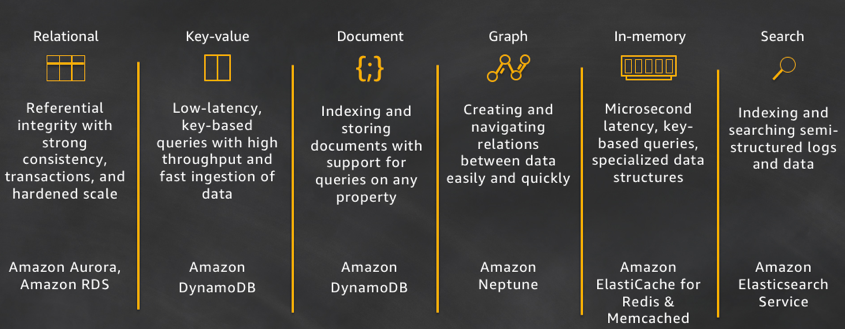
Let's take a closer look at the purpose for each of these databases:
- Relational: A relational database is self-describing because it enables developers to define the database's schema as well as relations and constraints between rows and tables in the database. Developers rely on the functionality of the relational database (not the application code) to enforce the schema and preserve the referential integrity of the data within the database. Typical use cases for a relational database include web and mobile applications, enterprise applications, and online gaming. Airbnb is a great example of a customer building high-performance and scalable applications with Amazon Aurora. Aurora provides Airbnb a fully-managed, scalable, and functional service to run their MySQL workloads.
- Key-value: Key-value databases are highly partitionable and allow horizontal scaling at levels that other types of databases cannot achieve. Use cases such as gaming, ad tech, and IoT lend themselves particularly well to the key-value data model where the access patterns require low-latency Gets/Puts for known key values. The purpose of DynamoDB is to provide consistent single-digit millisecond latency for any scale of workloads. This consistent performance is a big part of why the Snapchat Stories feature, which includes Snapchat's largest storage write workload, moved to DynamoDB.
- Document: Document databases are intuitive for developers to use because the data in the application tier is typically represented as a JSON document. Developers can persist data using the same document model format that they use in their application code. Tinder is one example of a customer that is using the flexible schema model of DynamoDB to achieve developer efficiency.
- Graph: A graph database's purpose is to make it easy to build and run applications that work with highly connected datasets. Typical use cases for a graph database include social networking, recommendation engines, fraud detection, and knowledge graphs. Amazon Neptune is a fully-managed graph database service. Neptune supports both the Property Graph model and the Resource Description Framework (RDF), giving you the choice of two graph APIs: TinkerPop and RDF/SPARQL. Current Neptune users are building knowledge graphs, making in-game offer recommendations, and detecting fraud. For example, Thomson Reuters is helping their customers navigate a complex web of global tax policies and regulations by using Neptune.
- In-memory: Financial services, Ecommerce, web, and mobile application have use cases such as leaderboards, session stores, and real-time analytics that require microsecond response times and can have large spikes in traffic coming at any time. We built Amazon ElastiCache, offering Memcached and Redis, to serve low latency, high throughput workloads, such as McDonald's, that cannot be served with disk-based data stores. Amazon DynamoDB Accelerator (DAX) is another example of a purpose-built data store. DAX was built is to make DynamoDB reads an order of magnitude faster.
- Search: Many applications output logs to help developers troubleshoot issues. Amazon Elasticsearch Service (Amazon ES) is purpose built for providing near real-time visualizations and analytics of machine-generated data by indexing, aggregating, and searching semi structured logs and metrics. Amazon ES is also a powerful, high-performance search engine for full-text search use cases. Expedia is using more than 150 Amazon ES domains, 30 TB of data, and 30 billion documents for a variety of mission-critical use cases, ranging from operational monitoring and troubleshooting to distributed application stack tracing and pricing optimization.
Building applications with purpose-built databases
Developers are building highly distributed and decoupled applications, and AWS enables developers to build these cloud-native applications by using multiple AWS services. Take Expedia, for example. Though to a customer the Expedia website looks like a single application, behind the scenes Expedia.com is composed of many components, each with a specific function. By breaking an application such as Expedia.com into multiple components that have specific jobs (such as microservices, containers, and AWS Lambda functions), developers can be more productive by increasing scale and performance, reducing operations, increasing deployment agility, and enabling different components to evolve independently. When building applications, developers can pair each use case with the database that best suits the need.
To make this real, take a look at some of our customers that are using multiple different kinds of databases to build their applications:
- Airbnb uses DynamoDB to store users' search history for quick lookups as part of personalized search. Airbnb also uses ElastiCache to store session states in-memory for faster site rendering, and they use MySQL on Amazon RDS as their primary transactional database.
- Capital One uses Amazon RDS to store transaction data for state management, Amazon Redshift to store web logs for analytics that need aggregations, and DynamoDB to store user data so that customers can quickly access their information with the Capital One app.
- Expedia built a real-time data warehouse for the market pricing of lodging and availability data for internal market analysis by using Aurora, Amazon Redshift, and ElastiCache. The data warehouse performs a multistream union and self-join with a 24-hour lookback window using ElastiCache for Redis. The data warehouse also persists the processed data directly into Aurora MySQL and Amazon Redshift to support both operational and analytical queries.
- Zynga migrated the Zynga poker database from a MySQL farm to DynamoDB and got a massive performance boost. Queries that used to take 30 seconds now take one second. Zynga also uses ElastiCache (Memcached and Redis) in place of their self-managed equivalents for in-memory caching. The automation and serverless scalability of Aurora make it Zynga's first choice for new services using relational databases.
- Johnson & Johnson uses Amazon RDS, DynamoDB, and Amazon Redshift to minimize time and effort spent on gathering and provisioning data, and allow the quick derivation of insights. AWS database services are helping Johnson & Johnson improve physicians' workflows, optimize the supply chain, and discover new drugs.
Just as they are no longer writing monolithic applications, developers also are no longer using a single database for all use cases in an application—they are using many databases. Though the relational database remains alive and well, and is still well suited for many use cases, purpose-built databases for key-value, document, graph, in-memory, and search uses cases can help you optimize for functionality, performance, and scale and—more importantly—your customers' experience. Build on.

The workplace of the future
We already have an idea of how digitalization, and above all new technologies like machine learning, big-data analytics or IoT, will change companies' business models — and are already changing them on a wide scale. So now's the time to examine more closely how different facets of the workplace will look and the role humans will have.
In fact, the future is already here – but it's still not evenly distributed. Science fiction author William Gibson said that nearly 20 years ago. We can observe a gap between the haves and the have-nots: namely between those who are already using future technologies and those who are not. The consequences of this are particularly visible on the labor market many people still don't know which skills will be required in the future or how to learn them.
Against that background, it's natural for people – even young digital natives – to feel some growing uncertainty. According to a Gallup poll, 37% of millennials are afraid of losing their jobs in the next 20 years due to AI. At the same time there are many grounds for optimism. Studies by the German ZEW Center for European Economic Research, for example, have found that companies that invest in digitalization create significantly more jobs than companies that don't.
How many of the jobs that we know today will even exist in the future? Which human activities can be taken over by machines or ML-based systems? Which tasks will be left over for humans to do? And will there be completely new types of the jobs in the future that we can't even imagine today?
Future of work or work of the future?
All of these questions are legitimate. "But where there is danger, a rescuing element grows as well." German poet Friedrich Hölderlin knew that already in the 19th century. As for me, I'm a technology optimist: Using technology to drive customer-centric convenience, such as in the cashier-less Amazon Go stores, will create shifts in where jobs are created. Thinking about the work of tomorrow, it doesn't help to base the discussion on structures that exist today. After the refrigerator was invented in the 1930s, many people who worked in businesses that sold ice feared for their jobs. Indeed, refrigerators made this business superfluous for the most part; but in its place, many new jobs were created. For example, companies that produced refrigerators needed people to build them, and now that food could be preserved, whole new businesses were created which were targeted at that market. We should not let ourselves be guided in our thinking by the perception of work as we know it today. Instead, we should think about how the workplace could look like in the future. And to do that, we need to ask ourselves an entirely different question, namely: What is changing in the workplace, both from an organizational and qualitative standpoint?
Many of the tasks carried out by people in manufacturing, for example, have remained similar over time in terms of the workflows. Even the activities of doctors, lawyers or taxi drivers have hardly changed in the last decade, at least in terms of their underlying processes. Only parts of the processes are being performed by machines, or at least supported by them. Ultimately, the desired product or service is delivered in – hopefully – the desired quality. But in the age of digitalization, people do much more than fill the gaps between the machines. The work done by humans and machines is built around solving customer problems. It's no longer about producing a car, but about the service "mobility", about bringing people to a specific location. "I want to be in a central place in Berlin as quickly as possible" is the requirement that needs to be fulfilled. In the first step we might reach this goal by combining the fastest mobility services through a digital platform; in the next, it might be a task fulfilled by Virtual Reality. These new offerings are organized on platforms or networks, and less so in processes. And artificial intelligence makes it possible to break down tasks in such a way that everyone contributes what he or she can do best. People define problems and pre-structure them, and machines or algorithms develop solutions that people evaluate in the end.
Radiologists are now assisted by machine-learning-driven tools that allow them to evaluate digital content in ways that were not possible before. Many radiologists have even claimed that ML-driven advice has significantly improved their ability to interpret X-rays.
I would even go a step further because I believe it's possible to "rehumanize" work and make our unique abilities as human beings even more important. Until now, access to digital technologies was limited above all by a machine's abilities: The interfaces to our systems are no longer machine-driven; in the future humans will be the starting point. For example, anyone who wanted to teach a robot how to walk in the age of automation had to exactly calculate every single angle of slope from the upper to lower thigh, as well as the speed of movement and other parameters, and then formulate them as a command in a programming language. In the future, we'll be able to communicate and work with robots more intensively in our "language". So teaching a robot to walk will be much easier in the future. The robot can be controlled by anyone via voice command, and it could train itself by analyzing how humans do it via a motion scanner, applying the process, and perfecting it.
With the new technological possibilities and greater computing power, work in the future will be more focused on people and less on machines. Machine learning can make human labor more effective. Companies like C-SPAN show how: scores of people would have to scan video material for hours in order to create keywords, for example, according to a person's name. Today, automated face recognition can do this task in seconds, allowing employees to immediately begin working with the results.
Redefining the relationship between human and machine
The progress at the interface of human and machine is happening at a very fast pace with already a visible impact on how we work. In the future, technology can become a much more natural part of our workplace that can be activated by several input methods — speaking, seeing, touching or even smelling. Take voice-control technologies, a field that is currently undergoing a real disruption. This area distinguishes itself radically from what we knew until now as the "hands-free" work approach, which ran purely through simple voice commands. Modern voice-control systems can understand, interpret and answer conversations in a professional way, which makes a lot of work processes easier to perform. Examples are giving diagnoses to patients or legal advice. At the end of 2018, voice (input) will have already significantly changed the way we develop devices and apps. People will be able to connect technologies into their work primarily through voice. One can already get an inkling of what that looks like in detail.
At the US space agency NASA, for example, Amazon Alexa organizes the ordering of conference rooms. A room doesn't always have to be requested for every single meeting. Rather, anyone who needs a room asks Alexa and the rest happens automatically. Everyone knows the stress caused by telephone conferences: they never start on time because someone hasn't found the right dial-in number and it takes a while until you've typed in the 8-digit number plus a 6-digit conference code. A voice command creates a lot more productivity. The AWS Service Transcribe could start creating a transcript right away during the meeting and send it to all participants afterwards. Other companies, such as the Japanese firm Mitsui or the software provider bmc, use Alexa for Business to achieve a more efficient and better collaboration between their employees, among others.
