


In a process of countdown hours it is necessary to provide data and information that can still be detected to continue the process of the next work and energy concept, especially in the concepts of cyberspace and the real world that move together, especially on proxy walls and fire walls where the data information and communication is lost electronically maybe the initial stage we are still calculating the depth of proxy wells and fire wells in each digital communication information path.
Basic concept Digital filter for clocks work
In signal processing, a digital filter is a system that performs mathematical operations on a sampled, discrete-time signal to reduce or enhance certain aspects of that signal. This is in contrast to the other major type of electronic filter, the analog filter, which is an electronic circuit operating on continuous-time analog signals.
A digital filter system usually consists of an analog-to-digital converter (ADC) to sample the input signal, followed by a microprocessor and some peripheral components such as memory to store data and filter coefficients etc. Finally a digital-to-analog converter to complete the output stage. Program Instructions (software) running on the microprocessor implement the digital filter by performing the necessary mathematical operations on the numbers received from the ADC. In some high performance applications, an FPGA or ASIC is used instead of a general purpose microprocessor, or a specialized digital signal processor (DSP) with specific paralleled architecture for expediting operations such as filtering.
Digital filters may be more expensive than an equivalent analog filter due to their increased complexity, but they make practical many designs that are impractical or impossible as analog filters. Digital filters can often be made very high order, and are often finite impulse response filters which allows for linear phase response. When used in the context of real-time analog systems, digital filters sometimes have problematic latency (the difference in time between the input and the response) due to the associated analog-to-digital and digital-to-analog conversions and anti-aliasing filters, or due to other delays in their implementation.
Digital filters are commonplace and an essential element of everyday electronics such as radios, cellphones, and AV receivers.


Countdown Clocks Bodet,s system
Large LED digital countdown clocks (days, hours, minutes, seconds)
Display the time or count down / count up time in seconds, minutes, hours and days using Bodet's wide range of LED digital countdown clocks dedicated to your environment. Bodet gives you the opportunity to choose the colour and size of your countdown clocks. Our clocks can be installed with various mounting options such as surface mounted, double sided or can be built into a sign or display. Bodet can also offer a Hour / Temperature LED kit to fit inside a sign or display.
Countdown Clocks controlled by wireless remote control
 Bodet's wide range of countdown clocks controlled via remote control enable you to display normal time information and to use the clock as a chronometer or a countdown timer. The wireless control enable to change the features of the clocks easily.
Bodet's wide range of countdown clocks controlled via remote control enable you to display normal time information and to use the clock as a chronometer or a countdown timer. The wireless control enable to change the features of the clocks easily.
The wireless remote control enables you to set the functions that you want from your clock such as: time, count up or down, date, temperature, rate of chlorine, rate of humidity. It also allows you to operate the clock within each function.
HMT & HMS LED digital countdown clocks are available in different sizes and LED colours (red, yellow or white) to fit your requirements.
LED digital clocks controlled by wired timer control unit (hours, minutes and seconds)
Bodet has designed special countdown clocks that can either display the time as a normal digital clock or be used as a chronometer or countdown timer. The clocks will display the information in hours, minutes and seconds to guarantee accurate and precise timing. Bodet's LED digital clocks can also be synchronised with other clocks using one of Bodet's clock systems (wired or wireless).
The timer control unit enables you to switch the clock display between time and countdown and allows you to operate the timer when you are using the countdown function. You can count up or down, record split times and reset the timer from the control unit.
Bodet provides different countdown clocks controlled via a timer control unit so you can choose the clock that will best suit your environment and requirements. Our countdown clocks can also be used in healthcare environments. Synchronised time is crucial for recording key events to ensure patients receive treatment at the correct time and at precise intervals.
- LED clock and timer for indoor installation.
- Precise recording of events. Accurate timing for assessments / procedures.
- Automatic summer / winter changeover.
- Easy to install. Peace of mind with our support contract.
- Style 5 SDV: designed for auction rooms, law courts, amphitheatre, to countdown the speech time or auctions. Red light and buzzer for the end of the count-up or count-down.
- Style 5S Hospital: Mainly used for operating theatres. Stainless steel casing and keypad adapted to cleaning requirements. No interference with other medical equipments.


XO___XO Count Down Timers
Count Down Timers are selected based on the way the organization wants to implement the devices. We offer three countdown timers. Each one of these timers are different in how the count down or count up can be performed. We offer a LED Count Down Timer, Analog Count Down Timer and our PoE Count Down Timer.
The LED Count Down Timer is both a countdown timer and a reliable time display when it is not engaged in a count down or count up function. As a LED Digital Clock it can be part of our 467 MHz wireless clock system. This system functions with a transmitter that broadcast a time code throughout your facility so that all wireless clocks can receive the time daily and display accurate, reliable synchronized time.
The LED timer will receive this time and display it. To initiate a count down or count up the clock comes with a small switch controller. The switch controller is tethered to the clock via a cable and controls the function to learn more please visit Digital LED Countdown Timer
It is perfect for a healthcare environment where a OR count down timer is important for the timing of certain procedures in the operating room. At the same time there is a need to display accurate time.
Our Analog Countdown timer performs basically in the same manner as our LED ones except that the time is in an analog display and the countdown function is accomplished on an LCD display located in the center of the dial face. The clock timer is controlled by a switch. For more information please view the video and information at Analog LCD Countdown timer
The third count down timer we offer is with our IP – PoE LED Digital Clocks. The software is what controls that countdown feature. You can schedule a countdown event to occur a a particular time of day and a particular day or days of the week.
This countdown timer function is used in K-12 schools to count down the time between class changes. The programming is very simple with the PoE software that comes with the LED Digital clocks. Please see the video on PoE Digital Countdown Timer.
examples of analog and digital systems are clocked backwards
Analog Countdown Timers offer convenience and flexibility. Can be located anywhere applicable. 3 button switch control provides simplistic count-up/count-down functionality, and displays Month, Day, Date when not in timer mode.


Dial Options: Additional Custom Logo Designs Available


Features
- Solid, Durable Casing
- Polycarbonate and Glass Lens
- Easily Viewable LCD
- Displays Month, Date, Day
- Count-Up/Count-Down Modes
- Battery Operated (2 D-Cell)
- Automatically Adjust for DST
- Maintenance Free
analog LCD Countdown Timer has a clear easy to view LCD digital panel on the dial face that is controlled by a switch panel. The analog dial face can be either in a 12 hour format or a 24 hour format. The 24 hour format is ideal for hospital environment where time is charted in a 24 hour format.
The combination of this analog clock and timer is available in a 16″ black standard casing or a 13″ brushed aluminum casing. The performance and operation of both styles is identical. The switch controller is separate from the actual clock. It is tethered to the clock with a wire.
The controller has three buttons; set, start and stop. These simple to use buttons will activate the timer. When the timer is not activated the LCD displays the day, date and month. If the timer is activated in the countdown mode the digital display panel will show the remaining time. In the count up mode the digital display will show the elapsed time.
The clock is part of the KRONOsync master clock system. The system is a wireless system and the 467 MHz transmitter is the brains of the system. The transmitter will broadcast the time code throughout a customer’s facilities creating a matrix type coverage area that allows you to install a clock any place any time.
Many customers will mix and match clocks combining other sync clocks with countdown timers or other Innovation Wireless products such as our message boards. With our system you are able to combine both timing and communication products and operate them on the same frequency.
The analog portion of the timer will display accurate time because it receives accurate GPS or NTP from the transmitter. The transmitter’s time source can either be from GPS or from NTP (Network Time Protocol).
Whatever time sources you decide both are easy to install and no maintenance or upkeep is required. The transmitter will broadcast the time code from either time source. The receiver module on the LCD analog timer will pick up the time and the analog portion will display the time.
The LCD panel which displays the countdown or count up information is 1.375″ by 4″ on the 13″ brushed aluminum framed clock and 1.75″ by 5″ on the 16″ ABS framed clock. These LCD panels provide for able viewing from a respectable distance and angle. If you are looking for a software controlled countdown timer we offer this in our IP – POE Communication System.
The one item that you must determine is how far the switch controller will sit with respect to the placement of the clock. It is best to use a typical LAN cable to connect the controller to the clock

Synchronized Time and Communication Systems
Wireless Timekeeping and IP-POE Communications
Clock Synchronization with the powerful KRONOsync Transmitter delivers accurate and reliable time while our Control & Protect IP-POE system offers a complete network communications platform. Our systems are easy to install, maintain and use.
Innovation Wireless Info
Innovation Wireless is an industry leading manufacturer of Synchronized Time and Communications Systems. Our product line includes the KRONOsync clock system and the IP – POE Communication System. Our present day product line is built on a foundation of more than 50 years of experience in the design and manufacturing of clocks, clock parts and components.
By specializing in Wireless Clocks, Bell Systems, Wireless Public Address Systems, Digital Messaging and IP POE Communication Systems we serve markets in Healthcare, Education, and Manufacturing & Government. These products in timekeeping and communications has greatly enhanced and simplified the way schools, hospitals and businesses operate and manage their organizations.
Wireless Clocks
Our wireless clock systems, public address systems and IP-POE systems are simple to use, easy to install and maintain. Our customers include some of the most prestigious companies in the world.
Our selection of clocks both LED Digital Clocks and Analog Clocks enables our customers to improve their operational efficiency. Our user-centric IP-POE software provides customers with an intuitive platform for ease of use.
A large selection of end point devices permit customers to build a communication system that advances the way organizations inform, direct and facilitate communications.
IP-POE Systems
Our engineering and technology expertise has positioned us as an innovator and leader in advanced clock solutions and IP-POE Communication Products. This expertise has positively impacted the way schools, colleges, hospitals and businesses connect and communicate.
Organizations are required more than ever to response to emergencies and our technology increases their effectiveness in accomplishing that objective.
LED Message Boards
Our wireless and IP-POE message boards send notifications messages quickly and easily. They provide customers with an eye catching digital display of communication that complements their voice broadcasts. It enables administrators to take more confidence in the relevance and impact of their messages.
There's never been an easier way to help keep your organization safe and informed. With this in mind our engineers built a simple but intuitive interface. It allows your personnel to execute action during an emergency with accuracy and speed. When an emergency occurs people need information. It is a natural human response in an emergency and our communication systems provides that information.
Our wireless clock systems and message boards make life easier for teachers, administrative and students. Productive use of time is the keystone of great Schools, Universities, Hospitals, Manufacturing and Businesses. In K-12 schools the day revolves around the movement of students from one place of learning to another. Teachers build lesson plans in order to maximize teaching time.
Wireless Bells - Horns
Accurate clocks on the wall that are synchronized with bell schedules create a highly effective learning environment and a efficient manufacturing environment. Click here to learn more about our bell and buzzer solution.
KRONOsync Transmitter
Our high powered KRONOsync transmitter is transforming colleges and universities campuses throughout the United States. These institutions are under ever increasing pressure to improve their education value.
Our wireless clock system provides the means for students and professors to stay on time. Visual and accurate display of time commissions the educational process to work at a high level. Our advanced technology provides complete coverage of a college campus.
The selections of both analog and digital clocks permit our customer to match the look and feel of their institutions. Our sync clocks systems for hospitals increase the accuracy involved in the administrative task of charting time.
The pressure on hospitals to control costs and minimize mistakes has never been more important. The legal, insurance and medical requirement for hospitals to accurately chart the time is safeguarded with our wireless synchronized timing solutions.
Patients arriving in the emergency room are charted the moment they arrive. In operating rooms our countdown timers are used extensively to execute numerous timed medical procedures.
Our advanced IP-POE software provides an organization a complete "control and protect" communication platform, thereby, providing organizations with the ability to communication in critical and non-critical times.
In every market we serve our engineering moves forward not only to improve existing products but also to develop products that will save our customers time and money.
Wireless PA Systems
We offer two wireless solutions for schools and commercial facilities. Our Wi-Fi System will operate on your existing Wi-Fi. Our Wi-Fi speaker system only requires a strong Wi-Fi signal to operate. The second system we offer is our UHF frequency based wireless PA system.
This system has many advantageous for those organizations that do not have a reliable Wi-Fi network, however, have the need for a public address system.
Solar Clock
Innovation Wireless has its root in the clock industry .
Simple 555 countdown timer circuit with alarm
simple IC-555 countdown timer circuit with alarm.The red and green LEDs will flash alternately and when time to setting the buzzer will loudly sound each time LED flashes. We use IC-555 timer as Stable multi-vibrator and next integrated circuit LM3905-Precision Timer. Parts used in this circuit are easily available in most of the local markets.
How this circuit works

When enter 9 volts power supply to the circuit. IC1- 555 timer act as atable multivibrator to generates oscillator in DC pulse about 0.5 hertz frequency out. In normally the output pin 3 will be out of a square wave. So LED1 will light up when the signal is a negative voltage or “low”, but in same time LED2 will go out. Then, the pin 3 is positive signal, LED1 is OFF and LED2 is ON. This will flash alternately throughout the duration of scheduled. Which the R1, VR1-potentiometer, R2 and C1 determine the frequency or the blinking LED rate.
The IC2-LM3905 is also precision timer IC. which it includes VR2, R6 and C3, to setup time will be long with adjusting the VR2. and change C3 capacitor to higher up cause long time. While the output voltage at pin 7 of IC2 is 0 volt, the piezo-buzzer not sound. But when it’s time to set, the output pin 7 has the positive voltage to BZ1-buzzer beeps out the rhythmic flashing of the LEDs.
Parts will you need
IC1: NE555-timer; Quantity=1
IC2: LM3905-Precision Timer; Quantity=1
C1: 33uF 25V-Electrolytic capacitor; Quantity=1
C2: 0.01uF 50V-Ceramic capacitor; Quantity=1
C3: 33uF 25V or more-Electrolytic capacitor; Quantity=1
R1,R2: 10K 0.25W Resistors; Quantity=2
R3,R5: 1K 0.25W Resistors; Quantity=2
R4: 680 ohms 0.25W Resistors; Quantity=1
R6: 1M 0.25W Resistors; Quantity=1
VR1: 50K Trimmer Potentiometer; Quantity=1
VR2: 1M Trimmer Potentiometer; Quantity=1
D1: 1N4001 50V 1A Diodes; Quantity=1
LED1,LED2: 3mm Red and Blue LEDs;Quantity=2
BZ1: 6V piezo-Buzzer;Quantity=1
IC1: NE555-timer; Quantity=1
IC2: LM3905-Precision Timer; Quantity=1
C1: 33uF 25V-Electrolytic capacitor; Quantity=1
C2: 0.01uF 50V-Ceramic capacitor; Quantity=1
C3: 33uF 25V or more-Electrolytic capacitor; Quantity=1
R1,R2: 10K 0.25W Resistors; Quantity=2
R3,R5: 1K 0.25W Resistors; Quantity=2
R4: 680 ohms 0.25W Resistors; Quantity=1
R6: 1M 0.25W Resistors; Quantity=1
VR1: 50K Trimmer Potentiometer; Quantity=1
VR2: 1M Trimmer Potentiometer; Quantity=1
D1: 1N4001 50V 1A Diodes; Quantity=1
LED1,LED2: 3mm Red and Blue LEDs;Quantity=2
BZ1: 6V piezo-Buzzer;Quantity=1
Electronic Rotary Switch circuit using Digital IC
Electronic Rotary Switch circuit using Digital IC, use a single switch choose a function of external control circuit has 9 positions.Begin with press the switch S1, the output signal from pin 2 of IC1 as “high” at all, and the pulse signal to IC2, the output at pin 3 is “high” as well.