The software provider fme also uses voice control to offer its customers innovative applications in the field of business intelligence, social business collaboration and enterprise-content-management technologies. The customers of fme mainly come from life sciences and industrial manufacturing. Employees can search different types of content using voice control, navigate easily through the content, and have the content displayed or read to them. Users can have Alexa explain individual tasks to them in OpenText Documentum, to give another example. This could be used to make the onboarding of new employees faster and cheaper – their managers would not have to perform the same information ritual again and again. A similar approach can be found at pharmaceutical company AstraZeneca, which uses Alexa in its manufacturing: Team members can ask questions about standard processes to find out what they need to do next.
Of course, responsibilities and organizations will change as a result of these developments. Resources for administrative tasks can be turned into activities that have a direct benefit for the customer. Regarding the character of work in the future, we will probably need more "architects," "developers," "creatives," "relationship experts," "platform specialists," and "analysts" and fewer people who need to perform tasks according to certain pre-determined steps, as well as fewer "administrators". By speaking more to humans' need to create and shape, work might ultimately become more fulfilling and enjoyable.
Expanding the digital world
This new understanding of the relationship between man and machine has another important effect: It will significantly expand the number of people who can participate in digital value creation: older people, people who at the moment don't have access to a computer or smartphone, people for whom using the smartphone in a specific situation is too complicated, and people in developing countries who can't read or write. A good example of the latter is rice farmers who work with the International Rice Research Institute, an organization based near Manila, the Philippines. The institute's mission is to fight poverty, hunger and malnutrition by easing the lives and work of rice farmers. Rice farmers can benefit from knowledge to which they wouldn't have access were they on their own. The institute has saved 70,000 DNA sequences of different types of rice, from which conclusions can be drawn about the best conditions for growing rice. Every village has a telephone, and by using it the farmers can access this knowledge: they select their dialect in a menu and describe which piece of land they tend. The service is based on machine learning. It generates recommendations on how much fertilizer is needed and when the best time is to plant the crops. So with the help of digital technologies, farmers can see how their work becomes more valuable: a given amount of effort produces a richer harvest of rice.
Until now we only have a tiny insight into the possibilities for the world of work. But they make clear that the quality of work for us humans will most probably increase, and that technology can allow us to perform many activities that we still cannot imagine today. Although there are twice as many robots per capita in German companies than in US firms, German industry still has trouble finding qualified employees rather than having to fight unemployment. In the future we humans will be able to carry out activities in a way that is closer to our creative human nature than is the case today. I believe that if we want to do justice to the technological possibilities, we should do it like Hölderlin and have faith in the rescue, but at the same time try to minimize the risks by understanding and shaping things.

Interfacing a Relational Database to the Web
How does an RDBMS talk to the rest of the world?
Remember the African Grey parrot we trained in the last chapter? The one holding down a $250,000 information systems management position saying "We're pro-actively leveraging our object-oriented client/server database to target customer service during reengineering"? The profound concept behind the "client/server" portion of this sentence is that the database server is a program that sits around waiting for another program, the database client, to request a connection. Once the connection is established, the client sends SQL queries to the server, which inspects the physical database and returns the matching data. These days, connections are generally made via TCP sockets even if the two programs are running on the same computer. Here's a schematic: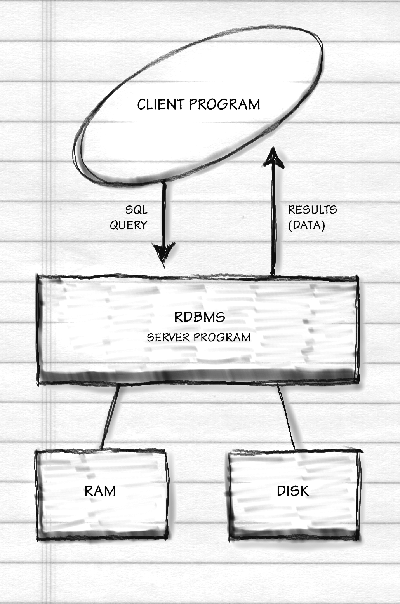
Lets's get a little more realistic and dirty. In a classical RDBMS, you have a daemon program that waits for requests from clients for new connections. For each client, the daemon spawns a server program. All the servers and the daemon cache data from disk and communicate locking information via a large block of shared RAM (often as much as 1 GB). The raison d'etre of an RDBMS is that N clients can simultaneously access and update the tables. We could have an AOLserver database pool taking up six of the client positions, a programmer using a shell-type tool such as SQL*Plus as another, an administrator using Microsoft Access as another, and a legacy CGI script as the final client. The client processes could be running on three or four separate physical computers. The database server processes would all be running on one physical computer (this is why Macintoshes and Windows 95/98 machines, which lack multiprocessing capability, are not used as database servers). Here's a schematic:
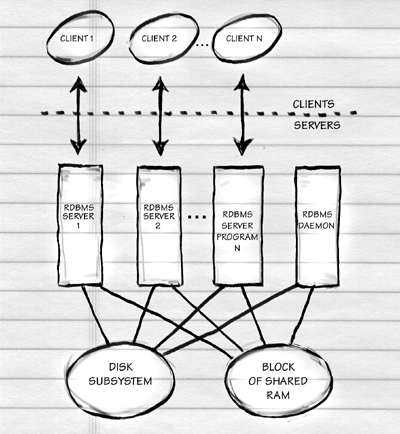
Note that the schematic above is for a "classical" RDBMS. The trend is for database server programs to run as one operating system process with multiple kernel threads. This is an implementation detail, however, that doesn't affect the logical structure that you see in the schematic.
For a properly engineered RDBMS-backed Web site, the RDBMS client is the Web server program, e.g., AOLserver. The user types something into a form on a Web client (e.g., Netscape Navigator) and that gets transmitted to the Web server which has an already-established connection to an RDBMS server (e.g., Oracle). The data then go back from the RDBMS server to the RDBMS client, the Web server, which sends them back to the Web client:
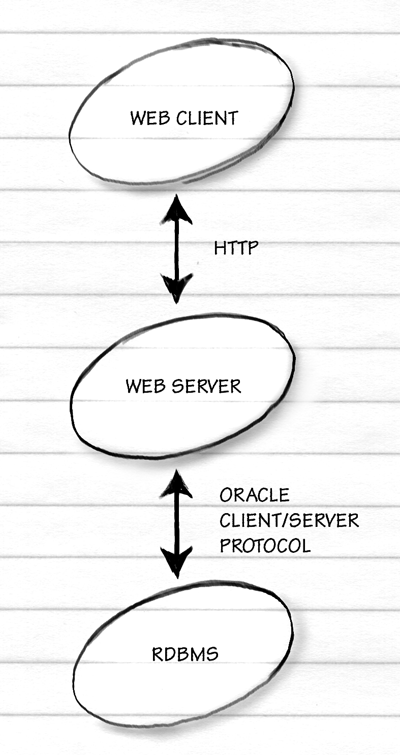
Note that an essential element here is database connection pooling. The Web server program must open connections to the database and keep them open. When a server-side program needs to query the database, the Web server program finds a free database connection and hands it to the program.
Does this system sound complicated and slow? Well, yes it is, but not as slow as the ancient method of building RDBMS-backed Web sites. In ancient times, people used CGI scripts. The user would click on the "Submit" button in his Web client (e.g., Netscape Navigator) causing the form to be transmitted to the Web server (e.g., NCSA 1.4). The Web server would fork off a CGI script, starting up a new operating system process. Modern computers are very fast, but think about how long it takes to start up a word processing program versus making a change to a document that is already open. Once running, the CGI program would immediately ask for a connection to the RDBMS, often resulting in the RDBMS forking off a server process to handle the new request for connection. The new RDBMS server process would ask for a username and password and authenticate the CGI script as a user. Only then would the SQL transmission and results delivery commence. A lot of sites are still running this way in 1998 but either they aren't popular or they feel unresponsive. Here's a schematic:
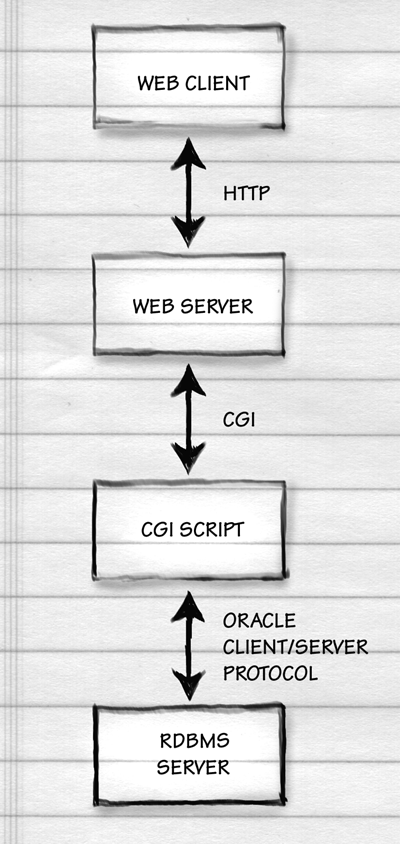
How to make really fast RDBMS-backed Web sites
 The Web-server-as-database-client software architecture is the fastest currently popular Web site architecture. The Web server program maintains a pool of already-open connections to one or more RDBMS systems. You write scripts that run inside the Web server program's process instead of as CGI processes. For each URL requested, you save
The Web-server-as-database-client software architecture is the fastest currently popular Web site architecture. The Web server program maintains a pool of already-open connections to one or more RDBMS systems. You write scripts that run inside the Web server program's process instead of as CGI processes. For each URL requested, you save- the cost of starting up a process ("forking" on a Unix system) for the CGI script
- the cost of starting up a new database server process (though Oracle 7 and imitators pre-fork server processes and many new RDBMS systems are threaded)
- the cost of establishing the connection to the database, including a TCP session and authentication (databases have their own accounts and passwords)
- the cost of tearing all of this down when it is time to return data to the user
If you are building a richly interactive site and want the ultimate in user responsiveness, then client-side Java is the way to go. You can write a Java applet that, after a painful and slow initial download, starts running inside the user's Web client. The applet can make its own TCP connection back to the RDBMS, thus completely bypassing the Web server program. The problems with this approach include security, licensing, performance, and compatibility.
The client/server RDBMS abstraction barrier means that if you're going to allow a Java applet that you distribute to connect directly to your RDBMS, then in effect you're going to permit any program on any computer anywhere in the world to connect to your RDBMS. To deal with the security risk that this presents, you have to create a PUBLIC database user with a restricted set of privileges. Database privileges are specifiable on a set of actions, tables, and columns. It is not possible to restrict users to particular rows. So in a classified ad system, if the PUBLIC user has enough privileges to delete one row, then a malicious person could easily delete all the rows in the ads table.
The magnitude of the licensing problem raised by having Java applets connect directly to your RDBMS depends on the contract you have with your database management system vendor and the vendor's approach to holding you to that contract. Under the classical db-backed Web site architecture, the Web server might have counted as one user even if multiple people were connecting to the Web site simultaneously. Certainly, it would have looked like one user to fancy license manager programs even if there was legal fine print saying that you have to pay for the multiplexing. Once you "upgrade to Java," each Java applet connecting to your RDBMS will definitely be seen by the license manager program as a distinct user. So you might have to pay tens of thousands of dollars extra even though your users aren't really getting anything very different.
A standard RDBMS will fork a server process for each connected database client. Thus if you have 400 people playing a game in which each user interacts with a Java applet connected to Oracle, your server will need enough RAM to support 400 Oracle server processes. It might be more efficient in terms of RAM and CPU to program the Java applets to talk to AOLserver Tcl scripts via HTTP and let AOLServer multiplex the database resource among its threads.
The last problem with a Java applet/RDBMS system is the most obvious: Users without Java-compatible browsers won't be able to use the system. Users with Java-compatible browsers behind corporate firewall proxies that block Java applet requests will not be able to use the system. Users with Java-compatible browsers who successfully obtain your applet may find their machine (Macintosh; Windows 95) or browser process (Windows NT; Unix) crashing.
CORBA: MiddleWare Meets VaporWare
 A variant of the Java-connects-directly-to-the-RDBMS architecture is Java applets running an Object Request Broker (ORB) talking to a Common Object Request Broker Architecture (CORBA) server via the Internet Inter-ORB Protocol (IIOP). The user downloads a Java applet. The Java applet starts up an ORB. The ORB makes an IIOP request to get to your server machines's CORBA server program. The CORBA server requests an object from the server machine's ORB. The object, presumably some little program that you've written, is started up by the ORB and makes a connection to your RDBMS and then starts streaming the data back to the client.
A variant of the Java-connects-directly-to-the-RDBMS architecture is Java applets running an Object Request Broker (ORB) talking to a Common Object Request Broker Architecture (CORBA) server via the Internet Inter-ORB Protocol (IIOP). The user downloads a Java applet. The Java applet starts up an ORB. The ORB makes an IIOP request to get to your server machines's CORBA server program. The CORBA server requests an object from the server machine's ORB. The object, presumably some little program that you've written, is started up by the ORB and makes a connection to your RDBMS and then starts streaming the data back to the client.
CORBA is the future. CORBA is backed by Netscape, Oracle, Sun, Hewlett-Packard, IBM, and 700 other companies (except Microsoft, of course). CORBA is so great, its proponents proudly proclaim it to be . . . "middleware":
"The (ORB) is the middleware that establishes the client-server relationships between objects. Using an ORB, a client can transparently invoke a method on a server object, which can be on the same machine or across a network. The ORB intercepts the call and is responsible for finding an object that can implement the request, pass it the parameters, invoke its method, and return the results. The client does not have to be aware of where the object is located, its programming language, its operating system, or any other system aspects that are not part of an object's interface. In so doing, the ORB provides interoperability between applications on different machines in heterogeneous distributed environments and seamlessly interconnects multiple object systems."
-- http://www.omg.org/
The basic idea of CORBA is that every time you write a computer program you also write a description of the computer program's inputs and outputs. Modern business managers don't like to buy computer programs anymore so we'll call the computer program an "object". Technology managers don't like powerful computer languages such as Common Lisp so we'll write the description in a new language: Interface Definition Language (IDL).
Suppose that you've written an object (computer program) called
find_cheapest_flight_to_paris and declared that it can take methods such as quote_fare with arguments of city name and departure date and book_ticket with the same arguments plus credit card number and passenger name.
Now a random computer program (object) out there in Cyberspace can go hunting via ORBs for an object named
find_cheapest_flight_to_paris. The foreign object will discover the program that you've written, ask for the legal methods and arguments, and start using your program to find the cheapest flights to Paris.
The second big CORBA idea is the ability to wrap services such as transaction management around arbitrary computer programs. As long as you've implemented all of your programs to the CORBA standard, you can just ask the Object Transaction Service (OTS) to make sure that a bunch of methods executed on a bunch of objects all happen or that none happen. You won't have to do everything inside the RDBMS anymore just because you want to take advantage of its transaction system.
Complexity (or "It Probably Won't Work")
 Given the quality of the C code inside the Unix and Windows NT operating systems and the quality of the C code inside RDBMS products, it is sometimes a source of amazement to me that there is even a single working RDBMS-backed Web site on the Internet. What if these sites also had to depend on two ORBs being up and running? Netscape hasn't yet figured out how to make a browser that can run a simple Java animation without crashing, but we're supposed to trust the complicated Java ORB that they are putting into their latest browsers?
Given the quality of the C code inside the Unix and Windows NT operating systems and the quality of the C code inside RDBMS products, it is sometimes a source of amazement to me that there is even a single working RDBMS-backed Web site on the Internet. What if these sites also had to depend on two ORBs being up and running? Netscape hasn't yet figured out how to make a browser that can run a simple Java animation without crashing, but we're supposed to trust the complicated Java ORB that they are putting into their latest browsers?
Actually I'm being extremely unfair. I've never heard, for example, of a bug in a CORBA Concurrency Control Service, used to manage locks. Perhaps, though, that is because eight years after the CORBA standard was proposed, nobody has implemented a Concurrency Control Service. CORBA circa 1998 is a lot like an Arizona housing development circa 1950. The architect's model looks great. The model home is comfortable. You'll have water and sewage hookups real soon now.
What If It Did Work?
 Assume for the sake of argument that all the CORBA middleware actually worked. Would it usher in a new dawn of reliable, high-performance software systems? Yes, I guess so, as long as your idea of new dawn dates back to the late 1970s.
Assume for the sake of argument that all the CORBA middleware actually worked. Would it usher in a new dawn of reliable, high-performance software systems? Yes, I guess so, as long as your idea of new dawn dates back to the late 1970s.
Before the Great Microsoft Technology Winter, there were plenty of systems that functioned more or less like CORBA. Xerox Palo Alto Research Center produced SmallTalk and the InterLISP machines. MIT produced the Lisp Machine. All of these operating systems/development environments supported powerful objects. The objects could discover each other. The objects could ask each other what kinds of methods they provided. Did that mean that my objects could invoke methods on your objects without human intervention?
No. Let's go back to our
find_cheapest_flight_to_paris example. Suppose the foreign object is looking for find_cheap_flight_to_paris. It won't find your perfectly matching object because of the slight difference in naming. Or suppose the foreign object is looking for find_cheapest_flight and expects to provide the destination city in an argument to a method. Again, your object can't be used.
That was 1978, though. Isn't CORBA an advancement over Lisp and SmallTalk? Sure. CORBA solves the trivial problem of objects calling each other over computer networks rather than from within the same computer. But CORBA ignores the serious problem of semantic mismatches. My object doesn't get any help from CORBA in explaining to other objects that it knows something about airplane flights to Paris.
This is my personal theory for why CORBA has had so little practical impact during its eight-year life.
Aren't Objects The Way To Go?
 Maybe CORBA is nothing special, but wouldn't it be better to implement a Web service as a bunch of encapsulated objects with advertised methods and arguments? After all, object-oriented programming is a useful tool for building big systems.
Maybe CORBA is nothing special, but wouldn't it be better to implement a Web service as a bunch of encapsulated objects with advertised methods and arguments? After all, object-oriented programming is a useful tool for building big systems.
The simple answer is that a Web service already is an encapsulated object with advertised methods and arguments. The methods are the legal URLs, "insert-msg.tcl" or "add-user.tcl" for example. The arguments to these methods are the form-variables in the pages that precede these URLs.
A more balanced answer is that a Web service is already an encapsulated object but that its methods and arguments are not very well advertised. We don't have a protocol whereby Server A can ask Server B to "please send me a list of all your legal URLs and their arguments." Hence, CORBA may one day genuinely facilitate server-to-server communication. For the average site, though, it isn't clear whether the additional programming effort over slapping something together in AOLserver Tcl, Apache mod_perl, or Microsoft ASP is worth it. You might decide to completely redesign your Web service before CORBA becomes a reality.
In concluding this CORBA-for-Cavemen discussion, it is worth noting that the issues of securing your RDBMS are the same whether you are using a classical HTTP-only Web service architecture or CORBA.
e- Key Shifting
 I hope that we have spent most of our time in this book thinking about how to design Web services that will be popular and valued by users. I hope that I've also conveyed some valuable lessons about achieving high performance and reliability. However, a responsive, reliable, and popular Web server that is delivering data inserted by your enemies isn't anything to e-mail home about. So it is worth thinking about security occasionally. I haven't written anything substantial about securing a standard Windows NT or Unix server. I'm not an expert in this field, there are plenty of good books on the subject, and ultimately it isn't possible to achieve perfect security so you'd better have a good set of backup tapes. However, running any kind of RDBMS raises a bunch of new security issues that I have spent some time thinking about so let's look at how Carrie Cracker can get into your database.
I hope that we have spent most of our time in this book thinking about how to design Web services that will be popular and valued by users. I hope that I've also conveyed some valuable lessons about achieving high performance and reliability. However, a responsive, reliable, and popular Web server that is delivering data inserted by your enemies isn't anything to e-mail home about. So it is worth thinking about security occasionally. I haven't written anything substantial about securing a standard Windows NT or Unix server. I'm not an expert in this field, there are plenty of good books on the subject, and ultimately it isn't possible to achieve perfect security so you'd better have a good set of backup tapes. However, running any kind of RDBMS raises a bunch of new security issues that I have spent some time thinking about so let's look at how Carrie Cracker can get into your database.
Before Carrie can have a data modeling language (INSERT, UPDATE, DELETE) party with your data, she has to
- successfully connect to the IP address and port where the RDBMS is listening, and
- once connected, present a username and password pair recognized by the RDBMS.
 One of the easiest ways to prevent direct network connections to your RDBMS is to use a traditional RDBMS in a non-traditional manner. If you install Oracle8, you'd have to spend a whole day reading SQL*Net manuals before you can think about setting up networking. The only programs that will be able to connect to your new Oracle server are programs running on the RDBMS server itself. This would be useless in an insurance company where clerks at 1000 desktops need to connect to Oracle. But for many Web sites, there is no reason why you can't run the database and Web server on the same box. The database will consume 95 percent of your resources. So if a computer is big enough to run Oracle, you can just add a tiny bit of CPU and memory and have a maximally reliable site (since you only have to keep one computer up and running).
One of the easiest ways to prevent direct network connections to your RDBMS is to use a traditional RDBMS in a non-traditional manner. If you install Oracle8, you'd have to spend a whole day reading SQL*Net manuals before you can think about setting up networking. The only programs that will be able to connect to your new Oracle server are programs running on the RDBMS server itself. This would be useless in an insurance company where clerks at 1000 desktops need to connect to Oracle. But for many Web sites, there is no reason why you can't run the database and Web server on the same box. The database will consume 95 percent of your resources. So if a computer is big enough to run Oracle, you can just add a tiny bit of CPU and memory and have a maximally reliable site (since you only have to keep one computer up and running).
Suppose that you must install SQL*Net to let folks inside your organization talk directly to Oracle, or that you're using a newer-style RDBMS (e.g., Solid) that is network-centric. By installing the RDBMS, you've opened a huge security hole: a program listening on a TCP port and happy to accept connections from anywhere on the Internet.
A remarkably incompetent publisher would be
- running the RDBMS on the same machine as the Web server, both binding to the same well-advertised IP address
- leaving the RDBMS to listen on the default port numbers
- leaving the RDBMS with well-known usernames and passwords (e.g., "scott/tiger" for Oracle)
Is anyone out there on the Internet really this incompetent? Sure! I have done at least one consulting job for a company whose Web server had been set up and left like this for months. The ISP was extremely experienced with both the Web server program and the RDBMS being used. The ISP was charging my client thousands of dollars per month. Was this reasonably popular site assaulted by the legions of crackers one reads about in the dead trees media? No. Nobody touched their data. The lesson: Don't spend your whole life worrying about security.
However, you'll probably sleep better if you spend at least a little time foiling Carrie Cracker. The easiest place to start is with the username/password pairs. You want to set these to something hard to guess. Unfortunately, these aren't super secure because they often must be stored as clear text in CGI scripts or cron jobs that connect to the database. Then anyone who gets a Unix username/password pair can read the CGI scripts and collect the database password. On a site where the Web server itself is the database client, the Web server configuration files will usually contain the database password in clear text. This is only one file so it is easy to give it meager permissions but anyone who can become root on your Unix box can certainly read it.