When you press the switch again and the output pin 3 is “low” is output at pin 2 is “high”. The switch of the output “high” to sort it out. The output at pin 11 and pin 3 to start again.
The output is “high” the output of IC2, can be used for external control, such as volume control circuit, a different function, or control circuit is closed – the lights, etc.Or in combination with IC 4066, which is the analog switch.I need to read the manual first, it is easy to use one circuit.
The resistors R1 and C1, the delay after pressing the switch S1,To a recognition that each of the switch, the switch only once, actually,.As a single pulse, entering the circuit, and the IC3a IC3b, a reset signal to IC1 and IC2.
The resistors R1 and C1, the delay after pressing the switch S1,To a recognition that each of the switch, the switch only once, actually,.As a single pulse, entering the circuit, and the IC3a IC3b, a reset signal to IC1 and IC2.

How to build its.
Although this circuit as the experiment is set. But you can build as the electronic for use in your working. in Figure 2 is Universal PCB layout of all components. and the parts you can see in circuit(Figure 1)
Although this circuit as the experiment is set. But you can build as the electronic for use in your working. in Figure 2 is Universal PCB layout of all components. and the parts you can see in circuit(Figure 1)

Figure 2 Universal PCB layout of all components.
Time reversibility
A mathematical or physical process is time-reversible if the dynamics of the process remain well-defined when the sequence of time-states is reversed.
A deterministic process is time-reversible if the time-reversed process satisfies the same dynamic equations as the original process; in other words, the equations are invariant or symmetrical under a change in the sign of time. A stochastic process is reversible if the statistical properties of the process are the same as the statistical properties for time-reversed data from the same process.
Cyberspace
The ‘Live Aid’ movement was comprised of a series of globally broadcast rolling concerts sponsored by corporations who received a moral injection to their advertising profile, as well as patrons at the gates who felt that they were doing something for needy people they had seen on TV.
The later version of empathy-at-a-distance is one in which, by sitting at Internet terminals, those people living in economically and informationally rich countries can do ‘something to help’.
Facebook, cyberspace, and identity
In Life on the Screen: Identity in the age of the internet (1995) Sherry Turkle – Professor of the Sociology of Science at MIT (at the time) and cyber-psychoanalytical theorist – explores the social and psychological effects of the Internet on its users. One of her startling findings is that many denizens of cyberspace appear to value their cyber-identities more than their "normal", embodied selves. The use of the plural – "cyber-identities" – is appropriate here, because invariably the inhabitants of cyberspace construct several identities (or "avatars") for themselves in the course of frequenting MUDS (Multi-user domains), "chatrooms" and the like.
A decade earlier, in The Second Self: Computers and the human spirit (1984), Turkle first examined such identity-transforming relations, but at the time it was still largely a matter of one-on-one, person and machine. The rapidly expanding system of networks, collectively known as the internet, has changed all that, in such a manner that its capacity, via computers, to connect millions of people in new kinds of spaces, has altered the way in which people think, the form of communities, the character of their sexuality and the relative complexity of their very identities (Turkle, 1995: cf 49).
One of the most interesting topics she discusses is the connection between specific kinds of cultural environments and certain kinds of psychological disorders. The advent of the internet and its concomitant opening-up of hitherto unheard-of spaces of encounter have gone hand in hand with many other manifestations of multiplicity and diversity in contemporary, postmodern culture. With this in mind it is striking that, simultaneously, the number of people who display symptoms of what is known as MPD (multi-personality disorder) has burgeoned. She stresses that she is not positing a causal relation between internet-usage and MPD; instead, she is arguing that all the different signs of difference and multiplicity, today, are contributing to modifications of prevailing conceptions of identity (Turkle, 1995: 260-261; Olivier, 2007b).
In clinical cases of MPD, she points out, there are usually various degrees of isolation among the various "alters" and the "host"-personality – an indication that the barriers between these "personalities" block access to "secrets" that have been repressed – while, in contrast, MUD-participants "play" with the various identities constructed by them in virtual spaces.1 This presupposes a fundamentally "healthy" subject capable of constructing and dismantling alter egos as she or he deems fit, without being assimilated into any of them in such a way that it undermines their ability to function 'normally', that is, in a more or less coherent manner. However, it seems likely that a culture that is more tolerant of multiplicity than earlier ones, is also more likely to promote the emergence of multiple identities, in both the healthy sense of developing a more fluid, flexible sense of selfhood, and the sense of creating the cultural environment where pathological symptoms of MPD may manifest themselves more readily. But – and here's the rub – Turkle's (1995: 185, 193) findings indicate an accompanying experience, on the part of many who create online personalities, of their "constructed" selves as somehow "real", more "themselves" even than the person's "basic", everyday, "natural" host-self.
What Turkle has brought to light in her work should not surprise anyone. Didn't Karl Marx already, in the 19thcentury, warn against the dehumanising, reifying effects of factory labour, which robbed workers of their humanity through their use of industrial machines? In other words, technology – including computers and the internet – is never innocuous when it comes to the human beings that use it: invariably it leaves its imprint on people.
But, like computer technology, the internet is not a static thing in its various possibilities either. Among the recent comments (on the part of Turkle) on current technology (such as the IPhone), as well as the appearance of virtual space phenomena such as Facebook, MySpace, LinkedIn and the like, about its progressively diversifying implications regarding the issue of human identity, is her remark, during an interview (Colbert, 2011), that we "have to put technology in its place", and that her research on Facebook indicates that adolescent users reach a certain "performance exhaustion". Not many Facebook users may think of setting up and updating a Facebook profile as a "performance", but as she indicates in the interview with Colbert, it certainly is one.
It is instructive that someone like Turkle, who confesses to loving technology, insists that human beings have somehow overstepped the mark where technology is concerned, and that we have to rediscover the importance of giving other people our full attention when we are together, instead of busying ourselves with our iPhones (Colbert, 2011). How must we understand this caveat being issued by the person who saw in the internet a space of exploration, where we can discover new, better possibilities about ourselves (Turkle 1995: 262-263)? Perhaps one should take a long, hard look at Facebook and its ilk regarding their "effect" on human identity.
If e-mail provided a welcome alternative to those, like myself, who find ordinary postal mail just too cumbersome and slow to engage earnestly in the kind of correspondence sustained by Freud and his contemporaries, Facebook, MySpace and their cyberspace relations have taken the possibilities created by e-mail to new proportions for everyone using these cyber-domains, including users in South Africa. E-mail (or the frenetic use of cell-phones) has its own identity- and psyche-transforming capacities, of course, as the recently deceased French thinker Jacques Derrida shows so convincingly in his Archive fever (1996: 15-18). Derrida argues that Freud already indicated an awareness that, when a new "archiving" technology (including different tools for writing and storing data, such as computers, e-mail and mobile phones) appears on the scene, it is a concrete embodiment of something that has already changed in the human psyche (at least of the inventors of this technology). This will, in its turn, contribute to reconfiguring the psyche of the people who use it. Referring to a kind of cash register made for illiterate people, and to science fiction stories in which robots are depicted as doing everything menial for humans, Rosanne Stone (1996: 168) puts this insight as follows: "... at the inception of the virtual age, when everything solid melts into air, we have other, far more subtle devices that don't do for us but think for us. Not computers, really – they think, in their machinic fashion, and then tell us the answers. Ubiquitous technology, which is definitive of the virtual age, is far more subtle. It doesn't tell us anything. It rearranges our thinking apparatus so that different thinking just is."
Seen in this way, Facebook and its virtual era ilk have paved the way to novel possibilities in the realm of especially the experience of one's own identity. How does one experience one's own identity on Facebook? It seems to me relevant that, on the one hand, these "friend-based" websites are less about socially "connecting and reconnecting". They are, to a far greater extent, I believe, a stage for developing one's own "brand", as it were, and one might add, doing so in a fairly exhibitionistic way. That this is informed by the (ironically) person-diminishing values of capitalism, should be obvious: to "brand" oneself is to offer yourself as a commodity to others for their use, which cannot leave one's intrinsic sense of self-worth unaffected, either negatively or affirmatively, depending on whether one buys into the ideology of capitalism and the market.2Moreover, because "privacy" has been such an issue (Fletcher, 2010) regarding Facebook, one might legitimately wonder at the practice of placing so much information about oneself, one's preferences, likes and dislikes (in textual as well as photographic and video-format), on such a site. It is hardly a manifestation of the desire for privacy. What individuals post there is not what they regard as private (although it may seem like it to others); it is exactly what they want to show, and show off, to others. In the process they do not leave their own sense of identity unaffected.
After all, the question arises, whether the best, digitally "retouched" photos of oneself, or one's list of favourite films, books, musical numbers, and so on (or alternatively, pictures selected to show off just how well you can hold your liquor, or how hard you can party) really represent "you". I would argue that, on the contrary, this composite, mostly carefully constructed "identity" is located at the level of the largely self-deluding, alienating register of what psycho-analytical theorist Jacques Lacan calls the "imaginary" (which is the subject-register of fantasy and alienation, so clearly shown in his analysis of the "mirror phase"; Lacan, 1977: cf 1-7; Olivier, 2009). If this is indeed the case, the upshot is that it is not one's everyday, multi-facetted "self" displayed on Facebook, but something entirely fictional, of the order of the "ego" in Lacanian terms, which is a far cry from the "self that speaks". Unlike the "ego" of the imaginary register, the "self that speaks" (at the level of the symbolic register of language) cannot be objectified in this manner, because it always accompanies speech-acts at an unconscious level (Lacan, 1977a: cf 49, 55).
While it is true that the ego-component of one's subjectivity is an indispensable constituent of the human subject, the more one identifies with its embodiments in the guise of carefully chosen photographs (on Facebook), and so on, the more it becomes a straitjacket for one's "identity", and the less one is able to "choose one's own narrative" (Lacan, 1977a: cf 46-47). In addition to the imaginary "ego", every human subject needs the registers of the symbolic (as well as of the "real") to be capable of such choice. Given their commitment to imaginary representation, Facebook aficionados are bound to find the third Lacanian register of the self disconcerting – that of the unsymbolizable "real", which surpasses language as well as iconicity (Lacan 1981: cf 55; Lacan, 1997: cf 20). It constitutes the always latent, but inexpressible domain which announces itself negatively when we come up against the limits of language, as in cases of trauma. (Lacan's theory is discussed in more detail below.) Facebook users may delude themselves into believing that what they see in its "pages" are "real" people, but in truth these images amount to only one aspect of their complex selves, namely its fantasy (imaginary) component, and by identifying with them, they introduce a significant element of fictionalizing alienation into their lives (Lacan, 1977; Olivier, 2007a).
SOCIAL NETWORKING SITES, THE PRIVATE AND THE PUBLIC.
I'm not pointing out these implications because I want to be a spoilsport. It is also true that, on the other hand, Facebook and MySpace have, like all novel inventions, an upand a downside. The upside includes the possibilities they create for genuinely interpersonal, "communicative" cyber-communities of friends, colleagues, scientists, academics and other (shared) interest groups, to engage in debates, exchange valuable information relevant to research in various disciplines, share photographs of hiking trips, and so on. But people should not fool themselves into believing that Facebook will leave the face of humanity unchanged. If Turkle's work on the internet's social effects is anything to go by, one may anticipate that the very artificiality of the personal profiles on Facebook may well aggravate the kind of socially "artificial" behaviour encountered among economically competitive yuppie types, in whose interest it is to promote themselves as a "brand".3
At the time when Turkle published Life on the screen (1995), the social networkingsite, Facebook, did not yet exist, and for some time now it has seemed important to reflect on the relevance of her work for such virtual social spaces (Olivier 2007). One could legitimately surmise that, as in the case of older MUDS, frequenting spaces such as Facebook or MySpace would not leave the social identities of the individuals who do so untouched, either. Recent reports and articles on Facebook seem to confirm this, but more importantly, they enable one to see an unexpected side of the social networking site. (I shall return to Turkle's more recent work later.)
So, for example, Steven Johnson's piece in Time (2010: 29), called "In praise of oversharing" contrasts Josh Harris's experimental "art project" of the 1990s, where, first, a hundred-plus people, and later, just he and his girlfriend, lived together in an underground bunker, every moment of their lives recorded on film by a network of live web cameras ("webcams"), with the kind of "oversharing" made possible by Facebook on a large and ever-growing scale (it recently registered its 500 millionth user). In the case of the former, Johnson argues, we witnessed a case of "extreme" exposure – with every quarrel and toilet visit filmed – which hardly anyone would voluntarily submit to or choose, while the latter represents a shared space of limited public exposure – one that is subject to users' own decisions about what and how much of it they wish to share, and with whom. Still – and this is the important thing, as far as I can judge – for Johnson the growth in Facebook membership, as well as its popularity, is an indication of people increasingly feeling at home in what is neither the secluded space of privacy, nor the public space of prominent or famous public figures, but something in-between.
There is more to it than this, however. In "Friends without borders", Dan Fletcher (2010: 22-28) also focuses on the phenomenon of Facebook, affording one a glimpse of another, less often discussed side of what may, to some, seem to be no more than an innocuous, socially useful internet site, where one can keep track of events on your friends' and family's lives. Moreover, it seems reassuring that privacy controls on Facebook allow you to set limits to the identities of the people you want to give access to it, in other words, to just how public you want information about yourself and your family to be. There's the rub, however, because no matter how "safe" and personally useful Facebook may appear to be, the company has on more than one occasion introduced innovations that were met with dismay on the part of users, and its privacy controls have been described as "less than intuitive", if not downright "deceptive" (in Fletcher's words).
Why would this be the case, if one may reasonably expect the company to ensure that such control settings are relatively easy to operate? It may be silly to see anything sinister in this, but consider the following. Among the innovations referred to earlier, was the 2007 introduction of Facebook Beacon, which, by means of default settings, automatically sent all users of Facebook friends' updated information about their shopping on some other sites. At the time, CEO Zuckerberg was forced into a public apology for such unwarranted invasion of users' privacy (Fletcher, 2010: cf 24).
It did not end there, however. Following his hunch, that the amount of information that people would be willing to share (and that Facebook as well as other companies could benefit from) is virtually unlimited, Zuckerberg introduced a far-reaching enterprise called Open Graph in April 2010. It allows users to comment on anything and everything that they like on the internet, from merchandise to stories on news sites – presumably on the assumption that you would be interested in your friends' preferences, and vice versa. The catch is that it is not only one's friends who are interested in this. As Fletcher (2010: 24) points out in his article, Facebook is able to display these predilections on the part of its users on any number of websites. Not surprisingly, in one month's time after Open Graph's launch, in excess of 100000 other sites had integrated its technology with theirs (Fletcher 2010: 24).
It is not difficult to guess why. Small wonder that Facebook has had to look at its privacy controls once again, in order to "enhance" them, after the Electronic Privacy Information Center lodged a complaint – relating to confusion regarding Facebook's ever-changing policy, as well as its less-than-clear privacy controls design – with the Federal Trade Commission in the US (Fletcher 2010: 24). It is easy to see in all of this merely a misunderstanding of Facebook's "mission", described by Zuckerberg as aiming at making the world "more open and connected" (ibid: 24). This comes with a rider, though. It appears that the company is pushing users as far as it can to expose their likes and dislikes to other, customer-hungry companies, and benefitting financially in the process. Few people would find fault with Facebook's attempt to profit from its users' buying preferences, but there is more at stake than that, as I shall try to show.