A worthwhile parallel approach is to try to prevent Carrie from connecting to the RDBMS at all. You could just configure your RDBMS to listen on different ports from the default. Carrie can't get in anymore by just trying port 7599 because she saw the little "backed by Sybase" on your home page and knows that Sybase will probably be listening there. Carrie will have to sweep up and down the port numbers until your server responds. Maybe she'll get bored and try someone else's site.
A much more powerful approach is moving the database server behind a firewall. This is necessary mostly because RDBMSes have such lame security notions. For example, it should be possible to tell the RDBMS, "Only accept requests for TCP connections from the following IP addresses . . .". Every Web server program since 1992 has been capable of this. However, I'm not aware of any RDBMS vendor who has figured this out. They talk the Internet talk, but they walk the intranet walk.
Because Oracle, Informix, and Sybase forgot to add a few lines of code to their product, you'll be adding $10,000 to your budget and buying a firewall computer. This machine sits between the Internet and the database server. Assuming your Web server is outside the firewall, you program the firewall to "not let anyone make a TCP connection to port 7599 on the database server except 18.23.0.16 [your Web server]." This works great until someone compromises your Web server. Now they are root on the computer that the firewall has been programmed to let connect to the database server. So they can connect to the database.
Oops.
So you move your Web server inside the firewall, too. Then you program the firewall to allow nobody to connect to the database server for any reason. The only kind of TCP connection that will be allowed will be to port 80 on the Web server (that's the default port for HTTP). Now you're reasonably secure:
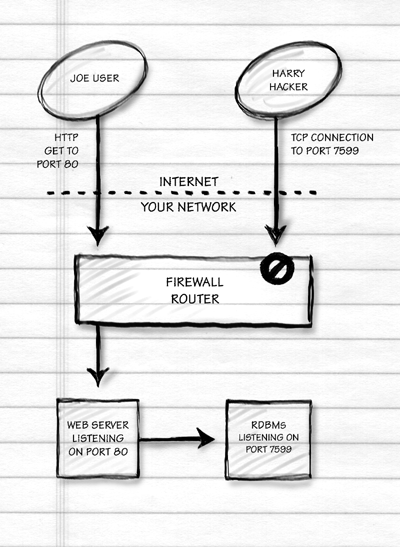
What does this stuff look like?
Here's a typical AOLserver Tcl API db-backed page. Tcl is a safe language and an incorrect Tcl program will not crash AOLserver or result in a denial of service to other users. This program reads through a table of e-mail addresses and names and prints each one as a list item in an unnumbered list. If this is placed in a file named "view.tcl" in the Greedy Corporation's Web server root directory then it may be referenced at http://www.greedy.com/view.tcl.
# send basic text/html headers back to the client
ns_write "HTTP/1.0 200 OK
MIME-Version: 1.0
Content-Type: text/html
"
# write the top of the page
# note that we just put static HTML in a Tcl string and then
# call the AOLserver API function ns_write
ns_write "<head>
<title>Entire Mailing List</title>
</head>
<body>
<h2>Entire Mailing List</h2>
<hr>
<ul>
"
# get an open database from the AOLserver
# and set the ID of that connection to the local variable DB
set db [ns_db gethandle]
# open a database cursor bound to the local variable SELECTION
# we want to read all the columns (*) from the mailing_list table
set selection [ns_db select $db "select * from mailing_list
order by upper(email)"]
# loop through the cursor, calling ns_db getrow to bind
# the Tcl local variable SELECTION to a set of values for
# each row; it will return 0 when there are no more rows
# in the cursor
while { [ns_db getrow $db $selection] } {
# pull email and name out of SELECTION
set email [ns_set get $selection email]
set name [ns_set get $selection name]
ns_write "<li><a href=\"mailto:$email\">$email</a> ($name)\n"
}
ns_write "</ul>
<hr>
<address><a href=\"mailto:philg@mit.edu\">philg@mit.edu</a></address>
</body>
"
Let's try something similar in Oracle Application Server. We're going to use PL/SQL, Oracle's vaguely ADA-inspired procedural language that runs inside the server process. It is a safe language and an incorrect PL/SQL program will usually not compile. If an incorrect program gets past the compiler, it will not run wild and crash Oracle unless there is a bug in the Oracle implementation of PL/SQL. This PL/SQL program is from a bulletin board system. It takes a message ID argument, fetches the corresponding message from a database table, and writes the content out in an HTML page. Note that in Oracle WebServer 2.0 there is a 1-1 mapping between PL/SQL function names and URLs. This one will be referenced via a URL of the following form:
Nobody ever said Oracle was pretty...
http://www.greedy.com/public/owa/bbd_fetch_msg
-- this is a definition that we feed directly to the database
-- in an SQL*PLUS session. So the procedure definition is itself
-- an extended SQL statement. The first line says I'm a Web page
-- that takes one argument, V_MSG_ID, which is a variable length
-- character string
create or replace procedure bbd_fetch_msg ( v_msg_id IN varchar2 )
AS
-- here we must declare all the local variables
-- the first declaration reaches into the database and
-- makes the local variable bboard_record have
-- the same type as a row from the bboard table
bboard_record bboard%ROWTYPE;
days_since_posted integer;
age_string varchar2(100);
BEGIN
-- we grab all the information we're going to need
select * into bboard_record from bboard where msg_id = v_msg_id;
-- we call the Oracle function "sysdate" just as we could
-- in a regular SQL statement
days_since_posted := sysdate - bboard_record.posting_time;
-- here's something that you can't have in a declarative
-- language like SQL... an IF statement
IF days_since_posted = 0 THEN
age_string := 'today';
ELSIF days_since_posted = 1 THEN
age_string := 'yesterday';
ELSE
age_string := days_since_posted || ' days ago';
END IF;
-- this is the business end of the procedure. We
-- call the Oracle WebServer 2.0 API procedure htp.print
-- note that the argument is a big long string produced
-- by concatenating (using the "||" operator) static
-- strings and then information from bboard_record
htp.print('<html>
<head>
<title>' || bboard_record.one_line || '</title>
</head>
<body bgcolor=#ffffff text=#000000>
<h3>' || bboard_record.one_line || '</h3>
from ' || bboard_record.name || '
(<a href="mailto:' || bboard_record.email || '">'
|| bboard_record.email || '</a>)
<hr>
' || bboard_record.message || '
<hr>
(posted '|| age_string || ')
</body>
</html>');
END bbd_fetch_msg;
The first thing to note in this program is that we choose "v_msg_id" instead of the obvious "msg_id" as the procedure argument. If we'd used "msg_id", then our database query would have been
which is pretty similar to
select * into bboard_record from bboard where msg_id = msg_id;
Does that look a little strange? It should. The WHERE clause is inoperative here because it is tautological. Every row in the table will have msg_id = msg_id so all the rows will be returned. This problem didn't arise in our AOLserver Tcl program because the Tcl was being read by the Tcl interpreter compiled into the AOLserver and the SQL was being interpreted by the RDBMS back-end. With a PL/SQL program, the whole thing is executing in the RDBMS.
select * from bboard where msg_id = msg_id;
Another thing to note is that it would be tough to rewrite this procedure to deal with a multiplicity of database tables. Suppose you decided to have a separate table for each discussion group. So you had
photo_35mm_bboard and photo_medium_format_bboard tables. Then you'd just add a v_table_name argument to the procedure. But what about these local variable declarations?This says "Set up the local variable bboard_record so that it can hold a row from the bboard table". No problem. You just replace the static bboard with the new argument
bboard_record bboard%ROWTYPE;
and voila... you get a compiler error: "v_table_name could not be found in the database." All of the declarations have to be computable at compile time. The spirit of PL/SQL is to give the compiler enough information at procedure definition time so that you won't have any errors at run-time.
bboard_record v_table_name%ROWTYPE;
You're not in Kansas anymore and you're not Web scripting either. This is programming. You're declaring variables. You're using a compiler that will be all over you like a cheap suit if you type a variable name incorrectly. Any formally trained computer scientist should be in heaven. Well, yes and no. Strongly typed languages like ADA and Pascal result in more reliable code. This is great if you are building a complicated program like a fighter jet target tracking system. But when you're writing a Web page that more or less stands by itself, being forced to dot all the i's and cross all the t's can be an annoying hindrance. After all, since almost all the variables are going to be strings and you're just gluing them together, what's the point of declaring types?
I don't think it is worth getting religious over which is the better approach. For one thing, as discussed in the chapter "Sites that are really databases" this is the easy part of building a relational database-backed Web site. You've developed your data model, defined your transactions, and designed your user interface. You're engaged in an almost mechanical translation process. For another, if you were running AOLserver with Oracle as the back-end database, you could have the best of both worlds by writing simple Tcl procedures that called PL/SQL functions. We would touch up the definition bbd_fetch_msg so that it was designed as a PL/SQL function, which can return a value, rather than as a procedure, which is called for effect. Then instead of
htp.print we'd simply RETURN the string. We could interface it to the Web with a five-line AOLserver Tcl function:# grab the input and set it to Tcl local variable MSG_ID set_form_variables # get an open database connection from AOLserver set db [ns_db gethandle] # grab one row from the database. Note that we're using the # Oracle dummy table DUAL because we're only interested in the # function value and not in any information from actual tables. set selection [ns_db 1row $db "select bbd_fetch_msg('$msg_id') as moby_string from dual"] # Since we told the ns_db API call that we only expected # one row back, it put the row directly into the SELECTION # variable and we don't have to call ns_db getrow set moby_string [ns_set get selection moby_string] # we call the AOLserver API call ns_return to # say "status code 200; MIME type is text/html" # and then send out the page ns_return 200 text/html $moby_string
Application Servers
 Application servers for Web publishing are generally systems that let you write database-backed Web pages in Java. The key selling points of these systems, which sell for as much as $35,000 per CPU, are increased reliability, performance, and speed of development.
Application servers for Web publishing are generally systems that let you write database-backed Web pages in Java. The key selling points of these systems, which sell for as much as $35,000 per CPU, are increased reliability, performance, and speed of development.Problem 1: compilation
Java, because it must be compiled, is usually a bad choice of programming language for Web services (see the chapter on server-side programming). Thus, an application server increases development time.Problem 2: Java runs inside the DBMS now
If what you really want to do is write some Java code that talks to data in your database, you can execute Java right inside of your RDBMS (Oracle 8.1, Informix 9.x). Java executing inside the database server's process is always going to have faster access to table data than Java running as a client. In fact, at least with Oracle on a Unix box, you can bind Port 80 to a program that will call a Java program running in the Oracle RDBMS. You don't even need a Web server, much less an application server. It is possible that you'll get higher performance and easier development by adding a thin-layer Web server like AOLserver or Microsoft's IIS/ASP, but certainly you can't get higher reliability by adding a bunch of extra programs and computers to a system that need only have relied on one program and one computer.
An application server reduces Web site speed and reliability.
PC Week tested Netscape Application Server and Sapphire/Web on June 22, 1998 and found that they weren't able to support more than 10 simultaneous users on a $200,000 8-CPU Sun SPARC/Solaris E4000 server. Not only did the products crash frequently but sometimes in such innovative ways that they had to reboot the whole computer (something done once every 30 to 90 days on a typical Unix server).
Problem 3: non-standard API
 Application servers encourage publishers to write Java code to non-standard specifications. If you really want to build a Web site in Java, use the Java Servlet standard so that you can run the same code under AOLserver, Apache, Microsoft IIS, Netscape Enterprise, Sun Java Server, etc.
Application servers encourage publishers to write Java code to non-standard specifications. If you really want to build a Web site in Java, use the Java Servlet standard so that you can run the same code under AOLserver, Apache, Microsoft IIS, Netscape Enterprise, Sun Java Server, etc. One nice thing
 Because compiling Java is so difficult, application servers out of necessity usually enforce a hard separation between people who do design (build templates) and those who write programs to query the database (write and compile Java programs). Generally, people can only argue about things that they understand. Thus, a bunch of business executives will approve a $1 billion nuclear power plant without any debate but argue for hours about whether the company should spend $500 on a party. They've all thrown parties before so they have an idea that maybe paper cups can be purchased for less than $2.75 per 100. But none of them has any personal experience purchasing cooling towers.
Because compiling Java is so difficult, application servers out of necessity usually enforce a hard separation between people who do design (build templates) and those who write programs to query the database (write and compile Java programs). Generally, people can only argue about things that they understand. Thus, a bunch of business executives will approve a $1 billion nuclear power plant without any debate but argue for hours about whether the company should spend $500 on a party. They've all thrown parties before so they have an idea that maybe paper cups can be purchased for less than $2.75 per 100. But none of them has any personal experience purchasing cooling towers.
Analogously, if you show a super-hairy transactional Web service to a bunch of folks in positions of power at a big company, they aren't going to say "I think you would get better linguistics performance if you kept a denormalized copy of the data in the Unix file system and indexed it with PLS". Nor are they likely to opine that "You should probably upgrade to Solaris 2.6 because Sun rewrote the TCP stack to better handle 100+ simultaneous threads." Neither will they look at your SQL queries and say "You could clean this up by using the Oracle tree extensions; look up CONNECT BY in the manual."
What they will say is, "I think that page should be a lighter shade of mauve". In an application server-backed site, this can be done by a graphic designer editing a template and the Java programmer need never be aware of the change.
Do you need to pay $35,000 per CPU to get this kind of separation of "business logic" from presentation? No. You can download AOLserver for free and send your staff the following:
Similarly, if you've got Windows NT you can just use Active Server Pages with a similar directive to the developers: Put the SQL queries in a COM object and call it at the top of an ASP page; then reference the values returned within the HTML. Again, you save $35,000 per CPU and both AOLserver and Active Server Pages have much cleaner templating syntax than the application server products.To: Web Developers I want you to put all the SQL queries into Tcl functions that get loaded at server start-up time. The graphic designers are to build ADP pages that call a Tcl procedure which will set a bunch of local variables with values from the database. They are then to stick <%=$variable_name=> in the ADP page wherever they want one of the variables to appear. Alternatively, write .tcl scripts that implement the business logic and, after stuffing a bunch of local vars, call ns_adp_parse to drag in the ADP created by the graphic designer.
Furthermore, if there are parts of your Web site that don't have elaborate presentation, e.g., admin pages, you can just have the programmers code them up using standard AOLserver .tcl or .adp style (where the queries are mixed in with HTML).
Finally, you can use the Web standards to separate design from presentation. With the 4.x browsers, it is possible to pack a surprising amount of design into a cascading style sheet. If your graphic designers are satisfied with this level of power, your dynamic pages can pump out rat-simple HTML.
From my own experience, some kind of templating discipline is useful on about 25 percent of the pages in a typical transactional site. Which 25 percent? The pages that are viewed by the public (and hence get extensively designed and redesigned) and also require at least a screen or two of procedural language statements or SQL. Certainly templating is merely an annoyance when building admin pages, which are almost always plain text. Maybe that's why I find application servers so annoying; there are usually a roughly equal number of admin and user pages on the sites that I build.
Note: For a more detailed discussion of application servers, see http://www.photo.net/wtr/application-servers.html.
Server-Side Web/RDBMS Products that Work
 Let's try to generally categorize the tools that are available. This may sound a little familiar if you've recently read the options and axes for evaluating server-side scripting languages and environments that I set forth in "Sites That Are Really Programs". However, there are some new twists to consider when an RDBMS is in the background.
Let's try to generally categorize the tools that are available. This may sound a little familiar if you've recently read the options and axes for evaluating server-side scripting languages and environments that I set forth in "Sites That Are Really Programs". However, there are some new twists to consider when an RDBMS is in the background.
Before selecting a tool, you must decide how much portability you need. For example, the PL/SQL script above will work only with the Oracle RDBMS. The AOLserver Tcl scripts above would work with any RDBMS if SQL were truly a standard. However, Oracle handles datetime arithmetic and storage in a non-standard way. So if you wanted to move an AOLserver Tcl application to Informix or some other product that uses ANSI-standard datetime syntax, you'd most likely have to edit any script that used datetime columns. If you were using Java Servlets and JDBC, in theory you could code in pure ANSI SQL and the JDBC driver would translate it into Oracle SQL.
Why not always use the tools that give the most portability? Because portability involves abstraction and layers. It may be more difficult to develop and debug portable code. For example, my friend Jin built some Web-based hospital information systems for a company that wants to be able to sell to hospitals with all kinds of different database management systems. So he coded it in Java/JDBC and the Sun JavaWebServer. Though he was already an experienced Java programmer, he found that it took him ten times longer to write something portable in this environment than it does to write AOLserver Tcl that is Oracle-specific. I'd rather write ten times as many applications and be stuck with Oracle than labor over portable applications that will probably have to be redesigned in a year anyway.
Speaking of labor, you have to look around realistically at the programming and sysadmin resources available for your project. Some tools are clearly designed for MIS departments with 3-year development schedules and 20-programmer teams. If you have two programmers and a three-month schedule, you might not even have enough resources to read the manuals and install the tool. If you are willing to bite the bullet, you might eventually find that these tools help you build complex applications with some client-side software. If you aren't willing to bite the bullet, the other end of this spectrum is populated by "litely augmented HTML for idiots" systems. These are the most annoying Web tools because the developers invariably leave out things that you desperately need and, because their litely augmented HTML isn't a general-purpose programming language, you can't build what you need yourself.
AOLserver
 All of the sites that I build these days are done with AOLserver, which has been tested at more than 20,000 production sites since May 1995 (when it was called "NaviServer"). I have personally used AOLserver for more than 100 popular RDBMS-backed services (together they are responding to about 400 requests/second as I'm writing this sentence). AOLserver provides the following mechanisms for generating dynamic pages:
All of the sites that I build these days are done with AOLserver, which has been tested at more than 20,000 production sites since May 1995 (when it was called "NaviServer"). I have personally used AOLserver for more than 100 popular RDBMS-backed services (together they are responding to about 400 requests/second as I'm writing this sentence). AOLserver provides the following mechanisms for generating dynamic pages:- CGI, mostly good for using packaged software or supporting legacy apps
- Java Servlets
- a gateway to ATG's Dynamo system (Java embedded in HTML pages)
- AOLserver Dynamic Pages (ADP; Tcl embedded in HTML pages)
- "*.tcl" Tcl procedures that are sourced by the server each time a URL is requested
- Tcl procedures that you can register to arbitrary URLs, loaded at server startup and after explicitly re-initializing Tcl
- Tcl procedures that you can register to run before or after serving particular URLs
- C functions loaded into the server at startup time
I personally have never needed to use the C API and don't really want to run the attendant risk that an error in my little program will crash the entire Aolserver. The AOL folks swear that their thousands of novice internal developers find the gentle-slope programming of ADPs vastly more useful than the .tcl pages. I personally prefer the .tcl pages for most of my applications. My text editor (Emacs) has a convenient mode for editing Tcl but I'd have to write one for editing ADP pages. I don't really like the software development cycle of "sourced at startup" Tcl but I use it for applications like my comment server where I want db-backed URLs that look like "/com/philg/foobar.html" ("philg" and "foobar.html" are actually arguments to a procedure). These are very useful when you want a site to be dynamic and yet indexed by search engines that turn their back on "CGI-like" URLs. I've used the filter system to check cookie headers for authorization information and grope around in the RDBMS before instructing AOLserver to proceed either with serving a static page or with serving a login page.
You can build manageable complex systems in AOLserver by building a large library of Tcl procedures that are called by ADP or .tcl pages. If that isn't sufficient, you can write additional C modules and load them in at run-time.
AOLserver has its shortcomings, the first of which is that there is no support for sessions or session variables. This makes it more painful to implement things like shopping carts or areas in which users must authenticate themselves. Since I've always had an RDBMS in the background, I've never really wanted to have my Web server manage session state. I just use a few lines of Tcl code to read and write IDs in magic cookies.
The second shortcoming of AOLserver is that, though it started life as a commercial product (NaviServer), the current development focus is internal AOL consumption. This is good because it means you can be absolutely sure that the software works; it is the cornerstone of AOL's effort to convert their 11 million-user service to standard Web protocols. This is bad because it means that AOL is only investing in things that are useful for that conversion effort. Thus there aren't any new versions for Windows NT. I've found the AOLserver development team to be much more responsive to bug reports than any of the other vendors on which I rely. However, they've gone out of the handholding business. If you want support, you'll have to get it for free from the developer's mailing list or purchase it from a third-party (coincidentally, my own company is an authorized AOLserver support provider: http://www.arsdigita.com/aolserver-support.html).
You can test out AOLserver right now by visiting www.aol.com, one of the world's most heavily accessed Web sites. Virtually the entire site consists of dynamically evaluated ADP pages.
Apache

Ex Apache semper aliquid novi"Out of Apache, there is always something new."
-- Pliny the Hacker, Historia Digitalis, II, viii, 42, c. AD 77
The folks who wrote Apache weren't particularly interested in or experienced with relational database management systems. However, they gave away their source code and hence people who were RDBMS wizards have given us a constant stream of modules that, taken together, provide virtually all of the AOLserver goodies. By cobbling together code from modules.apache.org, a publisher can have a server that
- authenticates from a relational database
- runs scripting languages without forking
- pools database connections
- serves HTML with an embedded scripting language
Personally, I don't use Apache. I have a big library of AOLserver code that works reliably. I don't want to look at someone else's C code unless I absolutely have to.
Microsoft Active Server Pages
 Active Server Pages (ASP) are a "gentle slope" Web scripting system. An HTML document is a legal ASP page. By adding a few special characters, you can escape into Visual Basic, JavaScript, or other languages such as Perl (via plug-ins). If you edit an ASP page, you can test the new version simply by reloading it from a browser. You don't have to compile it or manually reload it into Internet Information Server (IIS). Microsoft claims that IIS does "automatic database connection pooling". You ought to be able to use almost any RDBMS with ASP and all the communication is done via ODBC (see below) so that you won't have to change your code too much to move from Solid to Sybase, for example.
Active Server Pages (ASP) are a "gentle slope" Web scripting system. An HTML document is a legal ASP page. By adding a few special characters, you can escape into Visual Basic, JavaScript, or other languages such as Perl (via plug-ins). If you edit an ASP page, you can test the new version simply by reloading it from a browser. You don't have to compile it or manually reload it into Internet Information Server (IIS). Microsoft claims that IIS does "automatic database connection pooling". You ought to be able to use almost any RDBMS with ASP and all the communication is done via ODBC (see below) so that you won't have to change your code too much to move from Solid to Sybase, for example.
ASPs can invoke more or less any of the services of a Windows NT box via Microsoft's proprietary COM, DCOM, and ActiveX systems. The downside of all of this is that you're stuck with NT forever and won't be able to port to a Unix system if your service outgrows NT. Microsoft maintains some reasonably clear pages on ASP at http://www.microsoft.com/iis/.
Don't Switch
 You can build a working Web site in AOLserver, Apache, or IIS/ASP. If you read an advertisement for what sounds like a superior product, ignore it. However superior this new product is, be sure that it will probably be a mistake to switch. Once you build up a library of software and expertise in Tool X, you're better off ignoring Tools Y and Z for at least a few years. You know all of the bugs and pitfalls of Tool X. All you know about Tool Y and Z is how great the hype sounds. Being out of date is unfashionable, but so is having a down Web server, which is what most of the leading edgers will have.