FOUCAULT, PANOPTICISM AND FACEBOOK.4
The philosopher Michel Foucault (1995: cf 191-194) has observed that in the premodern age the individuals whose identities were fleshed out to more than life-size were royalty and nobility – the King and Queen were highly individualized because of their elevated station in society, while ordinary people, at the bottom of the social ladder, were largely left to anonymity. According to Foucault, what has distinguished modernity in this respect is the "descending" level of individualization, that is, the fleshing out, through meticulous description, of the identities of people who are furthest removed from royalty, such as criminals and individuals with a distinctive medical or psychiatric condition. And today, in postmodernity, one might add that the level of individualization has been taken a step further in various ways5, including the advent of social networking sites such as Facebook. Needless to stress, "individualization" is inseparable from what is commonly meant by "identity", namely features or attributes that distinguish individuals from one another, but that may also display marked similarities, as in the case of "cultural identity".
As the "panoptical", "maximum-visibility" age of disciplined, docile6 bodies (as Foucault has described modern people whose lives are constantly subjected to procedures of "normalization" and infantilization; 1995: cf 136-138; 200-201) has unfolded, even those ordinary people who did not fall foul of the law, nor became assimilated into medical and psychiatric institutions, have had their identities progressively assigned to educational and governmental data banks and population registers in a process of "normalizing judgment". The consequence has been that virtually every citizen in contemporary democratic states has become as highly individualized in terms of personal attributes – birthplace, domicile, educational qualifications, criminal record, and so on – as royalty and the aristocracy were in earlier ages.
It may seem counter-intuitive that Facebook could contribute to "normalizing" in any sense, and yet, it is a social networking site that appears to "dictate" important social "decisions" or behaviour of millions of internet users. One should not overlook the unexpected ways in which it dovetails with individualizing practices of the kind described by Foucault. For one thing, Facebook is predicated, according to CEO Zuckerberg (Fletcher 2010: cf 24), on the hypothesis that the public is receptive to virtually unlimited openness regarding sharing of (personal) information. But what is the myriad of informational elements that are placed on Facebook every day, other than (voluntarily supplied) information – that one cannot definitively delete, into the bargain – and that can be used by, or against, the users involved? (Rosen, 2010).
Moreover, when one looks carefully at the three specific ways, identified by Foucault, in which modern subjects are turned into "docile bodies", Facebook and MySpace are cast in an even less innocuous light. There are especially three distinctive modern ways of producing such docile bodies, according to Foucault. The first is what he calls "hierarchical observation", or "a mechanism that coerces by means of observation; an apparatus in which the techniques that make it possible to see induce effects of power" (Foucault, 1995: 170-171), of which the "panopticon"-prison (ibid: cf 200-202) is an embodiment, where the prisoners are (potentially) under constant surveillance by warders.
Foucault (1995: cf 177-184) calls the second way of producing docile bodies "normalizing judgment". It concerns the "power of the norm". Where he elaborates (ibid: 184) there are noticeable points of connection with Facebook as a virtual space of display and comparative judgment: "In a sense, the power of normalization imposes homogeneity; but it individualizes by making it possible to measure gaps, to determine levels, to fix specialities and to render the differences useful by fitting them one to another. It is easy to understand how the power of the norm functions within a system of formal equality, since within a homogeneity that is the rule, the norm introduces, as a useful imperative and as a result of measurement, all the shading of individual differences." In former ages, then, individuals may have been judged according to the intrinsic moral value ("virtue") or the reprehensibility of their actions, but today the tendency is to place them on a differentiating scale or continuum which ranks them in relation to everyone else.
The third disciplinary practice of reducing bodies to docility is familiar to everyone today: the examination (Foucault, 1995: cf 184-194; Gutting, 2005: cf 84-86). The introduction of the examination made possible the connection of knowledge of individuals with a specific exercise of power. According to Foucault (1995: 187), the "examination transformed the economy of visibility into the exercise of power". He points to the ironic reversal, namely that traditional (premodern) power was visible, while the subjects of power were largely invisible, whereas modern, disciplinary power operates through its invisibility, while simultaneously enforcing an obligatory visibility on disciplined subjects, in the course of which they are drawn into a "mechanism of objectification" (ibid: 187). The examination "also introduces individuality into the field of documentation" (ibid: 189). This entails archiving, through which individuals are placed within "a network of writing", and one cannot ignore the discursive violence reflected in Foucault's choice of words, where he alludes to the "mass of documents that capture and fix them" (ibid: 189). Moreover, examination as a mechanism of disciplinary power, "surrounded by all its documentary techniques, makes each individual a 'case'" (Foucault 1995: 191). In this way the examination has contributed significantly to lifting ordinary individuality, which once was in the shadows of imperceptibility, into the kind of conspicuousness that goes hand in hand with disciplinary control, which turns the individual into an "effect and object of power" (ibid: 192), a "docile body".7
Examination is probably the most invidious and effective form of disciplinary domestication, because it combines the previous two, hierarchical observation and normalizing judgment, and is a privileged locus of the modern nexus of power and knowledge. At the same time, the examination generates "truth" about individuals, and lays the basis for their control through the norms that are established in this way.
I have elaborated on Foucault's account of disciplinary mechanisms which have played a crucial role in the constitution of the subject of modern power, not because I believe that Facebook, MySpace and similar internet sites are identical to the disciplinary mechanisms concerned, but because I believe one can learn much about contemporary identity-formation from considering these cyberspaces of social interaction in light of Foucault's observations.
Had Foucault still been alive today, he would probably have looked upon virtual spaces for social interaction and information-distribution, including Facebook and YouTube, as a phenomenon that has taken the process of individualization in a panoptical context (in the service of optimal control) a few steps further. Not content with the amount of personal information that one is already obliged, by law, to furnish to governmental, educational and commercial institutions, people have more than lived up to the CEO of Facebook, Mark Zuckerberg's bet, that they have an expandable appetite as far as sharing information goes (Fletcher, 2010: cf 24) – information that is hugely valuable for companies searching for potential customers.
The difference with Facebook is that, by contrast with obligatory information given to the state, the information shared with friends and family is voluntary, and that it is selectively posted with a view to promoting something – either optimal informedness among family members, or one's personal standing among your friends regarding your "cool" looks and fashion tastes, or perhaps one's professional interests, by using the space for sharing important information (such as lecturers disseminating reading matter among students). But Facebook has not made sure that information about users' lives is restricted to this; in fact, quite the opposite. The very fact that the default settings on users' privacy controls is automatically on maximum exposure (Fletcher, 2010: cf 24), so that the responsibility for adjusting them rests on every user's shoulders, is already quite telling in this regard.
It may be that, at this stage, the subtle and not-so-subtle ways in which Facebook has succeeded in exposing users to more (potential) attention from other companies than they probably anticipated, have no more than financial or economic objectives, but the potential for extensive social or psychological manipulation, if not "control", is considerable. Moreover, just as, in the panoptical prison, where inmates monitor their own behaviour (on the assumption of their constant surveillance by warders with full visual access to them), indications are that individuals are increasingly engaging in a form of self-monitoring of behaviour via voluntary self-exposure on internet sites such as Facebook.
It is not difficult to grasp such self-monitoring in terms of the three mechanisms of disciplinary power distinguished by Foucault (discussed earlier). Posting information about oneself on Facebook in the form of selected photographs and textual descriptions of likes and dislikes regarding movies, clothes, cosmetics, food, books and more, is subject to "hierarchical observation" in so far as it conforms to notions of what is "cool" (or, ironically, "hot"), that is, acceptable to one's peers. In the light of what Susan Faludi (1999) has called "ornamental culture", where the "cool look" is valorized at the cost of meaningful social and political action, the implication is that Facebook probably reinforces this state of affairs. Even the odd instance of cocking a snoot at criteria of "coolness" confirms the behavioural power (the power to affect behaviour) of the hierarchical norm in a paradoxical fashion, albeit the kind of behaviour – if Faludi is right (and I believe she is) – which is marked by political passivity in post-industrial, "developed" societies like the United States.8
The same is true, in a related manner, of "normalizing judgement" and the "examination". While Facebook is also a means for family members and friends to keep in contact, and share photographs of trips, places visited, and so on, "normalizing judgement" (which probably even functions among family and friends in a "keeping up with the Joneses"-fashion), operates through evaluating-judging comparisons, which have the result of setting up certain norms (of appearance and choice of merchandise, for instance). It may seem counter-intuitive that "examination" should play a role here, but if one recalls the phenomenon of the (often televised) "makeover" – that is, revamping one's home, or one's personal appearance, for the approval of one's peers – then it is clear that Facebook participates in this process of "making visible" of individuals, and therefore also of "individualizing" in terms of standards that allow comparison (which, paradoxically, is closer to "standardization" than to individualization!).
In the context of Facebook it may appear that all of these mechanisms attain an undeniable level of psychological importance if we consider that – while this is not necessarily true of the "disciplinary" cases considered by Foucault – they comprise what Rabinow (1984: cf 10-11) considers to be Foucault's most original contribution regarding the "modes of objectification" by which human beings are made into subjects, namely "subjectification". (The other two are "dividing practices" and "scientific classification"). This entails the "way a human being turns him-or herself into a subject" (Foucault, quoted in Rabinow, 1984: 11). Rabinow further characterizes this as "those processes of self-formation in which the person is active", such as what Foucault (1988; Olivier 2010a) terms "the care of the self" practiced by individuals during the Hellenistic era – a difficult process of active self-examination and living according to a strict regime of self-formation and self-discipline. However, further reflection indicates that this is not the case. Although Facebook arguably does contribute to "selfformation", it does not seem to exhibit the strenuous, active character of Hellenistic practices of self-formation.
FACEBOOK AND "THE INFORMATION BOMB".
The most radical assessment of Facebook is made possible by the work of Paul Virilio, in a book that was first published before Facebook existed – which itself confirms the extent to which it is another development along a continuum of technical-social transformations. Virilio extends Foucault's interpretation of the panoptical, disciplinary society with far-reaching consequences in The information bomb (2005) – it seems that he virtually anticipated the Wikileaks affair of 2010 (Olivier, 2011), as is clearly evident from the following (Virilio, 2005: 63): "After the first bomb, the atom bomb, which was capable of using the energy of radioactivity to smash matter, the spectre of a second bomb is looming at the end of this millennium. This is the information bomb, capable of using the interactivity of information to wreck the peace between nations." I would argue that social networking sites like Facebook are part and parcel of this "information bomb".
What led Virilio to this insight? When June Houston installed 14 "live-cams" in her house in 1997 to transmit visual access to all its strategic sites to a website, in the process enabling others to provide her with "surveillance reports" on the appearance of anything suspicious, Virilio (2005: 59; bold in original) believes that one saw: "... the emergence of a new kind of tele-vision, a television which no longer has the task of informing or entertaining the mass of viewers, but of exposing and invading individuals' domestic space ... the fear of exposing one's private life gives way to the desire to over-expose it to everyone ..."
This description seems to me to apply to Facebook and MySpace. That it is an extension of the panoptical spaces of Foucault's disciplinary society should be evident, although it is less clear whether such over-exposure goes hand in hand with "discipline". Virilio makes its panoptical character explicit (2005: 61) where he intimates that the extension of June Houston's self-created panopticism demands "a new global optics, capable of helping a panoptical vision to appear". Significantly, he also points out that such a vision is indispensable for a "market of the visible" to emerge. According to Virilio (2005: 60), Houston's actions – which have since been replicated with different purposes in mind – were revolutionary, transforming the transparency of living spaces to which informational television programmes have accustomed us, towards what he calls "... a purely mediatic trans-appearance ...", and he attributes the growth of this practice to the requirement, on the part of the globalization of the market, that all activities and behaviour be "over-exposed" (2005: 60): "... it requires the simultaneous creation of competition between companies, societies and even consumers themselves, which now means individuals, not simply certain categories of 'target populations'. Hence the sudden, untimely emergence of a universal, comparative advertising, which has relatively little to do with publicizing a brand or consumer product of some kind, since the aim is now, through the commerce of the visible, to inaugurate a genuine visual market, which goes far beyond the promoting of a particular company." It is especially the "competition between individuals" that is germane to the present theme. Facebook is part and parcel of this phenomenon, in so far as it enables one to display one's wares, as it were, and appear to attract as many "friends" as one would like, but simultaneously deferring the moment of entering into real friendships, and all that accompanies them, such as trust, risk, mutual emotional support and fulfilment, but also the possibility of betrayal.9
This is seamlessly connected to what Virilio (2005: cf 61) further sees as being part and parcel of globalization, namely, that individuals continually observe one another comparatively in terms of ("ornamental") appearance. It is further related to the marketing value of (among other things) Facebook usage that was referred to earlier, because of the access that companies have to the comparatively displayed preferences on individuals' Facebook pages. It is mainly for this reason that Facebook was recently (January 2011) valued at $500 billion, given the unprecedented access that companies have to the more than 500 million Facebook users' likes and dislikes. Companies don't even have to advertise comparatively any more; potential customers and clients do the advertising of their own preferences in merchandise on an individual basis, with ever more refined targeting of such individuals' tastes by sellers of just about anything that may be bought, from personal services to all the consumer products available on the globalized market today.
It is debatable whether this state of affairs displays an increased potential, if not actuality, of the "disciplining" or the manipulation of individuals by various agencies, from corporations to the state. In the first place it should be clear that the voluntary display of personal preferences on the internet invites marketers of all stripes to focus their efforts on individuals. Needless to say, being targeted (online) by multiple companies on the basis of one's displayed preferences in the virtual realm, contributes to a sense of identity that is bound up with "cyber-selves". Secondly, the attempt by many Facebook users, to put their best foot forward as far as their appearance is concerned, signals something closely related to the kind of self-monitoring that occurs in panoptical prisons on the part of prisoners who know they are potentially being monitored. In posted photographs Facebook aficionados tend to appear as they believe their "friends" would like to see them, whether that be in perfectly "photoshopped" guise or in any other way they would like to be seen. This is part of Virilio's "comparative observation" and Faludi's "ornamental culture". It is the "pseudo" version of what Foucault (in Rabinow, 1984: 11) calls (self-) "subjectivization", which (unlike its active counterpart) is consonant with panoptical surveillance.
Virilio provides one with a broader horizon for understanding phenomena such as Facebook, one that allows you to see surveillance as a truly global project. He shows that the internet has allowed the transformation of "tele-vision" into what he calls "planetary grand-scale optics" (Virilio, 2005: 12): "... domestic television has given way to tele-surveillance". The mono-directionality of television is replaced with dualdirectionality of visualization through the use of live web cameras ("webcams"), which enable one to see "what is happening at the other end of the world" (Virilio, 2005: 17). If it is kept in mind that "virtualization" (the representation of the world, or aspects of it, in computer- and internet-generated "cyberspace") cannot be separated from "visualization" (ibid: 14) in this context, Facebook, MySpace and YouTube can all be seen as constituting visual perspectives on the virtualization of the world, more specifically, the virtualization of subjects or personalities. In Virilio's words (2005: 16): "The aim is to make the computer screen the ultimate window, but a window which would not so much allow you to receive data as to view the horizon of globalization, the space of its accelerated virtualization ..."
Such developments are not innocuous as far as individuals' experience of themselves – that is, individual psychology – is concerned. At the beginning of this paper I referred to Sherry Turkle's misgivings about what she sees as the detrimental effect of technology (such as cell phone use) on individuals' social skills. Virilio (2005: cf 19-27) allows one to take this further. In a nutshell, he interprets the development of the internet and everything that it has made possible – e-mail, global-reach "live webcams", Facebook, YouTube, and so on – as the contemporary manifestation of a tendency that is (and, for historical reasons, has for a long time been) part and parcel of the American collective psyche, namely the projection of a "frontier" to be crossed or conquered. Only, there are no more geophysical frontiers to be conquered on the planet (something graphically captured in the subtitle of Gene Roddenberry's fictional television series, Star trek, namely, The final frontier), and hence the turn, progressively, to so-called "virtual or cyber-reality": "Cyber is a new continent, cyber is an additional reality, cyber must reflect the society of individuals, cyber is universal, it has no authorities, no head, etc." (Barlow et al, quoted in Virilio, 2005: 27).
Virilio leaves one in no doubt about his understanding of, and expectations concerning the social consequences of this virtualization of the world. He quotes from a speech by President Bill Clinton, where the latter eulogized the "promise of America" in the 20th century, but also spoke of America's "fractured, broken-down democracy" that could lead to a "major political catastrophe" (Virilio, 2005: 19). Then, implicitly tying this to the belief that cyberspace is widely seen as the new territory to be conquered, Americanstyle, Virilio observes (2005: 25): [ Hollywood] "... industrial cinema, by upping its false frontier effects to the point of overdose, must inevitably generate social collapse and the generalized political debacle we find at this 'American century'-end".
Like Lyotard (1992: cf 9) before him, Virilio (2005: cf 25) sees the development of capitalist "industrial" and "post-industrial" cinema as stages in the "catastrophe of the de-realization of the world", the more recent stages of which involve the development of computer-technology, the internet and its attendant technologies. Judging by strong words like "social collapse" it is quite apparent that, for him, these developments are not inconsequential or innocuous. He (ibid: 67; italics and bold in original) sees the intermittent collapse of financial markets – which display an undeniable "virtual" side – as symptomatic of the possibility of such a social collapse: "The smaller the world becomes as a result of the relativistic effect of telecommunications, the more violently situations are concertinaed, with the risk of an economic and social crash that would merely be the extension of the visual crash of this 'market of the visible', in which the virtual bubble of the (interconnected) financial markets is never any other than the inevitable consequence of that visual bubble of a politics which has become both panoptical and cybernetic".
FACEBOOK, IDENTITY AND LACAN.
The question, then, is how one should understand my initial claim, that the use of social networking internet sites like Facebook has an impact on identity-or self-formation. And what is the connection between such identity-formation and the bleak picture, painted by Virilio, of the globalization of panopticism in a new guise, namely the visualization of what used to be social and political space, and its "virtual" consequences? Here I have to turn, once more, to Sherry Turkle, before framing my conclusion in Lacanian terms of the real, imaginary and the symbolic. In Simulation and its discontents (2009) (with its Freudian overtones), Turkle elaborates on the extent to which spaces of simulation – including cyberspace – have of late exercised an irresistible attraction for individuals like architects, with the result that the spatiotemporal world of concrete objects like buildings seems to be progressively devalued at the cost of the simulated realm.
Given their attachment to a less obviously mediated contact with the materials and objects of their fields of inquiry in architecture and physics, Turkle contrasts an older generation's skepticism about simulation and its promises with the younger generation's infatuation with simulation in all its guises. Many of the older generation viewed the computer as a tool which, despite some useful computing functions, would lead students and scientists alike away from reality, to their detriment. Today, by contrast, architecture students find it hard to imagine how skyscrapers could have been designed in the 1950s without the use of a computer and the appropriate design software. Her research has led her to the point where she issues a warning, however (Turkle, 2009: 7): "Immersed in simulation, we feel exhilarated by possibility. We speak of Bilbao [ probably a reference to Frank Gehry's Bilbao Guggenheim, sometimes called the most complex building ever designed, with the help of computer-simulation] , of emerging cancer therapies, of the simulations that may help us address global climate change. But immersed in simulation, we are also vulnerable. Sometimes it can be hard to remember all that lies beyond it, or even acknowledge that everything is not captured in it. An older generation fears that younger scientists, engineers, and designers are 'drunk with code'. A younger generation scrambles to capture their mentors' tacit knowledge of buildings, bodies, and bombs. From both sides of a generational divide, there is anxiety that in simulation, something important slips away."
Turkle rephrases the architect, Louis Kahn's famous question, "What does a brick want?" to read: "What does simulation want?" and answers that, at one level, it wants immersion, which is a prerequisite for actualising its full potential. The negative side of this is, as one can easily gather from the enthusiasm of students and practitioners of various stripes, that it is easy to be seduced by it, and difficult to take critical distance from it. As Turkle (2009: 7-8) observes: "Simulation makes itself easy to love and difficult to doubt. It translates the concrete materials of science, engineering, and design into compelling virtual objects that engage the body as well as the mind ... Over time, it has become clear that this 'remediation', the move from physical to virtual manipulation, opens new possibilities for research, learning, and design creativity. It has also become clear that it can tempt its users into a lack of fealty to the real ... The more powerful our tools become, the harder it is to imagine the world without them."
These reflections on the part of someone intimately familiar with the internet technology-mediated virtuality and visuality thematized by Virilio, seem to me to confirm that there is something irresistibly seductive about this mediated realm, of which Facebook is a part. One may wonder whether the massive participation in cyberactivities like those discussed above can really be of such consequence that Foucault's and Virilio's insights may gain a critical purchase on them in terms of a kind of selfformation which could conceivably have a disastrous impact on society (especially if you are a willing participant in the cyber-activities involving Facebook and/or various other MUDs like WoW). Jacques Lacan's work enables one to give a tentative answer to this question.
I referred earlier briefly to Lacan's theory of the human subject in terms of three interlocking registers or orders, namely the "real", the imaginary and the symbolic (Lee, 1990: cf 82; Olivier, 2004). To elaborate: still lacking a sense of self or ego, as well as language, the individual is at birth caught in the real, which she or he leaves behind, like a chrysalis, when they enter, first, the imaginary through the so-called "mirror stage", and subsequently the symbolic order through the acquisition of language. The imaginary order is one of alienation through "misrecognition" of the self in what amounts to a fiction, but also of particularistic ego-identification with one's own mirrorimage, which forms the basis of subsequent identifications with others and with the images of others. A person's "identity" is not synonymous with his or her subjectivity – in fact, "identity" does not sit well with Lacan's complex conception of the subject – but pertains largely to the imaginary register of the ego. The symbolic register, by contrast, is universalistic, in so far as it bestows upon the individual ego, through "universals" such as "human being", her or his character as a "subject" – that is, subject to the moral law conceptually embedded in language. (Without language, no ethics.) The symbolic is also the index of the social, in so far as it is the register of the "other", which is why Lacan (1977a) refers to the unconscious, which is said to be structured "like a language", as the "discourse of the Other". Although the "real" surpasses language and iconicity, and is surpassed through the subject's entry into language, it remains one of the registers along which the subject's subjectivity is articulated, and can, in various ways, affect the imaginary and the symbolic which, together, comprise what we call "reality". It does so through what Lacan (1981: 55) calls the "missed encounter" of trauma, for instance.
In light of this brief account of Lacan's conception of the subject, individuals who dwell in cyber-realms such as Facebook, MySpace or World of Warcraft, may be said to engage in the elaboration, largely, of their imaginary selves, which exacerbates alienation from their "true" selves – the subject of the unconscious (Lacan, 1977b: cf 166; 1981: cf 34) – depending on the degree of linguistic interaction, the symbolic aspect of their subjectivity. The latter may counteract such alienation, provided it is not anchored in the imaginary in such a way that its "talking cure" qualities are hamstrung from the outset. Because the symbolic is the register of social being (or being social), and because it is ineluctably "interrupted" by symptoms of unconscious desire, it always harbours the axiological potential to free oneself from the suffocating grip of the imaginary.10
In other words, there are more ways than one of using language, or rather, of "being in language", not all of them conducive to promoting the kind of subject that is capable of self-questioning and relative autonomy, both of which are functions of discourse, or the symbolic. Virilio (2005: 69-76) points in this direction where he argues that, concomitant with the expansion of the increasingly pervasive cyber-realm (as the new territory to be conquered), one witnesses the contraction of language. That we are increasingly inhabiting what I would label "the era of compliance" – a phenomenon that coincides with the retreat of (un-expurgated) language – is evident from Virilio's (2005: 69-70) observation, that current affairs reporters are being subjected to the distinction between what he calls "'soft' (politically correct) language" and "'hard' (visually incorrect) images": language can give offence to any number of listener-groups, but (uninterpreted) images of violence keep viewers glued to television screens. He (Virilio 2005: 70-71) also remarks on the prominence of international "supermodels" in the popular press, in the place of movie stars, ascribed by some to the fact that "they don't speak", and adds: "There is nothing enticing about our supermodels any more once they have been reduced to silence. Their bodies are not just denuded, but silently exposed ... to laboratory sufferings – from plastic surgery to testosterone ... if they are starting a fashion, it is not a fashion in clothing. The supermodels are already mutants ushering in an unprecedented event: the premature death of any living language ... The new electronic Babel might be said to be dying not from the plethora of languages, but from their disappearance".
Even if one allows for what might seem like an overstatement of the current state of affairs by Virilio, it must be granted, I believe, that the phenomenon in question is not a figment of his imagination. It is confirmed by Faludi's (1999) perspicacious insight into the "ornamental" culture of today, which leaves men and women politically impotent (and suits the economic and political status quo; hence also the culture of "compliance" reinforced through audits, compliance legislation and the like). What I want to argue here, is that there is a link between political correctness, compliance, the devaluation of language, on the one hand, and the progressive valorization of images, especially in cyberspace, including Facebook. To be sure, there is "text" on Facebook, too, but this takes a back seat to images.11 Consider Virilio's (2005: 72) observation, that: "Technological acceleration initially brought about a transference from writing to speech – from the letter and the book to the telephone and the radio. Today it is the spoken word which is logically withering away before the instantaneity of the real-time image. With the spread of illiteracy,12 the era of silent microphones and the mute telephone opens before us. The instruments will not remain unused on account of any technical failings, but for lack of sociability, because we shall shortly have nothing to say to each other, or really the time to say it – and, above all, we shall no longer know how to go about listening to or saying something, just as we already no longer know how to write ..."
The question therefore arises, if the visual image is becoming hegemonic, at the cost of spoken (and written) language, does it signify the unilateral dominance of Lacan's imaginary -the register of alienation – over the symbolic? Both Turkle (Colbert, 2011), who alludes to the detrimental effect of mobile phone use on our social skills, and Virilio (above), who talks about "lack of sociability" that accompanies the rise of the image, draw attention to this possibility.
In terms of Lacan's conception of the subject, this would mean that the imaginary register of the ego (and alter ego), which is also that of "identity" and alienation, would be in the process of subverting the inalienable social, communicational function of the symbolic, If this process were to become pervasive, it might well trigger the "social and political catastrophe" that Virilio (above) has warned about. There is hope in the fact that the third Lacanian register, that of the "real", is always there, however ineffable it may be. What I mean, is simply that, to the degree that something unexpected may, and sometimes does, happen to human beings, be it an unwelcome visitor, or a motor car accident, or some gigantic, collective trauma, like 9/11,13 or the recent tsunami in Japan, the "real" represents the originary source of "something", an "I know not what", which has the power to reconfigure our world completely. And this means reconfiguring our imaginary and symbolic horizons. If the present trajectory of virtual imagepreponderance in cyberspace were to develop to the point where inter-subjective communication were to be threatened to the point of breaking down, that would probably be of the magnitude of a collective trauma that would impact on our imaginary and symbolic horizon with such force that the symbolic would re-claim its place in human subjectivity. The way that "identity" is currently being configured in cyberspace, of which Facebook is a major part, may just be an indication that – given what has been uncovered in dialogue with Foucault, Turkle, Virilio and Lacan – such an event is not an impossibility.
CONCLUSION
I end this article with a quotation from Sherry Turkle, which serves as a reminder of the ambivalent status of the cyber-realm's capacity to enchant, seduce and simultaneously enslave its adherents. Alluding to Wim Wenders's film, Until the end of the world, where a scientist invents a device that transforms brain-activity into such alluring digital images that people are able to see their innermost dreams and fantasies in vivid iconic form,14 she says (Turkle, 1995: 268): "However, the story soon turns dark. The images seduce. They are richer and more compelling than the real life around them. Wenders's characters fall in love with their dreams, become addicted to them. People wander about with blankets over their heads the better to see the monitors from which they cannot bear to be parted. They are imprisoned by the screens, imprisoned by the keys to their past that the screens seem to hold ... We, too, are vulnerable to using our screens in these ways. People can get lost in virtual worlds ... Our experiences there are serious play."
What she observes here goes for social networking cyber-sites such as Facebook as well. They should be kept at arms' length. Lest we become imprisoned, or muted, by them, we should remind ourselves that, although the experiences they enable are not insignificant, they cannot be human social reality, with its indispensable symbolic sphere, in its entirety, and we allow ourselves to be assimilated by them at our peril.
Cyber electronic warfare
Cyber electronic warfare (cyber EW) is a form of electronic warfare. Cyber EW is any military action involving the use of electromagnetic energy to control the domain characterized by the use of electronics and the electromagnetic spectrum to use exchange data via networked systems and associated physical infrastructures.
Cyber EW consists of the following three activities: cyber electronic attack (cyber EA), cyber electronic protection (cyber EP), and cyber electronic warfare support (cyber ES). These three activities are defined as follows:
- Cyber electronic attack (cyber EA)
- Is the use of electromagnetic energy to attack an adversary’s electronics or access to the electromagnetic spectrum with the intent of destroying an enemy’s ability to use data via networked systems and associated physical infrastructures.
- Cyber electronic protection (cyber EP)
- Is any means taken to protect electronics from any effects of friendly or enemy employment of cyber EW that destroys ability to use data via networked systems and associated physical infrastructures.
- Cyber electronic warfare support (cyber ES)
- Is any action to locate sources of electromagnetic energy from networked systems for the purpose of immediate threat recognition or conduct of future operations.
Electronic warfare support
Electronic Warfare Support (ES) is a subdivision of EW involving actions taken by an operational commander or operator to detect, intercept, identify, locate, and/or localize sources of intended and unintended radiated electromagnetic (EM) energy. This is often referred to as simply reconnaissance, although today, more common terms are Intelligence, Surveillance and Reconnaissance (ISR) or Intelligence, Surveillance, Target Acquisition, and Reconnaissance (ISTAR). The purpose is to provide immediate recognition, prioritization, and targeting of threats to battlefield commanders.Signals Intelligence (SIGINT), a discipline overlapping with ES, is the related process of analyzing and identifying intercepted transmissions from sources such as radio communication, mobile phones, radar or microwave communication. SIGINT is broken into three categories: Electronic Intelligence (ELINT), Communications Intelligence (COMINT), and Foreign Instrumentation Signals Intelligence FISINT. Analysis parameters measured in signals of these categories can include frequency, bandwidth, modulation, and polarization.The distinction between SIGINT and ES is determined by the controller of the collection assets, the information provided, and the intended purpose of the information. Electronic warfare support is conducted by assets under the operational control of a commander to provide tactical information, specifically threat prioritization, recognition, location, targeting, and avoidance. However, the same assets and resources that are tasked with ES can simultaneously collect information that meets the collection requirements for more strategic intelligence .- The Well and deep Proxies on electronic circuit concept
- The MACH5 appliance is a proxy server that acts as an intermediary for requests from clients in a local network wanting to download or access information from origin content servers (OCS) on the Web. A client makes a request to an OCS, but the appliance, acting as a proxy server, processes the request. Content is placed in the cache to be provided to other users, and the proxy provides the file to the user who requested the content.

The MACH5 appliance contains a number of protocol-specific proxies for managing different types of traffic, as listed below.
the CIFS Proxy?