You can build a working Web site in AOLserver, Apache, or IIS/ASP. If you read an advertisement for what sounds like a superior product, ignore it. However superior this new product is, be sure that it will probably be a mistake to switch. Once you build up a library of software and expertise in Tool X, you're better off ignoring Tools Y and Z for at least a few years. You know all of the bugs and pitfalls of Tool X. All you know about Tool Y and Z is how great the hype sounds. Being out of date is unfashionable, but so is having a down Web server, which is what most of the leading edgers will have.
How much can it cost you to be out of date? Amazon.com has a market capitalization of $5.75 billion (August 10, 1998). They built their site with compiled C CGI scripts connecting to a relational database. You could not pick a tool with a less convenient development cycle. You could not pick a tool with lower performance (forking CGI then opening a connection to the RDBMS). They worked around the slow development cycle by hiring very talented programmers. They worked around the inefficiencies of CGI by purchasing massive Unix boxes ten times larger than necessary. Wasteful? Sure. But insignificant compared to the value of the company that they built by focusing on the application and not fighting bugs in some award-winning Web connectivity tool programmed by idiots and tested by no one.
Things that I left out and Why
 Netscape is unique in that they offer a full selection of the worst ideas in server-side Web programming. In May of 1997, I looked at Netscape's server products and plans and wrote the following to a friend:
Netscape is unique in that they offer a full selection of the worst ideas in server-side Web programming. In May of 1997, I looked at Netscape's server products and plans and wrote the following to a friend:"Netscape would be out of the server tools business tomorrow if Microsoft ported IIS/ASP to Unix and/or if NT were more reliable and easier to maintain remotely."Since then they've acquired Kiva and renamed it "Netscape Application Server". A friend of mine runs a Web server complex with 15 Unix boxes, multiple firewalls, multiple RDBMS installations, and dozens of Web sites containing custom software. His number one daily headache and source of unreliability? Netscape Application Server.
Nobody has anything bad to say about Allaire's Cold Fusion but I can't see that it offers any capabilities beyond what you get with Microsoft's ASP. History has not been kind to people who compete against the Microsoft monopoly, particularly those whose products aren't dramatically better.
I used to take delight in lampooning the ideas of the RDBMS vendors. But, since they never even learned enough about the Internet to understand why they were being ridiculed, it stopped being fun. The prevailing wisdom in Silicon Valley is that most companies have only one good idea. Microsoft's idea was to make desktop apps. They've made a reasonably good suite of desktop apps and inflicted misery on the world with virtually everything else they've brought to market (most of which started out as some other company's product, e.g., SQL Server was Sybase, Internet Explorer was NCSA Mosaic, DOS was Tim Paterson's 86-DOS). Netscape's idea was to make a browser. They made a great browser and pathetic server-side stuff. The RDBMS vendors' idea was to copy the System R relational database developed by IBM's San Jose research lab. They all built great copies of IBM's RDBMS server and implementations of IBM's SQL language. Generally everything else they build is shockingly bad, from documentation to development tools to administration tools.
Bring in 'Da Noise, Bring in 'Da Junk
 Now that everything is connected, maybe you don't want to talk to your RDBMS through your Web server. You may want to use standard spreadsheet-like tools. There may even be a place for, dare I admit it, junkware/middleware. First a little context.
Now that everything is connected, maybe you don't want to talk to your RDBMS through your Web server. You may want to use standard spreadsheet-like tools. There may even be a place for, dare I admit it, junkware/middleware. First a little context.
An RDBMS-backed Web site is updated by thousands of users "out there" and a handful of people "back here." The users "out there" participate in a small number of structured transactions, for each of which it is practical to write a series of Web forms. The people "back here" have less predictable requirements. They might need to fix a typo in a magazine title stored in the database, for example, or delete a bunch of half-completed records because the forms-processing code wasn't as good about checking for errors as it should have been.
Every RDBMS-backed Web site should have a set of admin pages. These provide convenient access for the webmasters when they want to do things like purge stale threads from discussion groups. But unless you are clairvoyant and can anticipate webmaster needs two years from now or you want to spend the rest of your life writing admin pages that only a couple of coworkers will see, it is probably worth coming up with a way for webmasters to maintain the data in the RDBMS without your help.
Canned Web Server Admin Pages
Some RDBMS/Web tools provide fairly general access to the database right from a Web browser. AOLserver, for example, provide some clunky tools that let the webmaster browse and edit tables. These won't work, though, if you need to do JOINs to see your data, as you will if your data model holds user e-mail addresses and user phone numbers in separate tables. Also, if you would like the webmasters to do things in structured ways, involving updates to several tables, then these kinds of standardized tools won't work.Spreadsheet-like Access
Fortunately, the RDBMS predates the Web. There is a whole class of programs that will make the data in the database look like a spreadsheet. This isn't all that difficult because, as discussed in the previous chapter, a relational database really is just a collection of spreadsheet tables. A spreadsheet-like program can make it very convenient to make small, unanticipated changes. Microsoft Excel and Microsoft Access can both be used to view and update RDBMS data in a spreadsheet-like manner.Forms Builders
If you need more structure and user interface, then you might want to consider the junkware/middleware tools discussed in "Sites that are really databases". There are literally thousands of these tools for Macintosh and Windows machines that purport to save you from the twin horrors of typing SQL and programming user interface code in C. With middleware/junkware, it is easy to build forms by example and wire them to RDBMS tables. These forms are then intended to be used by, say, telephone sales operators typing at Windows boxes. If you're going to go to the trouble of installing a Web server and Web browsers on all the user machines, you'll probably just want to make HTML forms and server-side scripts to process them. Some of the people who sell these "easy forms for SQL" programs have realized this as well and provide an option to "save as a bunch of HTML and Web scripts." The plus side of these forms packages is that they often make it easy to add a lot of input validation. The down side of forms packages is that the look and user interface might be rather clunky and standardized. You probably won't win any awards if you generate your public pages this way.Connecting
 Both spreadsheet-like database editors and the applications generated by "easy forms" systems connect directly to the RDBMS from a PC or a Macintosh. This probably means that you'll need additional user licenses for your RDBMS, one for each programmer or Web content maintainer. In the bad old days, if you were using a forms building package supplied by, say, Oracle then the applications generated would get compiled with the Oracle C library and would connect directly to Oracle. These applications wouldn't work with any other brand of database management system. If you'd bought any third-party software packages, they'd also talk directly to Oracle using Oracle protocols. Suppose you installed a huge data entry system, then decided that you'd like the same operators to be able to work with another division's relational database. You typed the foreign division server's IP address and port numbers into your configuration files and tried to connect. Oops. It seems that the other division had chosen Sybase. It would have cost you hundreds of thousands of dollars to port your forms specifications over to some product that would generate applications compiled with the Sybase C library.
Both spreadsheet-like database editors and the applications generated by "easy forms" systems connect directly to the RDBMS from a PC or a Macintosh. This probably means that you'll need additional user licenses for your RDBMS, one for each programmer or Web content maintainer. In the bad old days, if you were using a forms building package supplied by, say, Oracle then the applications generated would get compiled with the Oracle C library and would connect directly to Oracle. These applications wouldn't work with any other brand of database management system. If you'd bought any third-party software packages, they'd also talk directly to Oracle using Oracle protocols. Suppose you installed a huge data entry system, then decided that you'd like the same operators to be able to work with another division's relational database. You typed the foreign division server's IP address and port numbers into your configuration files and tried to connect. Oops. It seems that the other division had chosen Sybase. It would have cost you hundreds of thousands of dollars to port your forms specifications over to some product that would generate applications compiled with the Sybase C library. From your perspective, Oracle and Sybase were interchangeable. Clients put SQL in; clients get data out. Why should you have to care about differences in their C libraries? Well, Microsoft had the same thought about five years ago and came up with an abstraction barrier between application code and databases called ODBC. Well-defined abstraction barriers have been the most powerful means of controlling software complexity ever since the 1950s. An abstraction barrier isolates different levels and portions of a software system. In a programming language like Lisp, you don't have to know how lists are represented. The language itself presents an abstraction barrier of public functions for creating lists and then extracting their elements. The details are hidden and the language implementers are therefore free to change the implementation in future releases because there is no way for you to depend on the details. Very badly engineered products, like DOS or Windows, have poorly defined abstraction barriers. That means that almost every useful application program written for DOS or Windows depends intimately on the details of those operating systems. It means more work for Microsoft programmers because they can't clean up the guts of the system, but paradoxically a monopoly software supplier can make more money if its products are badly engineered in this way. If every program a user has bought requires specific internal structures in your operating system, there isn't too much danger of the user switching operating systems.
From your perspective, Oracle and Sybase were interchangeable. Clients put SQL in; clients get data out. Why should you have to care about differences in their C libraries? Well, Microsoft had the same thought about five years ago and came up with an abstraction barrier between application code and databases called ODBC. Well-defined abstraction barriers have been the most powerful means of controlling software complexity ever since the 1950s. An abstraction barrier isolates different levels and portions of a software system. In a programming language like Lisp, you don't have to know how lists are represented. The language itself presents an abstraction barrier of public functions for creating lists and then extracting their elements. The details are hidden and the language implementers are therefore free to change the implementation in future releases because there is no way for you to depend on the details. Very badly engineered products, like DOS or Windows, have poorly defined abstraction barriers. That means that almost every useful application program written for DOS or Windows depends intimately on the details of those operating systems. It means more work for Microsoft programmers because they can't clean up the guts of the system, but paradoxically a monopoly software supplier can make more money if its products are badly engineered in this way. If every program a user has bought requires specific internal structures in your operating system, there isn't too much danger of the user switching operating systems.
Relational databases per se were engineered by IBM with a wonderful abstraction barrier: Structured Query Language (SQL). The whole raison d'être of SQL is that application programs shouldn't have to be aware of how the database management system is laying out records. In some ways, IBM did a great job. Just ask Oracle. They were able to take away most of the market from IBM. Even when Oracle was tiny, their customers knew that they could safely invest in developing SQL applications. After all, if Oracle tanked or the product didn't work, they could just switch over to an RDBMS from IBM.
Unfortunately, IBM didn't quite finish the job. They didn't say whether or not the database had to have a client/server architecture and run across a network. They didn't say exactly what sequence of bytes would constitute a request for a new connection. They didn't say how the bytes of the SQL should be shipped across or the data shipped back. They didn't say how a client would note that it only expected to receive one row back or how a client would say, "I don't want to read any more rows from that last SELECT." So the various vendors developed their own ways of doing these things and wrote libraries of functions that applications programmers could call when they wanted their COBOL, Fortran, or C program to access the database.
ODBC
 It fell to Microsoft to lay down a standard abstraction barrier in January 1993: Open Database Connectivity (ODBC). Then companies like Intersolv (www.intersolv.com) released ODBC drivers. These are programs that run on the same computer as the would-be database client, usually a PC. When the telephone operator's forms application wants to get some data, it doesn't connect directly to Oracle. Instead, it calls the ODBC driver which makes the Oracle connection. In theory, switching over to Sybase is as easy as installing the ODBC driver for Sybase. Client programs have two options for issuing SQL through ODBC. If the client program uses "ODBC SQL" then ODBC will abstract away the minor but annoying differences in SQL syntax that have crept into various products. If the client program wants to use a special feature of a particular RDBMS like Oracle Context, then it can ask ODBC to pass the SQL directly to the database management system. Finally, ODBC supposedly allows access even to primitive flat-file databases like FoxPro and dBASE.
It fell to Microsoft to lay down a standard abstraction barrier in January 1993: Open Database Connectivity (ODBC). Then companies like Intersolv (www.intersolv.com) released ODBC drivers. These are programs that run on the same computer as the would-be database client, usually a PC. When the telephone operator's forms application wants to get some data, it doesn't connect directly to Oracle. Instead, it calls the ODBC driver which makes the Oracle connection. In theory, switching over to Sybase is as easy as installing the ODBC driver for Sybase. Client programs have two options for issuing SQL through ODBC. If the client program uses "ODBC SQL" then ODBC will abstract away the minor but annoying differences in SQL syntax that have crept into various products. If the client program wants to use a special feature of a particular RDBMS like Oracle Context, then it can ask ODBC to pass the SQL directly to the database management system. Finally, ODBC supposedly allows access even to primitive flat-file databases like FoxPro and dBASE.
You'd expect programs like Microsoft Access to be able to talk via ODBC to various and sundry databases. However, this flexibility has become so important that even vendors like Oracle and Informix have started to incorporate ODBC interfaces in their fancy client programs. Thus you can use an Oracle-brand client program to connect to an Informix or Sybase RDBMS server.
The point here is not that you need to rush out to set up all the database client development tools that they use at Citibank. Just keep in mind that your Web server doesn't have to be your only RDBMS client.
Summary
- It takes a long time to fork a CGI process and watch it connect to an RDBMS server; fast Web sites are built with already-connected database clients.
- Running a relational database is a security risk; you may not want to allow anyone on the Internet to connect directly as a client to your RDBMS server.
- Writing the HTML/SQL bridge code in Perl, Tcl, or Visual Basic is straightforward.
- Encapsulating SQL queries in Java, CORBA, or COM objects will make your site slower, less reliable, more expensive to develop, and more difficult to debug or extend.
- Most Web/RDBMS software does not perform as advertised and will shackle you to an incompetent and uncaring vendor; just say no to middleware (becoming my personal "Delenda est Carthago").
- One of the nice things about using an RDBMS, the standard tool of business data processing since the late 1970s, is that you can just say yes to off-the-shelf software packages if you need to do something standard behind-the-scenes of your Web site.
the best services to build a two-tier application
The notion of a scalable, on-demand, pay-as-you go cloud infrastructure tends to be easy understood by the majority of today’s IT specialists. However, in order to fully reap the benefits from hosting solutions in the cloud you will have to rethink traditional ‘on-premises’ design approaches. This should happen for a variety of reasons with the most prominent ones the design-for-costs or the adoption of a design-for-failure approach.
This is the first of a series of posts in which we will introduce you to a variety of entry-level AWS services on the example of architecting on AWS to build a common two-tier application deployment (e.g. mod_php LAMP). We will use the architecture to explain common infrastructure and application design patterns pertaining to cloud infrastructure.
To start things off we provide you with a high level overview of the system and a brief description of the utilised services.

This is the first of a series of posts in which we will introduce you to a variety of entry-level AWS services on the example of architecting on AWS to build a common two-tier application deployment (e.g. mod_php LAMP). We will use the architecture to explain common infrastructure and application design patterns pertaining to cloud infrastructure.
To start things off we provide you with a high level overview of the system and a brief description of the utilised services.

Virtual Private Cloud (VPC)
The VPC allows you to deploy services into segmented networks to reduce the vulnerability of your services to malicious attacks from the internet. Separating the network into public and private subnets allows you to safeguard the data tier behind a firewall and to only connect the web tier directly to the public internet. The VPC service provides flexible configuration options for routing and traffic management rules. Use an Internet Gateway to enabls connectivity to the Internet for resources that are deployed within public subnets.
Redundancy
In our reference design we have spread all resources across two availability zones (AZ) to provide for redundancy and resilience to cater for unexpected outages or scheduled system maintenance. As such, each availability zone is hosting at least one instance per service, except for services that are redundant by design (e.g. Simple Storage Service, Elastic Load Balancer, Rote 53, etc.).
Web tier
Our web tier consists of two web servers (one in each availability zone) that are deployed on Elastic Compute Cloud (EC2) instances. We balance external traffic to the servers using Elastic Load Balancers (ELB). Dynamic scaling policies allow you to elastically scale the environment in adding or removing web instances to the auto scaling group. Amazon Cloud Watch allows us to monitor demand on our environment and triggers scaling events using Cloud Watch alarms.
Database tier
Amazon’s managed Relational Database Service (RDS) provides the relational (MySQL, MS SQL or Oracle) environment for this solution. In this reference design it is established as multi-AZ deployment. The multi-AZ deployment includes a standby RDS instance in the second availability zone, which provides us with increased availability and durability for the database service in synchronously replicating all data to the standby instance.
Optionally we can also provision read replicas to reduce the demand on the master database. To optimise costs, our initial deployment may only include the master and slave RDS instances, with additional read replicas created in each AZ as dictated by the demand.
Optionally we can also provision read replicas to reduce the demand on the master database. To optimise costs, our initial deployment may only include the master and slave RDS instances, with additional read replicas created in each AZ as dictated by the demand.
Object store
Our file objects are stored in Amazon’s Simple Storage Service (S3). Objects within S3 are managed in buckets, which provide virtually unlimited storage capacity. Object Lifecycle Management within an S3 bucket allows us to archive (transition) data to the more cost effective Amazon Glacier service and/or the removal (expiration) of objects from the storage service based on policies.
Latency and user experience
For minimised latency and an enhanced user experience for our world-wide user base, we utilise Amazon’s CloudFront content distribution network. CloudFront maintains a large number of edge locations across the globe. An edge location acts like a massive cache for web and streaming content.
Infrastructure management, monitoring and access control
Any AWS account should be secured using Amazon’s Identity and Access Management (IAM). IAM allows for the creation of users, groups and permissions to provide granular, role based access control over all resources hosted within AWS.
The provisioning of above solution to the regions is achieved in using Amazon CloudFormation. CloudFormation supports the provisioning and management of AWS services and resources using scriptable templates. Once created, CloudFormation also updates the provisioned environment based on changes made to the ‘scripted infrastructure definition’.
We use the Route 53 domain name service for the registration and management of our Internet domain.
In summary, we have introduced you to a variety of AWS services, each of which has been chosen to address one or multiple specific concern in regards to functional and non-functional requirements of the overall system.
The provisioning of above solution to the regions is achieved in using Amazon CloudFormation. CloudFormation supports the provisioning and management of AWS services and resources using scriptable templates. Once created, CloudFormation also updates the provisioned environment based on changes made to the ‘scripted infrastructure definition’.
We use the Route 53 domain name service for the registration and management of our Internet domain.
In summary, we have introduced you to a variety of AWS services, each of which has been chosen to address one or multiple specific concern in regards to functional and non-functional requirements of the overall system.
Serverless Continuous Delivery

Why Cloud Computing?
Energy use and Ecological Impact of Large scale Data Centres
The Energy use and Ecological Impact of Large scale Data Centres can be described by analysis of the concept of Energy proportion system.
The Energy use and Ecological Impact of Large scale Data Centres can be described by analysis of the concept of Energy proportion system.

50
|
100
|
0
|
10
|
50
|
90
|
Typical Operating Region
|
Percentage of System Utilization
|
Percentage of Power Usage
|
Power
|
Energy Efficiency
|
The above diagram shows power requirements scale linearly with the load, the energy efficiency of a computing system is not a linear function of the load; even when idle, a system may use 50% of the power corresponding to the full load. Data collected over a long period of time shows that the typical operating region for the servers at a data centre is from about 10% to 50% of the load.
This is a very important concept of resource management in a cloud environment in which load is concentrated in a subset of servers and rest of the servers are kept in standby mode whenever possible. An energy proportional system consumes on power when idle, very little power under light load and gradually more power as load increases.
An ideal energy proportion system is always operating at 100% efficiency. Operating efficiency of a system is captured by an expression of performance per watt power. Energy proportion Network consumes energy proportional to their communication load. An example of energy proportion network is infiniband.
Strategy to reduce energy consumption is to concentrate the load on a small no. Of disk and allow others to operate in low power mode.
Another technique is based on data migration. The system uses data storage in virtual nodes managed with distributed hash table, the migration is controlled by two algorithms, a short term optimization algorithm used for gathering or spreading virtual nodes according to the daily variation of workload so that the number of active physical node is reduced to a minimum and a long term optimization algorithm, used for coping with changes in the popularity of data over a longer period i.e. a week.
Dynamic resource provisioning is also necessary to minimize power consumption. Two critical issues related to it are i) amount of resource allocated to each application ii) placement of individual work load.
Cloud Interoperability
Since the internet is a network of network, so Inter cloud seems plausible.
A network offers high level services for transportation of digital information from a source or a host outside the network to destination, another host or another network that can deliver the information to its final destination. This transportation of information is possible because there is agreement on a) how to uniquely indentify the source and destination of the information b)how to navigate through a maze of networks and c) how to actually transport the data between a source and a destination. The three elements on which agreement is in place are IP address, IP protocol, and transportation protocol such as TCP/UDP.
In case of cloud there are no standards for storage or processing, the clouds have different delivery models which are not only large but also open. But following the lines of internet cloud interoperability seems feasible. Standards are required for items such as naming, addressing, identity, trust, presence, message, multicast, time, means to transfer, store and process information etc. An inter cloud would require the development of an ontology for cloud computing and then each service provider would have to create a description of all resources and services using this ontology. Each cloud would then require an interface which may be termed as an Inter cloud Exchange to translate the common language describing all object and action included in a request originating from another cloud in terms of internal objects and action.

The above diagram show communication among disparate clouds
The Open Grid Forum has created a working group to standardize such an interface called as the Open Cloud Computing Interface (OCCI). The OCCI has adopted resource oriented architecture (ROA) to represent key components comprising cloud infrastructure service. Each resource identified by a URI (Unique resource identifier) can have multiple representations that may or may not be hypertext. The OCCI working group plans to map API to several formats. Thus a single URI entry point defines an OCCI interface.
The API implements CRUD operations: Create, Retrieve, update and delete. Each is mapped to HTTP POST, GET, PUT and DELETE respectively. OCCI provides the capabilities to govern the definition, creation, deployment, operation and retirement of infrastructure services.
Cloud clients can invoke a new application stack, manage its life cycle and manage the resources that it uses using the OCCI. The SINA association has established a working group to address the standardization of cloud storage. The cloud Management Data Interface (CDMI) serves the purpose. In CDMI the storage space exposed by various type of interface is abstracted using the notion of a container. The container also serves as a grouping of the data storage in the storage space and also forms a point of control for applying data services in aggregation. The CDMI provider data object interface with CRUD semantics and can also be used to manage containers exported for use by cloud infrastructure.

The above diagram shows OCCI and CDMI in an integrated cloud environment
To achieve interoperability, CDMI provides a type of export that contains information obtained via the OCCI interface. In addition, OCCI provide a type of storage that corresponds to exported CDMI containers.
Cloud Storage Diversity and vendor lock in
There are several risk involved when a large organization relies solely on a single cloud provider.
A solution to guarding against vendor lock is to replicate the data into multiple cloud service providers. But this straight forward replication is costly and poses technical challenges at the same time. The overhead to maintain data consistency could drastically affect the performance of the virtual storage system consisting of multiple full replicas of the organization’s data spread over multiple vendors.
Another solution is based on extension of design principle of a RAID-5 system used for reliable data storage. A RAID 5 system uses block level striping with distributed parity over a disk array. The disk controller distributes the sequential block of data to the physical disk and computes a parity block by bitwise XORing the data block. The parity block is written on a different disk for each file when all parity is written to a dedicated disk as in RAID 4. This technique allows us to recover data after a single disk is lost.