The Common Internet File System (CIFS) protocol is based on the Server Message Block (SMB) protocol used for file sharing, printers, serial ports, and other communications. It is a client-server, request-response protocol that allows computers to share files and printers, supports authentication, and is popular in enterprises because it supports all Microsoft operating systems, clients, and servers.
More than one client can access and update the same file, while not compromising file-sharing and locking schemes. However, CIFS communications are inefficient over low bandwidth lines or lines with high latency, such as in enterprise branch offices. This is because CIFS transmissions are broken into blocks of data. When using SMBv1, the client must stop and wait for each block to arrive before requesting the next block. Each stop represents time lost instead of data sent. Therefore, users attempting to access, move, or modify documents experience substantial, work-prohibiting delays.
The second version of SMB (SMBv2) alleviates some of the inefficiencies in CIFS communication and improves performance over high latency links. Servers that support SMBv2 pipelining can send multiple requests/responses concurrently which improves performance of large file transfers over fast networks. While SMBv2 has some improvements, it does not address all of the performance issues of CIFS; for example, it cannot reduce payload data transferred over low bandwidth links.
The CIFS proxy on the MACH5 appliance combines the benefits of the CIFS protocol with the abilities of the MACH5 appliance to improve performance, reduce bandwidth, and apply basic policy checks. This solution is designed for branch office deployments because network administrators can consolidate their Windows file servers (at the core office) instead of spreading them across the network.

After the proxy identifies CIFS traffic, the appliance uses the following techniques to control these connections:
- Object caching
- Byte caching
- Compression
- TCP optimization
- Protocol optimization
What is Traffic Acceleration on the MACH5?
Using the MACH5 appliance's traffic management capabilities, you can define acceleration rules for handling the different types of traffic flowing through the device. These rules determine whether a specific type of traffic (a service) is accelerated and which types of acceleration techniques are applied. Blue Coat Sky delivers pre-configured rules, but you have the freedom to modify them if you like. By accelerating network services, you can reduce the amount of traffic that traverses the WAN, effectively making more bandwidth available without upgrading the link size.
Intercepting a Service
When the MACH5 appliance intercepts a service for acceleration, it applies any of several techniques to optimize/accelerate the traffic. When a service passes through the MACH5 appliance without being controlled in any way, the traffic is bypassed. The MACH5 appliance applies default intercept/bypass settings to the services that it recognizes: Intercept for those services that can benefit from optimization and Bypass for those that pass through the MACH5 appliance without processing. Some services are set to bypass by default, but could benefit from interception—you can decide whether you want/need to accelerate any of these services. Note that these services may require specific knowledge of the local network environment.
Traffic Modes
In acceleration mode, the MACH5 appliance attempts to optimize all services that have interception enabled. If you answer yes to the question about activating acceleration in the configuration wizard, acceleration mode will be enabled. In bypass mode, intercept settings are ignored and all traffic passes through the MACH5 appliance without any attempt at optimization. If you answer no to the acceleration question, bypass mode will be selected.
- Acceleration mode: honors the service configuration and intercepts the specified services
- Bypass mode: Ignores intercept settings; disables acceleration
Levels of Acceleration
There are three levels of acceleration: Application, Data, and Network. The MACH5 appliance assigns a default acceleration level appropriate for each intercepted service.
- Data: Reduces bandwidth usage for most types of TCP traffic in the service.
- Network: Improves handling of packet loss and congestion. Network level accelerates traffic that cannot be accelerated at higher levels.
Acceleration Techniques
The MACH5 appliance can perform the following types of acceleration.
| Method | Description |
|---|---|
Network optimization
|
On high-latency networks or networks experiencing packet loss, the appliance improves network efficiency and relieves congestion by adjusting TCP window sizes.
|
Byte caching
|
Replaces byte sequences in traffic flows with reference tokens. The byte sequences and the token are stored in a byte cache on a pair of MACH5 appliances (for example, one at the branch, the other at the data center). When a matching byte sequence is requested or saved, the MACH5 appliance transmits the token instead of the byte sequence. By eliminating repeated patterns of non-cacheable data (or data going over protocols for which a proxy isn't available) from being sent across the WAN, byte caching allows further reduction in WAN bandwidth. The byte cache can be populated by data sent in either direction, and matches can also occur on data flowing in either direction.
|
Compression
|
GZIP compression removes extraneous/predictable information from traffic before it is transmitted. The information is decompressed at the destination's MACH5 appliance.
|
|
|
The MACH5 appliance caches HTML pages, images, streaming content, and CIFS file data so that it can serve this data directly to clients; object caching saves time and bandwidth since the content needn't be accessed repeatedly across the WAN.
|
Protocol optimization
|
Application-layer optimizations use techniques such as read-ahead, pipelining/prefetch, and meta-data caching to reduce "chattiness" in network protocols (such as HTTP and CIFS).
|
Bandwidth management
| Prioritizes and/or limits bandwidth by user or application, allowing WAN usage to reflect business priorities. You can create bandwidth rules using over 500 attributes, such as application, website, URL category, user/group, and time/priority. |
Add Static Bypass Rules
A bypass rule tells the MACH5 appliance to not process requests sent between specific clients and servers; this traffic will pass through the appliance without any processing. For example, you can create rules to bypass traffic between all clients and a specific server, between a client subnet and a server subnet, or a specific client IP address and all servers. You may find it necessary to create bypass rules for protocol-incompliant clients and/or servers, in order to avoid disruption in services. Bypass rules prevent the MACH5 appliance from enforcing any policy on requests between the specified client/server pairs and disables any caching of the corresponding responses. Because these rules bypass Blue Coat policy, use them sparingly and only for required situations.
- In Blue Coat Sky, click the Configure tab.
- Select Acceleration > Static Bypass.
- Click Add new rule. A panel opens up for the rule definition.
- For Client IP, select one of the following:
- All—Bypasses traffic between any client and the Server IP specified in step 5 below.
- Enter IP or subnet—Bypasses traffic between a client IP address or subnet and the Server IP specified in step 5 below. Enter the IP address (in IPv4 or IPv6 format) or specify a subnet in IP/CIDR format (for example, 157.54.128.0/21 or 2001:DB8:0:DC00::/54).
- For Server IP, select one of the following:
- All—Bypasses traffic between any server and the Client IP specified in step 4 above.
- Enter IP or subnet—Bypasses traffic between a server IP address or subnet and the Client IP specified in step 4 above. Enter the IP address (in IPv4 or IPv6 format) or specify a subnet in IP/CIDR format.
- Click Done.
- Repeat steps 3-6 to create additional bypass rules.
- Click Commit all to save all of your bypass rules.
Add Restricted Intercept Rules
When creating a custom service, you can define which client and server pairs have their traffic intercepted for a particular protocol. When creating a restricted intercept rule, on the other hand, you define which client/server pairs have their traffic intercepted for all services set to intercept; the rule applies to all intercepted services. For example, you can create rules to intercept traffic between all clients and a specific server, between a client subnet and a server subnet, or a specific client IP address and all servers.
Restricted intercept rules are useful in a rollout, prior to full production, where you only want to intercept a subset of the clients (or servers). After you are in full production mode, you can disable restricted intercept. It's also useful when troubleshooting an issue, because you can reduce the set of systems that are intercepted. If restricted intercept is enabled, only the traffic specified in these rules will be intercepted. All other traffic will be bypassed.
- In Blue Coat Sky, click the Configure tab.
- Select Acceleration > Restricted Intercept.
- Click Add new rule. A panel opens up for the rule definition.
- For Client IP, select one of the following:
- All—Intercepts traffic between any client and the Server IP specified in step 5 below.
- Enter IP or subnet—Intercepts traffic between a client IP address or subnet and the Server IP specified in step 5 below. Enter the IP address (in IPv4 or IPv6 format) or specify a subnet in IP/CIDR format (for example, 157.54.128.0/21 or 2001:DB8:0:DC00::/54).
- For Server IP, select one of the following:
- All—Intercepts traffic between any server and the Client IP specified in step 4 above.
- Enter IP or subnet—Intercepts traffic between a server IP address or subnet and the Client IP specified in step 4 above. Enter the IP address (in IPv4 or IPv6 format) or specify a subnet in IP/CIDR format.
- Click Done.
- Repeat steps 3-6 to create additional rules to restrict interception.
- Set Restricted Intercept to Enable.
- Click Commit all to save your intercept rules and settings.
Restricted intercept rules are ignored unless the Enable setting is selected. If your rules don't seem to be working, double-check this setting and make sure you have saved it (Commit all).
Use the Edit
Use the Delete
Use the Disable setting to ignore the intercept rules without deleting them.
What is the DNS Proxy?
The Domain Name Service (DNS) proxy performs a lookup of the DNS cache on the MACH5 appliance to determine if requests can be answered locally. If yes, the MACH5 responds to the DNS request. If not, the DNS proxy forwards the request to the DNS server list configured on the MACH5appliance.
To use the DNS proxy, the DNS service must be set to intercept on the Branch peers.
After the proxy identifies DNS traffic, the appliance uses the following techniques to control these connections:
What is Encrypted MAPI?
Blue Coat's encrypted MAPI solution provides the ability to transparently accelerate encrypted MAPI traffic between the Outlook client and the Exchange server. The ability to decrypt and encrypt MAPI is transparent to the user, with no knowledge of the user's password.
This feature assumes your acceleration network is set up as follows.

The encrypted MAPI acceleration feature expects the Outlook client to use the Simple and Protected Negotiation (SPNEGO) security protocol, and as a result the proxy will negotiate NTLM protocol on the client side and Kerberos on the server side. SPNEGO is used when a client application wants to authenticate to a remote server, but neither end is sure what authentication protocols the other supports.
What is the FTP Proxy?
The FTP proxy allows the MACH5 appliance to control FTP traffic. When an FTP client uploads or downloads files to/from an origin content server (OCS), the proxy identifies the traffic as FTP, allowing the appliance to control file transfers using the following techniques:
What is the HTTP Proxy?
The HTTP proxy controls the delivery of Web traffic on your network. After the proxy identifies HTTP traffic, the appliance uses the following techniques to control these connections:
Together, these techniques minimize latency and improve response times for Web page requests.
What are the Outlook Email Proxies?
The MACH5 appliance has two proxies that work together to accelerate Microsoft Outlook email traffic: Endpoint Mapper and MAPI.
What are the Streaming Media Proxies?
The streaming media proxies identify various types of streaming video and audio traffic that use real-time streaming protocol (RTSP), real-time messaging protocol (RTMP), or HTTP as transport. This allows the MACH5 appliance to filter, monitor, or limit streaming media traffic on your network. The streaming proxies use several optimization techniques to improve the quality of the streaming media.
Because video, audio, and other streaming media use a considerable amount of bandwidth—much more than Web traffic—you will probably want to use the streaming proxies to control this type of traffic. Without the proxy on a congested network, users are likely to experience problems such as jagged video, patchy audio, and unsynchronized video and audio as packets are dropped or arrive late. By using the proxy, you can save bandwidth, increase quality of service, and reduce pauses and buffering during playback.
The MACH5 appliance uses the following techniques to control streaming delivery:
Streaming Media Support
The MACH5 appliance offers five proxies for streaming media: Flash, MS Smooth, Windows Media, QuickTime,and Real Media. The following streaming media clients are supported:
Streaming media can be delivered in a real-time live media stream or a previously-recorded on-demand media stream. The MACH5 appliance supports both types of streaming media.
The streaming proxies function when the RTMP, RTSP, and HTTP proxy services are being intercepted.
Control Streaming Media Traffic
Without controls, streaming media can easily cause congestion on your network and disrupt mission-critical traffic.
|
What is the ISATAP Proxy?
When the MACH5 appliance encounters Intra-Site Automatic Tunnel Addressing Protocol (ISATAP) traffic, it decides whether to process the 6-in-4 packets with the ISATAP proxy or one of the traditional application proxies (HTTP, FTP, CIFS, etc.). To make the decision on which proxy to use, the MACH5 appliance identifies the service inside the encapsulated packet. If the MACH5 appliance is intercepting this service, the traffic is processed by one of the traditional application proxies. If the service is not intercepted, the MACH5 appliance uses the ISATAP proxy to optimize the IPv6 packet and payload over an ADN tunnel, assuming an ADN peer is found. Note that this proxy processes and optimizes all ISATAP traffic that is not handled by application proxies, including ICMP, UDP, TCP, and routing protocols. If an ADN peer is not found, the packet cannot be optimized; it is simply sent to its destination. 



The ISATAP proxy uses the following techniques to optimize the IPv6 packets:
- Byte caching
- Compression
The ISATAP proxy works differently than the application proxies: it processes individual packets instead of entire streams. It does not inspect the contents of the payload; it optimizes the entire packet.
Traffic that is processed by the ISATAP proxy appears in Active Sessions as the ISATAP tunnel service and the ISATAP proxy type. The Active Sessions report lists the IPv4 tunnel address (not the IPv6 destination) as the server address since the ISATAP proxy has no insight into the payload of the packet.
The ISATAP proxy is not enabled by default. Until you enable ISATAP, 6-in-4 packets will be bypassed.
Configure the ISATAP Proxy
The ISATAP proxy is disabled by default, so until you enable ISATAP, all 6-in-4 packets are bypassed. You can enable and configure the ISATAP proxy via the command-line interface (CLI). To use the ISATAP proxy, enable the following commands:
isatap adn-tunnel
isatap allow-intercept
If both of these settings are disabled, ISATAP traffic is bypassed. When both of these settings are enabled:
- If the service is intercepted, the ISATAP traffic is processed by the appropriate application proxy (HTTP, CIFS, FTP, etc.).
- If the service is not intercepted, the traffic is processed by the ISATAP proxy. Note that this proxy processes all ISATAP traffic that is not handled by application proxies, including ICMP, UDP, TCP, and routing protocols.
To enable full ISATAP functionality:
- Access the MACH5 CLI, with enable (write) access.
- Type conf t to go into configuration mode.
- At the #(config) prompt, type the following CLI commands:isatap adn-tunnel enableisatap allow-intercept enable
Typically, you would enable both CLI commands to process ISATAP traffic. Enabling one command but not the other results in different behavior, but you might want to do this for testing purposes.
- If adn-tunnel is enabled but allow-intercept is disabled, the ISATAP proxy processes all ISATAP traffic; the application proxies aren't used.
- If allow-intercept is enabled but adn-tunnel is disabled, the ISATAP proxy is not used; ISATAP traffic is either processed by the appropriate application proxy (if the service is intercepted) or is bypassed (if the service is not intercepted).
Byte caching and compression are automatically enabled for the ISATAP proxy. To disable them, use the following CLI commands:
isatap adn-tunnel adn-byte-cache disable
isatap adn-tunnel adn-compress disable
You can also change the priority of the ISATAP byte cache:
isatap adn-tunnel byte-cache-priority normal (default)
isatap adn-tunnel byte-cache-priority high
isatap adn-tunnel byte-cache-priority low
Why is ISATAP traffic being bypassed?
Problem: Some or all of the ISATAP traffic is being bypassed.
- The ISATAP connections are listed on the Bypassed Connections list on the Active Sessions report.
- In addition, in the output of the show ip-stat ip CLI command, the ISATAP packets delivered to ISATAP proxycounter shows 0 (zero) packets.
Resolution: If all ISATAP traffic is being bypassed, you have not yet enabled the two ISATAP options: allow-intercept and adn-tunnel. If only some of the ISATAP traffic is being bypassed, it is likely that you enabled allow-intercept but did not enable the adn-tunnel option. When adn-tunnel is disabled, the ISATAP proxy is not used: any traffic that would have been processed by this proxy is bypassed. For instructions on enabling ISATAP, .