The above diagram show a RAID 5 controller. If disk 2 is lost file 3 still has all its blocks and the missing blocks can be for by applying XOR operation (eg: a2=a1XORapXORa3)
The same process can be applied to detect and correct error in a single block. We can replicate this system in cloud, data may be stripped across four clouds, the proxy cloud provides transparent to data. Proxy carries out function of the RAID controller. The RADI controller allows multiple accesses to data. For example block a1, a2, a3 can be read and written concurrently.

The above diagram shows the concept of RAID 5 applied in Cloud to avoid vendor lock in
Proxy carries out function of RADI controller as well as authentication and other security related functions. The proxy ensures before and after atomicity as well as all or nothing atomicity for data access. The proxy buffers the data, possible converts the data manipulation command, optimizes the data access. For example aggregates multiple write operation, convert data to formats specific to each cloud and so on. This Model is used by Amazon. Performance penalty due to proxy overhead is minor and cost increase is also minor.
Case Study: Amzone Cloud Storage
Amazon Web service (AWS) 2000 release based on IaaS Delivery model:
In this model cloud service provider offer an infrastructure consisting of compute and storage servers interconnected by high speed network and supports, a set of services to access theses resources. An application developer is responsible to install application on a platform of his hoice and to manage the sources provided by Amazon

Cloud Watch
|
AWS Management Console
|
S3
|
EBS
|
Simple DB
|
EC2 instances on various OS
|
SQS(Simple queue Service)
|
EC 2 instance
|
Virtual Private Cloud
|
Auto Scaling
|
The diagram shows the Services offered by AWS are accessible from the AWS Management Console.
Applications running under a variety of operating system can be launched using EC2. Multiple EC2 instances can communicate using SQS. Several storage services are available, S3, SimpleDB, and EBS. The Cloud Watch supports performance monitoring and the Auto Scaling supports elastic resource management. The Virtual Private Cloud allows direct migration of parallel applications
Elastics compute cloud (EC2) is a web service with the simple interface for launching instances of an application under several operating systems. An instance is created from a predefined Amazon Machine Image (AMI) digitally signed and stored in S3 or from a user defined image. The image includes the operating system, the run time environment, the libraries and the application desired by the user. AMI create an exact copy of original image but without configuration dependent information such as host name of MAC address. User can 1) launch an instance from an existing AMI image and terminate an instance 2) start and stop an instance 3) create a new image 4) add tags to identify an image 5) reboot an instance. EC2 is based on Xen Virtualization strategy. In each EC2 virtual machine or instance functions as a virtual private server. An instance specifies the maximum amount of resources available to an application, the interface for that instance, as well as, cost per hour. A user can interact with EC2 using a set of SOAP message and list of available AMI images, boot an instance from an image, terminate an image, display the running instances of a user, display console output and so on. The user has root access to each instance in the elastic and secure computing environment of EC2. The instance can be placed in multiple locations.
EC2 allows the import of virtual machine images from the user environment to an instance through a facility called VM import. It also automatically distributes the incoming application traffic among multiple instances using elastic load balancing facility. EC2 associates an elastic IP address with an account; this mechanism allow a user to mask the failure of an instance and remap a public IP address to any instance of the account without the need to interact with the software support.
Simple Storage System (S3) is a storage service design to store large object. It supports minimal set of function: write, read, delete. S3 allows application to handle an unlimited number of object ranging in size from 1 byte to five terabyte. An object is stored in a bucket and retrieved via unique developer assigned key. A bucket can be stored in a region selected by the user. S3 maintains for each object; the name, modification time, an access control list and up to 4 kilobyte of user defined metadata. The object names are global. Authentication mechanism ensures that data is kept secure and object can be made public and write can be granted to other user.
S3 support PUT, GET and DELET primitives to manipulate object but doesn’t’ support primitives to copy, to rename, or to move an object from one bucket to another. Appending an object requires a read followed by a write of the entire object. S3 computes (MD5) of every object written and returned in a field called a ETag. A user is expected to compute the MD5 of an object stored or written and compare this with the ETag; if the values do not match, then the object was corrupted during transmission or storage.
The Amazon S3 SLA guarantees reliability. S3 uses standards based REST and SOAP interfaces, the default download protocol is HTTP, but Bittorrent protocol interface is also provide to lower cost high scale distribution.
Elastic Block Store (EBS) provides persistent block level storage volume for use with Amazon EC2 instances. A volume appears to an application as a raw, unformatted and reliable physical disk. The size of the storage volume ranges from 1 Gigabyte to 1 Terabyte. The volumes are grouped together in availability zones and are automatically replicated in each zone. An EC2 instance may mount multiple volumes but a volume cannot be shared among multiple instances. The EBS supports the creation of snapshots of the volume attached to an instance and then uses them to restart an instance. The storage strategy provided by EBS is evitable for databases application, file system, and application using raw data devices.
Simple DB is non relational data store that allows developer to store and query data item via web services requests. It supports store and query function traditionally provided only by relational databases. Simple DB create multiple geographically distributed copies of each data item and support high performance web application, at the same time it manages automatically the infrastructure provisioning hardware and software maintenance and indexing of data item and performance tuning.
Simple Queue Service (SQS) is a hosted message query. SQS is a system for supporting automated workflows. It allows multiple Amazon EC2 instances to coordinate their activities by sending and receiving SQS message. Any computer connected to the internet can add or read message without using any installed software or special firewall configuration.
Application using SQS can run independently and synchronously and do not need to be developed with same technologies. A received message is ‘locked’ during processing. If processing fails the lock expires and the message is available again. The time out for locking can be changed dynamically via Change Message Visibility operation. Developer can access SQS through standard based SOAP and query interfaces. Queries can be shared with other AWS accounts. Query sharing can also be restricted by IP address and time of day.
Cloud Watch is monitoring infrastructure used by application developers, users and system administrator to collect and track metrics important for optimizing the performance of application and for increasing the efficiency of resource utilization. Without installing software a user can monitor approximately a dozen pre selected metrics and then view graphs and statistics for these metrics. Basic monitoring is free, detailed monitoring is subjected to charges
Virtual private cloud (VPC) provides a bridge between the existing IT infrastructure of an organization and the AWS cloud; the existing infrastructure is connected via a virtual private network (VPN) to a set of isolated AWS compute resources. VPC allows existing management capabilities such as security services, firewall and intrusion detection system to operate seamlessly within the cloud.
Auto scaling exploits cloud elasticity and provides automatic scaling EC2 instances. The service support grouping of instance, monitoring of instances in a group, and defining triggers, pair of cloud watch alarms and policies, which allows the size of the group to be scaled up or down.1
An auto scaling group consist of a set of instances described in a statics faction by launch configuration. When a group scales up new instance are started by using parameters of run instance EC2 call provide by launch configuration. When the group scales down the instance with older launch configuration are terminate first. The monitoring function of auto scaling services carries out health checks to ensure the specified policies. For example a user may specify a health check for elastic load balancing and auto scaling will terminate an instance exhibiting a low performance and start a new one. Trigger uses cloud watch alarms to detect event and then initiate specific action; for example a trigger cloud detect when the CPU utilization of the instances in the group goes above 90% and then scales up the group by starting new instances.
AWS services:
1. Elastic Map Reduce (EMR): a service supporting processing a large amount of data.
2. Simple work flow (SWF) service: for work flow management, allows scheduling, management of dependencies and co-ordination of multiple EC2 instances.
3. Elastic Cache: A service enabling web application to retrieve data from a managed in memory caching system rather than much slower disk based database
4. Dynamo DB: a scalable and low latency fully managed no SQL database service.
5. Cloud Front: a web service for content delivery.
6. Elastic Load Balancer: Automatically distributes the incoming requests across multiple instances of the application.
7. Elastic Bean Stalk: uses/ interacts with the services of other AWS services and handle automatically the deployment, capacity provisioning, load balancing, auto scaling, and application monitoring function.
8. Cloud formation: allows creation of stack describing the infrastructure of an application
The AWS SLA allows the cloud service provider to terminate service to any customer at any time for any reason and contains a covenant not to sue Amazon or its affiliates for any damage that might arise out of use of AWS.
Users have several choices to interact and manage AWS resources:
1. The AWS management console available at http://aws.amazon.om/console/;
2. Command link tools (aws.amazon.com/developer tools)
3. AWS SDK libraries and tool kits for java , php, c++,object c
4. Raw REST request

Cloud Interconnect
|
NAT
|
Internet
|
S3
|
EBS
|
Simple DB
|
AWS Storage Services
|
SQS
|
Cloud Watch
|
Elastic Cache
|
Cloud Formation
|
Elastic Bean Stalk
|
Elastic LoadBalance
|
Cloud Front
|
AWS Management Console
|
Server Running AWS Service
|
EC 2 Instances
|
EC 2 Instances
|
Compute Servers
|
The above diagram shows AWS shows the configuration of an availability zone supporting AWS services.
Amazon offers cloud services through a network of data centres on several continents. In each region there are several availability zone interconnected by high speed network. Region do not share resources and communicate through the internet.
An availability zone is data center consisting of a large number of servers. A server may run multiple instances, started by one or more user; an instance may run multiple virtual machine or instances, started by one or more users. An instance may use storage service as well as other services provided by AWS. Storage is automatically replicated within a region. S3 buckets are replicated within an availability zone and between the availability zones of a region, while EBS volumes are replicated only within the same availability zone. An instance is a virtual server. The user chooses the region and the availability zone where this virtual server should be placed and also selects from a limited menu of instance type the one which provide the resources, CPU cycles, main memory, secondary storage, communication and IP bandwidth needed by the application. When launched, an instance is provide with a DNS name, this name maps to a private IP address for internal communication within the internal EC2 communication network and a public IP address for communication outside the internal network of Amazon. Example for communication with the user that launches the instance. NAT map external IP address to internal ones. The public IP address assigned for lifetime of an instance and it is returned to pool of available public IP address when the instance is stopped or terminated. An instance can also request for a elastic IP address which is static public IP address and need not be released when the instance is stopped or terminated and must be released when no longer needed. EC2 instance system offers several instances types: Standard instance, High memory instance, High CPU instance, Cluster computing.
Storage as a Service
Let’s start with a real world example to get a clear understanding about it.
Sandeep started Home delivery of pizzas on the order from Customers. He is worried about how to deliver the pizzas on time and how to manage the pizza delivery. He is also concerned about hiring the drivers and keeping the bikes running. But the below scenario makes him worried.
He is a pizza delivery person and not a mechanic - delivery is a distraction. With his limited budget, maintaining the deliveries costs a lot. His business suffers when he can't keep up the deliveries as he has promised to give 20% of deduction on total amount of the bill, whenever the delivery is late. It is difficult for him to estimate about how many bikes are required based on deliveries. Then he came to know about the new kind of Delivery Company of bikes and drivers. He can use the services provided by this company, on as need basis and pay only for what he uses. Now he can depend on that company to handle the deliveries.
A few years later his business expanded to more branches and started with new problems as well. It is difficult for him to maintain all the software’s and data in local servers which costs a lot. His business is constantly running out of storage space and fixing broken servers. Then he came to know about cloud computing, which gives a solution to his problem. Instead of maintaining all the data and software’s at local machines, he can now depend on another company which provides all the features that he requires and are accessible through the Web. At the same time his data is secure, backed up at another location. “This is using Storage as a Service which is one of the delivery models of Cloud Computing”.
Cloud computing means procuring and maintaining software/hardware resources don't have to limit business. Business can grow without worry as Cloud companies have nearly unlimited storage and resources, as well as information is safe because the servers are normally backed up in multiple locations. Sandeep is happy as he is using cloud computing and he pays only for what he uses. If his business grows, then his computing costs will also go high and vice versa.