ISATAP traffic destined for the ISATAP proxy would also be bypassed if the MACH5 appliance was unable to establish an ADN tunnel connection.
What is Caching?
With object caching, an object is saved locally so that it can be served for future requests without requiring retrieval from the origin content server (OCS) on the Web. These objects can be PDFs, videos, or images on a Web page, to name just a few. When objects are cached, the only traffic that needs to go across the Internet are permission checks (when required) and verification checks that ensure that the copy of the object in cache is still fresh. By allowing objects to be shared across requests and users, object caching greatly reduces the bandwidth required to retrieve contents, minimizes the latency associated with user requests, and significantly increases performance.
To improve response times for frequently accessed content, the MACH5 appliance stores the objects in a cache on its hard drives. The appliance can serve requests without contacting the OCS by retrieving content saved from a previous request made by the same client or another client.
Firewall concepts
There are a number of foundational concepts that are necessary to have a grasp of before delving into the details of how the FortiGate firewall works. Some of these concepts are consistent throughout the firewall industry and some of them are specific to more advanced firewalls such as the FortiGate. Having a solid grasp of these ideas and terms can give you a better idea of what your FortiGate firewall is capable of and how it will be able to fit within your networks architecture.
This chapter describes the following firewall concepts:
- What is a Firewall?
- FortiGate Modes
- How Packets are handled by FortiOS
- Interfaces and Zones
- IPv6
- NAT
- Quality of Service
What is a Firewall?
The term firewall originally referred to a wall intended to confine a fire or potential fire within a building. Later uses refer to similar structures, such as the metal sheet separating the engine compartment of a vehicle or aircraft from the passenger compartment.
A firewall can either be software-based or hardware-based and is used to help keep a network secure. Its primary objective is to control the incoming and outgoing network traffic by analyzing the data packets and determining whether it should be allowed through or not, based on a predetermined rule set. A network's firewall builds a bridge between an internal network that is assumed to be secure and trusted, and another network, usually an external (inter)network, such as the Internet, that is not assumed to be secure and trusted.
Network Layer or Packet Filter Firewalls
Stateless Firewalls
Stateless firewalls are the oldest form of these firewalls. They are faster and simple in design requiring less memory because they process each packet individually and don't require the resources necessary to hold onto packets like stateful firewalls. Stateful firewalls inspect each packet individually and check to see if it matches a predetermined set of rules. According to the matching rule the packet is either be allowed, dropped or rejected. In the case of a rejection an error message is sent to the source of the traffic. Each packet is inspected in isolation and information is only gathered from the packet itself. Simply put, if the packets were not specifically allowed according to the list of rules held by the firewall they were not getting through.
Stateful Firewalls
Stateful firewalls retain packets in memory so that they can maintain context about active sessions and make judgments about the state of an incoming packet's connection. This enables Stateful firewalls to determine if a packet is the start of a new connection, a part of an existing connection, or not part of any connection. If a packet is part of an existing connection based on comparison with the firewall's state table, it will be allowed to pass without further processing. If a packet does not match an existing connection, it will be evaluated according to the rules set for new connections. Predetermined rules are used in the same way as a stateless firewall but they can now work with the additional criteria of the state of the connection to the firewall.
 | Best Practices Tip for improving performance: Blocking the packets in a denied session can take more cpu processing resources than passing the traffic through. By putting denied sessions in the session table, they can be kept track of in the same way that allowed session are so that the FortiGate unit does not have to redetermine whether or not to deny all of the packets of a session individually. If the session is denied all packets of that session are also denied. In order to configure this you will need to use 2 CLI commands config system setting set ses-denied-traffic enable set block-session-timer <integer 1 - 300> (this determines in seconds how long, in seconds, the session is kept in the table)end |
Application Layer Firewalls
Application layer filtering is yet another approach and as the name implies it works primarily on the Application Layer of the OSI Model.
Application Layer Firewalls actually, for lack of a better term, understand certain applications and protocols. Examples would be FTP, DNS and HTTP. This form of filtration is able to check to see if the packets are actually behaving incorrectly or if the packets have been incorrectly formatted for the protocol that is indicated. This process also allows for the use of deep packet inspection and the sharing of functionality with Intrusion Prevention Systems (IPS).
Application-layer firewalls work on the application level of the TCP/IP stack (i.e., all browser traffic, or all telnet or ftp traffic), and may intercept all packets traveling to or from an application. They block other packets (usually dropping them without acknowledgment to the sender). Application firewalls work much like a packet filter but application filters apply filtering rules (allow/block) on a per process basis instead of filtering connections on a per port basis.
On inspecting all packets for improper content, firewalls can restrict or prevent outright the spread of networked computer worms and trojans. The additional inspection criteria can add extra latency to the forwarding of packets to their destination.
Proxy Servers
A proxy server is an appliance or application that acts as an intermediary for communicating between computers. A computer has a request for information. The packets are sent to the designated resource but before they can get there they are blocked by the proxy server saying that it will take the request and pass it on. The Proxy Server processes the request and if it is valid it passes onto the designated computer. The designated computer gets the packet and processes the request, sending the answer back to the proxy server. The proxy server sends the information back to the originating computer. It’s all a little like a situation with two people who refuse to talk directly with each other using someone else to take messages back and forth.
From a security stand point a Proxy Server can serve a few purposes:
- Protects the anonymity of the originating computer
- The two computers never deal directly with each other
- Packets that are not configured to be forwarded are dropped before reaching the destination computer.
- If malicious code is sent it will affect the Proxy server with out affecting the originating or sending computer.
Proxies can perform a number of roles including:
- Content Filtering
- Caching
- DNS proxy
- Bypassing Filters and Censorship
- Logging and eavesdropping
- Gateways to private networks
- Accessing service anonymously
Security Profiles
Unified Threat Management and Next Generation Firewall are terms originally coined by market research firms and refer to the concept of a comprehensive security solution provided in a single package. It is basically combining of what used to be accomplished by a number of different security technologies all under a single umbrella or in this case, a single device. On the FortiGate firewall this is achieved by the use of Security Profiles and optimized hardware.
In effect it is going from a previous style of firewall that included among its features:
- Gateway Network Firewall
- Routing
- VPN
To a more complete system that includes:
- Gateway Network Firewall
- Routing
- VPN
- Traffic Optimization
- Proxy Services
- Content Filtering
- Application Control
- Intrusion Protection
- Denial of Service Attack Protection
- Anti-virus
- Anti-spam
- Data Leak Prevention
- Endpoint Control of Security Applications
- Load Balancing
- WiFi Access Management
- Authentication Integration into Gateway Security
- Logging
- Reporting
Advantages of using Security Profiles
- Avoidance of multiple installations.
- Hardware requirements are fewer.
- Fewer hardware maintenance requirements.
- Less space required.
- Compatibility - multiple installations of products increase the probability of incompatibility between systems.
- Easier support and management.
- There is only one product to learn therefore a reduced requirement of technical knowledge.
- Only a single vendor so there are fewer support contracts and Service Level Agreements.
- Easier to incorporated into existing security architecture.
- Plug and play architecture.
- Web based GUI for administration.
Interfaces and Zones
A Firewall is a gateway device that may be the nexus point for more than 2 networks. The interface that the traffic is coming in on and should be going out on is a fundamental concern for the purposes of routing as well as security. Routing, policies and addresses are all associated with interfaces. The interface is essentially the connection point of a subnet to the FortiGate unit and once connected can be connected to other subnets.
Physical interfaces or not the only ones that need to be considered. There are also virtual interfaces that can be applied to security policies. VLANs are one such virtual interface. Interfaces if certain VPN tunnels are another.
Policies are the foundation of the traffic control in a firewall and the Interfaces and addressing is the foundation that policies are based upon. Using the identity of the interface that the traffic connects to the FortiGate unit tells the firewall the initial direction of the traffic. The direction of the traffic is one of the determining factors in deciding how the traffic should be dealt with. You can tell that interfaces are a fundamental part of the policies because, by default, this is the criteria that the policies are sorted by.
Zones are a mechanism that was created to help in the administration of the firewalls. If you have a FortiGate unit with a large number of ports and a large number of nodes in you network the chances are high that there is going to be some duplication of policies. Zones provide the option of logically grouping multiple virtual and physical FortiGate firewall interfaces. The zones can then be used to apply security policies to control the incoming and outgoing traffic on those interfaces. This helps to keep the administration of the firewall simple and maintain consistency.
For example you may have several floors of people and each of the port interfaces could go to a separate floor where it connects to a switch controlling a different subnet. The people may be on different subnets but in terms of security they have the same requirements. If there were 4 floors and 4 interfaces a separate policy would have to be written for each floor to be allowed out on to the Internet off the WAN1 interface. This is not too bad if that is all that is being done, but now start adding the use of more complicated policy scenarios with Security Profiles, then throw in a number of Identity based issues and then add the complication that people in that organization tend to move around in that building between floors with their notebook computers.
Each time a policy is created for each of those floors there is a chance of an inconsistency cropping up. Rather than make up an additional duplicate set of policies for each floor, a zone can be created that combines multiple interfaces. And then a single policy can created that uses that zone as one side of the traffic connection.
FortiGate Modes
The FortiGate unit has a choice of modes that it can be used in, either NAT/Route mode or Transparent mode. The FortiGate unit is able to operate as a firewall in both modes, but some of its features are limited in Transparent mode. It is always best to choose which mode you are going to be using at the beginning of the set up. Once you start configuring the device, if you want to change the mode you are going to lose all configuration settings in the change process.
NAT/Route Mode
NAT/Route mode is the most commonly used mode by a significant margin and is thus the default setting on the device. As the name implies the function of NAT is commonly used in this mode and is easily configured but there is no requirement to use NAT. The FortiGate unit performs network address translation before IP packets are sent to the destination network.
These are some of the characteristics of NAT/Route mode:
- Typically used when the FortiGate unit is a gateway between private and public networks.
- Can act as a router between multiple networks within a network infrastructure.
- When used, the FortiGate unit is visible to the networks that is connected to.
- Each logical interface is on a distinct subnet.
- Each Interface needs to be assigned a valid IP address for the subnet that it is connected to it.
Transparent Mode
Transparent mode is so named because the device is effectively transparent in that it does not appear on the network in the way that other network devices show as a nodes in the path of network traffic. Transparent mode is typically used to apply the FortiOS features such as Security Profiles etc. on a private network where the FortiGate unit will be behind an existing firewall or router.
These are some of the characteristics of Transparent mode:
- The FortiGate unit is invisible to the network.
- All of its interfaces are on the same subnet and share the same IP address.
- The FortiGate unit uses a Management IP address for the purposes of Administration.
- Still able to use NAT to a degree, but the configuration is less straightforward
In Transparent mode, you can also perform NAT by creating a security policy or policies that translates the source addresses of packets passing through the FortiGate unit as well as virtual IP addresses and/or IP pools.
How Packets are handled by FortiOS
To give you idea of what happens to a packet as it makes its way through the FortiGate unit here is a brief overview. This particular trip of the packet is starting on the Internet side of the FortiGate firewall and ends with the packet exiting to the Internal network. An outbound trip would be similar. At any point in the path if the packet is going through what would be considered a filtering process and if fails the filter check the packet is dropped and does not continue any further down the path.
This information is covered in more detail in other in the Troubleshooting chapter of the FortiOS Handbook in the Life of a Packet section.
The incoming packet arrives at the external interface. This process of entering the device is referred to as ingress.
Step #1 - Ingress
- Denial of Service Sensor
- IP integrity header checking
- IPsec connection check
- Destination NAT
- Routing
Step #2 - Stateful Inspection Engine
- Session Helpers
- Management Traffic
- SSL VPN
- User Authentication
- Traffic Shaping
- Session Tracking
- Policy lookup
Step #3 - Security Profiles scanning process
- Flow-based Inspection Engine
- IPS
- Application Control
- Data Leak Prevention
- Email Filter
- Web Filter
- Anti-virus
- Proxy-based Inspection Engine
- VoIP Inspection
- Data Leak Prevention
- Email Filter
- Web Filter
- Anti-virus
- ICAP
Step #4 - Egress
- IPsec
- Source NAT
- Routing
Access Control Lists
Access Control Lists (ACLs) in the FortiOS firmware could be considered a granular or more specifically targeted blacklist. These ACLs drop IPv4 or IPv6 packets at the physical network interface before the packets are analyzed by the CPU. On a busy appliance this can really help the performance.
The ACL feature is available on FortiGates with NP6-accelerated interfaces. ACL checking is one of the first things that happens to the packet and checking is done by the NP6 processor. The result is very efficient protection that does not use CPU or memory resources.
Incoming Interfaces
The configuration of the Access Control List allow you to specify which in interface theACL will be applied to. There is a hardware limitation that needs to be taken into account. The ACL is a Layer 2 function and is offloaded to the ISF hardware, therefore no CPU resources are used in the processing of the ACL. It is handled by the inside switch chip which can do hardware acceleration, increasing the performance of the FortiGate. The drawback is that the ACL function is only supported on switch fabric driven interfaces. It also cannot be applied to hardware switch interfaces or their members. Ports such as WAN1 or WAN2 that are found on some models that use network cards that connect to the CPU through a PCIe bus will not support ACL.
Addresses
Because the address portion of an entry is based on a FortiGate address object, id can be any of the address types used by the FortiGate, including address ranges. There is further granularity by specifying both the source and destination addresses. The traffic is blocked not on an either or basis of these addresses but the combination of the two, so that they both have to be correct for the traffic to be denied. Of course, If you want to block all of the traffic from a specific address all you have to do is make the destination address "all".
Because the blocking takes place at the interface based on the information in the packet header and before any processing such as NAT can take place, a slightly different approach may be required. For instance, if you are trying to protect a VIP which has an external address of x.x.x.x and is forwarded to an internal address of y.y.y.y, the destination address that should be used is x.x.x.x, because that is the address that will be in the packet's header when it hits the incoming interface.
Services
Further granulation of the filter by which the traffic will be denied is done by specifying which service the traffic will use.
IPv6
Internet Protocol version 6 (IPv6) will succeed IPv4 as the standard networking protocol of the Internet. IPv6 provides a number of advances over IPv4 but the primary reason for its replacing IPv4 is its limitation in addresses. IPv4 uses 32 bit addresses which means there is a theoretical limit of 2 to the power of 32. The IPv6 address scheme is based on a 128 bit address or a theoretical limit of 2 to the power of 128.
Possible Addresses:
- IPv4 = 4,294,967,296 (over 4 billion)
- IPv6 = 340,282,366,920,938,463,463,374,607,431,768,211,456 (over 340 undecillion - We had to look that term up. We didn’t know what a number followed by 36 digits was either)
Assuming a world population of approximately 8 billion people, IPv6 would allow for each individual to have approximately 42,535,295,865,117,200,000,000,000,000 devices with an IP address. That’s 42 quintillion devices.
There is little likelihood that you will ever need to worry about these numbers as any kind of serious limitation in addressing but they do give an idea of the scope of the difference in the available addressing.
Aside from the difference of possible addresses there is also the different formatting of the addresses that will need to be addressed.
A computer would view an IPv4 address as a 32 bit string of binary digits made up of 1s and 0s, broken up into 4 octets of 8 digits separated by a period “.”
Example:
10101100.00010000.11111110.00000001
To make number more user friendly for humans we translate this into decimal, again 4 octets separated by a period “.”which works out to:
172.16.254.1
A computer would view an IPv6 address as a 128 bit string of binary digits made up of 1s and 0s, broken up into 8 octets of 16 digits separated by a colon “:”
1000000000000001:0000110110111000:101011000001000:1111111000000001:0000000000000000:0000000000000000:0000000000000000:0000000000000000
To make number a little more user friendly for humans we translate this into hexadecimal, again 8 octets separated by a colon “:” which works out to:
8001:0DB8:AC10:FE01:0000:0000:0000:0000:
Because any four-digit group of zeros within an IPv6 address may be reduced to a single zero or altogether omitted, this address can be shortened further to:
8001:0DB8:AC10:FE01:0:0:0:0
or
8001:0DB8:AC10:FE01::
Some of the other benefits of IPv6 include:
- More efficient routing
- Reduced management requirement
- Stateless auto-reconfiguration of hosts
- Improved methods to change Internet Service Providers
- Better mobility support
- Multi-homing
- Security
- Scoped address: link-local, site-local and global address space
IPv6 in FortiOS
From an administrative point of view IPv6 works almost the same as IPv4 in FortiOS. The primary difference is the use IPv6 format for addresses. There is also no need for NAT if the FortiGate firewall is the interface between IPv6 networks. If the subnets attached to the FortiGate firewall are IPv6 and IPv4 NAT can be configured between the 2 different formats. This will involve either configuring a dual stack routing or IPv4 tunneling configuration. The reason for this is simple. NAT was developed primarily for the purpose of extending the number of usable IPv4 addresses. IPv6’s addressing allows for enough available addresses so the NAT is no longer necessary.
When configuring IPv6 in FortiOS, you can create a dual stack route or IPv4-IPv6 tunnel. A dual stack routing configuration implements dual IP layers, supporting both IPv4 and IPv6, in both hosts and routers. An IPv4-IPv6 tunnel is essentially similar, creating a tunnel that encapsulates IPv6 packets within IPv4 headers that carry these IPv6 packets over IPv4 tunnels. The FortiGate unit can also be easily integrated into an IPv6 network. Connecting the FortiGate unit to an IPv6 network is exactly the same as connecting it to an IPv4 network, the only difference is that you are using IPv6 addresses.
By default the IPv6 settings are not displayed in the Web-based Manager. It is just a matter of enabling the display of these feature to use them through the web interface. To enable them just go to System > Admin > Settings and select IPv6 Support on GUI. Once enabled, you will be able to use IPv6 addresses as well as the IPv4 addressing for the following FortiGate firewall features:
- Static routing
- Policy Routing
- Packet and network sniffing
- Dynamic routing (RIPv6, BGP4+, and OSPFv3)
- IPsec VPN
- DNS
- DHCP
- SSL VPN
- Network interface addressing
- Security Profiles protection
- Routing access lists and prefix lists
- NAT/Route and Transparent mode
- NAT 64 and NAT 66
- IPv6 tunnel over IPv4 and IPv4 tunnel over IPv6
- Logging and reporting
- Security policies
- SNMP
- Authentication
- Virtual IPs and groups
- IPv6 over SCTP
- IPv6-specific troubleshooting, such as ping6
Dual Stack routing configuration
Dual stack routing implements dual IP layers in hosts and routers, supporting both IPv6 and IPv4. A dual stack architecture supports both IPv4 and IPv6 traffic and routes the appropriate traffic as required to any device on the network. Administrators can update network components and applications to IPv6 on their own schedule, and even maintain some IPv4 support indefinitely if that is necessary. Devices that are on this type of network, and connect to the Internet, can query Internet DNS servers for both IPv4 and IPv6 addresses. If the Internet site supports IPv6, the device can easily connect using the IPv6 address. If the Internet site does not support IPv6, then the device can connect using the IPv4 addresses. In the FortiOS dual stack architecture it is not just the basic addressing functions that operate in both versions of IP. The other features of the appliance such as Security Profiles and routing can also use both IP stacks.
If an organization with a mixed network uses an Internet service provider that does not support IPv6, they can use an IPv6 tunnel broker to connect to IPv6 addresses that are on the Internet. FortiOS supports IPv6 tunneling over IPv4 networks to tunnel brokers. The tunnel broker extracts the IPv6 packets from the tunnel and routes them to their destinations.
IPv6 Tunneling
IPv6 Tunneling is the act of tunneling IPv6 packets from an IPv6 network through an IPv4 network to another IPv6 network. This is different than Network Address Translation (NAT) because once the packet reaches its final destination the true originating address of the sender will still be readable. The IPv6 packets are encapsulated within packets with IPv4 headers, which carry their IPv6 payload through the IPv4 network. This type of configuration is more appropriate for those who have completely transitional over to IPv6, but need an Internet connection, which is still mostly IPv4 addresses.
The key to IPv6 tunneling is the ability of the 2 devices, whether they are a host or a network device, to be dual stack compatible. They have to be able to work with both IPv4 and IPv6 at the same time. In the process the entry node of the tunnel portion of the path will create an encapsulating IPv4 header and transmit the encapsulated packet. The exit node at the end of the tunnel receives the encapsulated packet. The IPv4 header is removed. The IPv6 header is updated and the IPv6 packet is processed.
There are two types of tunnels in IPv6:
| Automatic tunnels | Automatic tunnels are configured by using IPv4 address information embedded in an IPv6 address – the IPv6 address of the destination host includes information about which IPv4 address the packet should be tunneled to. |
| Configured tunnels | Configured tunnels must be configured manually. These tunnels are used when using IPv6 addresses that do not have any embedded IPv4 information. The IPv6 and IPv4 addresses of the endpoints of the tunnel must be specified. |
Tunnel Configurations
There are a few ways in which the tunneling can be performed depending on which segment of the path between the end points of the session the encapsulation takes place.
| Network Device to Network Device | Dual stack capable devices connected by an IPv4 infrastructure can tunnel IPv6 packets between themselves. In this case, the tunnel spans one segment of the path taken by the IPv6 packets. |
| Host to Network Device | Dual stack capable hosts can tunnel IPv6 packets to an intermediary IPv6 or IPv4 network device that is reachable through an IPv4 infrastructure. This type of tunnel spans the first segment of the path taken by the IPv6 packets. |
| Host to Host | Dual stack capable hosts that are interconnected by an IPv4 infrastructure can tunnel IPv6 packets between themselves. In this case, the tunnel spans the entire path taken by the IPv6 packets. |
| Network Device to Host | Dual stack capable network devices can tunnel IPv6 packets to their final destination IPv6 or IPv4 host. This tunnel spans only the last segment of the path taken by the IPv6 packets. |
Regardless of whether the tunnel starts at a host or a network device, the node that does the encapsulation needs to maintain soft state information, such as the maximum transmission unit (MTU), about each tunnel in order to process the IPv6 packets.
Tunneling IPv6 through IPsec VPN
A variation on the tunneling IPv6 through IPv4 is using an IPsec VPN tunnel between to FortiGate devices. FortiOS supports IPv6 over IPsec. In this sort of scenario, 2 networks using IPv6 behind FortiGate units are separated by the Internet, which uses IPv4. An IPsec VPN tunnel is created between the 2 FortiGate units and a tunnel is created over the IPv4 based Internet but the traffic in the tunnel is IPv6. This has the additional advantage of make the traffic secure as well.
The Origins of NAT
In order to understand NAT it helps to know why it was created. At one time, every computer that was part of a network had to have it’s own addresses so that the other computers could talk to it. There were a few protocols in use at the time, some of which were only for use on a single network, but of those that were routable, the one that had become the standard for the Internet was IP (Internet Protocol) version 4.
When IP version 4 addressing was created nobody had any idea how many addresses would be needed. The total address range was based on the concept of 2 to the 32nd power, which works out to be 4 294 967 296 potential addresses. Once you eliminate some of those for reserved addresses, broadcast addresses, network addresses, multicasting, etc., you end up with a workable scope of about 3.2 million addressees. This was thought to be more than enough at the time. The designers were not expecting the explosion of personal computing, the World Wide Web or smart phones. As of the beginning of 2012, some estimate the number of computers in the world in the neighborhood of 1 billion, and most of those computer users are going to want to be on the Internet or Search the World Wide Web. In short, we ran out of addresses.
This problem of an address shortage was realized before we actually ran out, and in the mid 1990s 2 technical papers called RFCs numbered 1631 (http://www.ietf.org/rfc/rfc1631.txt) and 1918 (http://tools.ietf.org/html/rfc1918), proposed components of a method that would be used as a solution until a new addressing methodology could be implemented across the Internet infrastructure. For more information on this you can look up IP version 6.
RFC 1631 described a process that would allow networking devices to translate a single public address to multiple private IP addresses and RFC 1918 laid out the use of the private addresses. The addresses that were on the Internet (Public IP addresses) could not be duplicated for them to work as unique addresses, but behind a firewall, which most large institutions had, they could use their own Private IP addresses for internal use and the internal computers could share the external or Public IP address.
To give an idea on a small scale how this works, image that a company has a need for 200 computer addresses. Before Private IP addresses and NAT the company would have purchased a full Class C address range which would have been 254 usable IP addresses; wasting about 50 addresses. Now with NAT, that company only needs 1 IP address for its 200 computers and this leaves the rest of the IP addresses in that range available for other companies to do the same thing.
NAT gives better value than it would first appear because it is not 253 companies that can use 254 addresses but each of those 254 companies could set up their networking infrastructures to use up to thousands of Private IP addresses, more if they don’t all have to talk to the Internet at the same time. This process enabled the Internet to keep growing even though we technically have many more computers networked than we have addresses.
Dynamic NAT
Dynamic NAT maps the private IP addresses to the first available Public Address from a pool of possible Addresses. In the FortiGate firewall this can be done by using IP Pools.
Overloading
This is a form of Dynamic NAT that maps multiple private IP address to a single Public IP address but differentiates them by using a different port assignment. This is probably the most widely used version of NAT. This is also referred to as PAT (Port Address Translation) or Masquerading.
An example would be if you had a single IP address assigned to you by your ISP but had 50 or 60 computers on your local network.
Say the internal address of the interface connected to the ISP was 256.16.32.65 (again an impossible address) with 256.16.32.64 being the remote gateway. If you are using this form of NAT any time one of your computers accesses the Internet it will be seen from the Internet as 256.16.32.65. If you wish to test this go to 2 different computers and verify that they each have a different private IP address then go to a site that tells you your IP address such as www.ipchicken.com. You will see that the site gives the same result of 256.16.32.65, if it existed, as the public address for both computers.
As mentioned before this is sometimes called Port Address Translation because network device uses TCP ports to determine which internal IP address is associated with each session through the network device. For example, if you have a network with internal addresses ranging from 192.168.1.1 to 192.168.1.255 and you have 5 computers all trying to connect to a web site which is normally listening on port 80 all of them will appear to the remote web site to have the IP address of 256.16.32.65 but they will each have a different sending TCP port, with the port numbers being somewhere between 1 and 65 535, although the port numbers between 1 to 1024 are usually reserved or already in use. So it could be something like the following:
192.168.1.10 256.16.32.65: port 486
192.168.1.23 256.16.32.65: port 2409
192.168.1.56 256.16.32.65: port 53763
192.168.1.109 256.16.32.65: port 5548
192.168.1.201 256.16.32.65: port 4396
And the remote web server would send the responding traffic back based on those port numbers so the network device would be able to sort through the incoming traffic and pass it on to the correct computer.
Overlapping
Because everybody is using the relative same small selection of Private IP addresses it is inevitable that there will be two networks that share the same network range that will need to talk with each other. This happens most often over Virtual Private Networks or when one organization ends up merging with another. This is a case where a private IP address may be translated into a different private IP address so there are no issues with conflict of addresses or confusion in terms of routing.
An example of this would be when you have a Main office that is using an IP range of 172.16.0.1 to 172.20.255.255 connecting through a VPN to a recently acquired branch office that is already running with an IP range of 172.17.1.1 to 172.17.255.255. Both of these ranges are perfectly valid but because the Branch office range is included in the Main Office range any time the system from the Main office try to connect to an address in the Branch Office the routing the system will not send the packet to the default gateway because according to the routing table the address is in its own subnet.
The plan here would be to NAT in both directions so that traffic from neither side of the firewall would be in conflict and they would be able to route the traffic. Everything coming from the Branch Office could be assigned an address in the 192.168.1.1 to 192.168.1.255 range and everything from the Main office going to the Branch Office could be assigned to an address in the 192.168.10.1 to 192.168.10.255 range.
Static NAT
In Static NAT one internal IP address is always mapped to the same public IP address.
In FortiGate firewall configurations this is most commonly done with the use of Virtual IP addressing.
An example would be if you had a small range of IP addresses assigned to you by your ISP and you wished to use one of those IP address exclusively for a particular server such as an email server.
Say the internal address of the Email server was 192.168.12.25 and the Public IP address from your assigned addresses range from 256.16.32.65 to 256.16.32.127. Many readers will notice that because one of the numbers is above 255 that this is not a real Public IP address. The Address that you have assigned to the interface connected to your ISP is 256.16.32.66, with 256.16.32.65 being the remote gateway. You wish to use the address of 256.16.32.70 exclusively for your email server.
When using a Virtual IP address you set the external IP address of 256.16.32.70 to map to 192.168.12.25. This means that any traffic being sent to the public address of 256.16.32.70 will be directed to the internal computer at the address of 192.168.12.25
When using a Virtual IP address, this will have the added function that when ever traffic goes from 192.168.12.25 to the Internet it will appear to the recipient of that traffic at the other end as coming from 256.16.32.70.
You should note that if you use Virtual IP addressing with the Port Forwarding enabled you do not get this reciprocal effect and must use IP pools to make sure that the outbound traffic uses the specified IP address.
Benefits of NAT
More IP addresses Available while Conserving Public IP Addresses
As explained earlier, this was the original intent of the technology and does not need to be gone into further.
Financial Savings
Because an organization does not have to purchase IP addresses for every computer in use there is a significant cost savings due to using the process of Network Address Translation.
Security Enhancements
One of the side benefits of the process of NAT is an improvement in security. Individual computers are harder to target from the outside and if port forwarding is being used computers on the inside of a firewall are less likely to have unmonitored open ports accessible from the Internet.
Ease of Compartmentalization of Your Network
With a large available pool of IP addresses to use internally a network administrator can arrange things to be compartmentalized in a rational and easily remembered fashion and networks can be broken apart easily to isolate for reasons of network performance and security.
Example
You have a large organization that for security reasons has certain departments that do not share network resources.
You can have the main section of the organization set up as follows;
| Network Devices | 192.168.1.1 to 192.168.1.25 |
| Internal Servers | 192.168.1.26 to 192.168.1.50 |
| Printers | 192.168.1.51 to 192.168.1.75 |
| Administration Personnel | 192.168.1.76 to 192.168.1.100 |
| Sales People | 192.168.1.101 to 192.168.1.200 |
| Marketing | 192.168.1.201 to 192.168.1.250 |
You could then have the following groups broken off into separate subnets:
| Accounting | 192.168.100.1 to 192.168.100.255 |
| Research and Development | 172.16.1.1 to 172.16.255.255 |
| Executive Management | 192.168.50.1 to 192.168.50.255 |
| Web sites and Email Servers | 10.0.50.1 to 10.0.50.255 |
These addresses do not have to be assigned right away but can be used as planned ranges.
NAT in Transparent Mode
Similar to operating in NAT mode, when operating a FortiGate unit in Transparent mode you can add security policies and:
- Enable NAT to translate the source addresses of packets as they pass through the FortiGate unit.
- Add virtual IPs to translate destination addresses of packets as they pass through the FortiGate unit.
- Add IP pools as required for source address translation
A FortiGate unit operating in Transparent mode normally has only one IP address - the management IP. To support NAT in Transparent mode, you can add a second management IP. These two management IPs must be on different subnets. When you add two management IP addresses, all FortiGate unit network interfaces will respond to connections to both of these IP addresses.
Use the following steps to configure NAT in Transparent mode:
- Add two management IPs
- Add an IP pool to the WAN1 interface
- Add an Internal to WAN1 security policy
You can add the security policy from the web-based manager and then use the CLI to enable NAT and add the IP pool.
The usual practice of NATing in transparent mode makes use of two management IP addresses that are on different subnets, but this is not an essential requirement in every case.
If there is a router between the client systems and the FortiGate unit you can use the router’s capabilities of tracking sessions to assign NATed addresses from an IP pool to the clients even if the assigned address don’t belong to a subnet on your network.
Example
Client computer has an IP address of 1.1.1.33 on the subnet 1.1.1.0/24.
Router “A” sits between the client computer and the FortiGate (in Transparent mode) with the IP address of 1.1.1.1 on the client’s side of the router and the IP address of 192.168.1.211 on the FortiGate’s side of the router.
Use NAT to assign addresses from an address pool of 9.9.9.1 to 9.9.9.99 to traffic coming from gateway of 192.168.1.211.
To enable the return traffic to get to the original computer, set up a static route than assigns any traffic with a destination of 9.9.9.0/24 to go through the 192.168.1.211 gateway. As long as the session for the outgoing traffic has been maintained, communication between the client computer and the external system on the other side of the FortiGate will work.
Central NAT Table
The central NAT table enables you to define, and control with more granularity, the address translation performed by the FortiGate unit. With the NAT table, you can define the rules which dictate the source address or address group and which IP pool the destination address uses.
While similar in functionality to IP pools, where a single address is translated to an alternate address from a range of IP addresses, with IP pools there is no control over the translated port. When using the IP pool for source NAT, you can define a fixed port to guarantee the source port number is unchanged. If no fix port is defined, the port translation is randomly chosen by the FortiGate unit. With the central NAT table, you have full control over both the IP address and port translation.
The FortiGate unit reads the NAT rules in a top-down methodology, until it hits a matching rule for the incoming address. This enables you to create multiple NAT policies that dictate which IP pool is used based on the source address. The NAT policies can be rearranged within the policy list as well. NAT policies are applied to network traffic after a security policy.
NAT 64 and NAT46
NAT64 and NAT46 are the terms used to refer to the mechanism that allows IPv6 addressed hosts to communicate with IPv4 addressed hosts and vice-versa. Without such a mechanism an IPv6 node on a network such as a corporate LAN would not be able to communicate with a web site that was still in a IPv4 only environment and IPv4 environments would not be able to connect to IPv6 networks.
One of these setups involves having at least 2 interfaces, 1 on an IPv4 network and 1 on an IPv6 network. The NAT64 server synthesizes AAAA records, used by IPv6 from A records used by IPv4. This way client-server and peer to peer communications will be able to work between an IPv6 only client and an IPv4 server without making changes to either of the end nodes in the communication transaction. The IPv6 network attached to the FortiGate unit should be a 32 bit segment, (for instance 64:ff9b::/96, see RFC 6052 and RFC 6146). IPv4 address will be embedded into the communications from the IPv6 client.
Because the IPv6 range of addresses is so much larger than the IPv4 range, a one to one mapping is not feasible. Therefore the NAT64 function is required to maintain any IPv6 to IPv4 mappings that it synthesizes. This can be done either statically by the administrator or automatically by the service as the packets from the IPv6 network go through the device. The first method would be a stateless translation and the second would be a stateful translation. NAT64 is designed for communication initiated from IPv6 hosts to IPv4 addresses. It is address mapping like this that allows the reverse to occur between established connections. The stateless or manual method is an appropriate solution when the NAT64 translation is taking place in front of legacy IPv4 servers to allow those specific servers to be accessed by remote IPv6-only clients. The stateful or automatic solution is best used closer to the client side when you have to allow some specific IPv6 clients to talk to any of the IPv4-only servers on the Internet.
There are currently issues with NAT64 not being able to make everything accessible. Examples would be SIP, Skype, MSN, Goggle talk, and sites with IPv4 literals. IPv4 literals being IPv4 addresses that are imbedded into content rather than a FQDN.
Policies that employ NAT64 or NAT46 can be configured from the web-based manager as long as the feature is enabled using the Features setting found at System > Config > Features.
- To create a NAT64 policy go to Policy > Policy > NAT64 Policy and select Create New.
- To create a NAT46 policy go to Policy > Policy > NAT46 Policy and select Create New.
The difference between these NAT policies and regular policies is that there is no option to use the security profiles and sensors.
NAT 66
NAT 66 is Network Address Translation between 2 IPv6 network. The basic idea behind NAT 66 is no different than the regular NAT between IPv4 networks that we are all used to. The difference are in the mechanics of how it is performed, mainly because of the complexity and size of the addresses that are being dealt with.
In an IPv4 world, the reason for the use of NAT was usually one or a combination of the following 3 reasons:
- Improved security - actual addresses behind NAT are virtually hidden
- Amplification of addresses - hundreds of computers can use as little as a single public IP address
- Internal address stability - there is control of internal addressing. The addresses can stay the same even if Internet Service Providers change.
In these days of security awareness the protective properties of NAT are not something that are not normally depended on by themselves to defend a network and with the vastly enlarged IPv6 address scope there is no longer a need to amplify the available addresses. However, the desire to have internal address control still exists. The most common reason for using NAT66 is likely to be the maintaining of the existing address scheme of the internal network despite changes outside of it. Imagine that you have an internal network of 2000 IP addresses and one day the company changes its ISP and thus the addresses assigned to it. Even if most of the addressing is handled by DHCP, changing the address scheme is going to have an impact on operations.
Addressing stability can be achieved by:
- Keeping the same provider - this would depend on the reason for the change. If the cost of this provider has become too expensive this is unlikely. If the ISP is out of business it becomes impossible.
- Transfer the addresses from the old provider to the new one - There is little motivation for an ISP to do you a favor for not doing business with them.
- Get your own autonomous system number - this can be too expensive for smaller organizations.
- NAT - this is the only one on the list that is in the control of IT.
There are differences between NAT66 and IPv4 NAT. Because there is no shortage of addresses most organizations will be given a /48 network that can be translated into another /48 network. This allows for a one to one translation, no need for port forwarding. This is a good thing because port forwarding is more complicated in IPv6. In fact, NAT66 will actually just be the rewriting of the prefix on the address.
Example
If your current IPv6 address is
2001:db8:cafe::/48
you could change it to
2001:db8:fea7::/48
There is an exception to the one to one translation. NAT66 cannot translate internal networks that contain 0xffff in bits 49 through 63 - this is due to the way checksums are calculated in TCP/IP: they use the one's-complement representation of numbers which assigns the value zero to both 0x0000 and 0xffff.
How FortiOS differentiates sessions when NATing
The basics of NAT are fairly simple. Many private addresses get translated into a smaller number of public addresses, often just one. The trick is how the FortiGate keeps track of the return traffic because the web server, or what ever device that was out on the Internet is going to be sending traffic back not to the private address behind the FortiGate but to the IP address of the interface on the public side of the FortiGate.
The way this is done is by making each session unique. Most of the attributes that are available in the network packets cannot be changed without changing where the packet will go but because the source port has to be changed anyway in case two computer on the network used the same source port this is a useful way of making each listing of network attributes a unique combination. As a packet goes through the NAT process FortiOS assigns different source ports for each of the internally initiated sessions and keeping track of which port was used for each device in a database until the session has ended. It then becomes a matter of how the port number is selected.
In a very simple example of an environment using NAT, we will use a fictitious university with a rather large student population. So large in fact that they use a subnet of 10.0.0.0/8 as their subnet for workstation IP addresses. All of these private IP addresses are NATed out a single IP address. To keep the number of numeric values in this example from getting to a confusing level, we'll just us "u.u.u.1" to refer to the public IP address of the University and the IP address of the web server on the Internet will be "w.w.w.1".
Student A (IP address 10.1.1.56) sends an HTML request to a web server on the Internet with the IP address w.w.w.1. The applicable networking information in the packet breaks down as follows:
| Attribute | Original Packet | Packet after NATing |
|---|---|---|
| Source IP address or src-ip | 10.1.1.56 | u.u.u.1 |
| Destination IP address or dst-ip: | w.w.w.1 | w.w.w.1 |
| Source port or src-port: | 10000 | 46372 |
| Destination port or dst-port | 80 | 80 |
The source IP address is now that of the public facing interface of the FortiGate and source port number is an unused TCP port number on the FortiGate chosen by the FortiGate. Of these variable the only one the that FortiGate can really change and still have the packet reach the correct destination, in both directions, is the source port number.
There are a few methods of assigning the port number. First we'll look at the methods that are or have been used in the industry but aren't used by Fortinet.
Global pool
This method of differentiation focuses on the attribute of the source port number. In this approach a single pool of potential port numbers is set aside for the purposes of NAT. As a pool number is assigned, it is removed from the pool so that two sessions from different computers can not using the same port number. Once the session is over and no longer in use by the computer, the port number is put back into the pool where it can be assigned again.
Example global pool:
| Hexidecimal | Decimal | |
|---|---|---|
| Start or range | 0x7000 | 28672 |
| End end of range | 0xF000 | 61440 |
| Possible ports in range | 215 | 32768 |
This is a simple approach to implement and is good if the number of connections in unlike to reach the pool size. It would be okay for home use, but our example is for a university using 10.1.1.0/8 as a subnet. That means 16,777,214 possible IP addresses; more than this method can handle.
Fortinet does not use this method.
Global per protocol
This method uses the attributes source port number and type of protocol to differentiate between sessions.This approach is a variation of the first one. An additional piece of information is refered to in the packet that describes the protocol. For instance UDP or TCP. This could effectively double the number of potential addresses to NAT.
Example:
Here are two possible packets that would be considered different by the FortiGate so that any responses from the web server would make it back to their correct original sender.
From Student A
| Attribute | Original Packet | Packet after NATing |
|---|---|---|
| Source IP address or src-ip | 10.1.1.56 | u.u.u.1 |
| Destination IP address or dst-ip: | w.w.w.1 | w.w.w.1 |
| Protocol | tcp | tcp |
| Source port or src-port: | 10000 | 46372 |
| Destination port or dst-port | 80 | 80 |
From Student B
| Attribute | Original Packet | Packet after NATing |
|---|---|---|
| Source IP address or src-ip | 10.5.1.233 | u.u.u.1 |
| Destination IP address or dst-ip: | w.w.w.1 | w.w.w.1 |
| Protocol | udp | udp |
| Source port or src-port: | 26785 | 46372 |
| Destination port or dst-port | 80 | 80 |
Even though the source port is the same, because the protocol is different they are considered to be from different sessions and different computers.
The drawback is that it would depend on the protocols being used be evenly distributed between TCP and UDP. Even if this was the case the number would only double; reaching an upper limit of 65,536 possible connections. That number is still far short of the possible more than 16 million for an IP subnet with an eight bit subnet mask like the one in our example.
Fortinet does not use this method.
Per NAT IP Pool
This approach adds on to the previous one by adding another variable. In this case that variable is the IP addresses on the public side of the FortiGate. By having a pool of IP addresses to assign as the source IP address when NATing, the same number that was potentially available for the Global per protocol method can be multiplied by the number of external IP addresses in the pool. If you can assign a second IP address to the pool, you can double the potential number of sessions.
Example:
In this example it will be assumed that the FortiGate has 2 IP addresses that it can use. This could happen either by using two ISPs, or by having a pool of IP addresses assigned to a single interface. For simplicity will will refer to these IP public IP addresses as u.u.u.1 and u.u.u.2.
Here are two possible packets that would be considered different by the FortiGate so that any responses from the web server would make it back to their correct original sender.
From Student A
| Attribute | Original Packet | Packet after NATing |
|---|---|---|
| Source IP address or src-ip | 10.1.1.56 | u.u.u.1 |
| Destination IP address or dst-ip: | w.w.w.1 | w.w.w.1 |
| Protocol | tcp | tcp |
| Source port or src-port: | 10000 | 46372 |
| Destination port or dst-port | 80 | 80 |
From Student B
| Attribute | Original Packet | Packet after NATing |
|---|---|---|
| Source IP address or src-ip | 10.5.1.233 | u.u.u.2 |
| Destination IP address or dst-ip: | w.w.w.1 | w.w.w.1 |
| Protocol | tcp | tcp |
| Source port or src-port: | 26785 | 46372 |
| Destination port or dst-port | 80 | 80 |
In this example we even made the protocl the same. After the NATing process all of the variables are the same except the sourse addresss. This is still going to make it bake to the original sender.
The drawback is that if you have only one IP address for the purposes of NATing this method does not gain you anything over the last method. Or if you do have multiple IP addresses to use it will still take quite a few to reach the 16 million possible that the subnet is capable of handling.
Fortinet does not use this method.
Per NAT IP, destination IP, port, and protocol
This is the approach that FortiOS uses.
It uses all of the differentiation point of the previous methods, NAT IP, port number and protocol, but the additonal information point of the destination IP is also used. So now the network information points in the packet that the FortiGate keeps in its database to differentiate between sessions is:
- Public IP address of the FortiGate assigned by NATing
- Protocol of the traffic
- Source port assigned by the FortiGate
- Destination IP address of the packet
The last one is an especially good way to differentiate because as a theortical number, the upper limit on that is the numbers of Public IP addresses on the whole of the Internet. Chances are that while a large number of session from inside the University will be going to a small group of sites such as Google, Youtube, Facebook and some others it is unlikely that they will all be going to them at the same time.
Example:
In this example it will be assumed that the FortiGate has only one IP address.Two possible packets will be described. The only difference in the attributes recorded will be the destination of the HTML request.These packets are still considered to be from differnt sessions and any responses will make it back to the correct computer.
From Student A
| Attribute | Original Packet | Packet after NATing |
|---|---|---|
| Source IP address or src-ip | 10.1.1.56 | u.u.u.1 |
| Destination IP address or dst-ip: | w.w.w.1 | w.w.w.1 |
| Protocol | tcp | tcp |
| Source port or src-port: | 10000 | 46372 |
| Destination port or dst-port | 80 | 80 |
From Student B
| Attribute | Original Packet | Packet after NATing |
|---|---|---|
| Source IP address or src-ip | 10.5.1.233 | u.u.u.1 |
| Destination IP address or dst-ip: | w.w.w.2 | w.w.w.2 |
| Protocol | tcp | tcp |
| Source port or src-port: | 26785 | 46372 |
| Destination port or dst-port | 80 | 80 |
The reason that these attributes are used to determine defferentiation between traffic is based on how the indexes for the sessions are recorded in the database. When a TCP connection is made through a FortiGate unit, a session is created and two indexes are created for the session. The FortiGate unit uses these indexes to guide matching traffic to the session.
This following could be the session record for the TCP connection in the first example.
| Attribute | Outgoing Traffic | Returning Traffic |
|---|---|---|
| Source IP address | 10.78.33.97 (internal address) | w.w.w.1 |
| Destination address | w.w.w.1 | u.u.u.1 |
| Protocol | tcp | tcp |
| Source port |
10000 (from original computer)
46372 (assigned by NAT)
| 80 |
| Destination port | 80 | 46372 (FortiGate assigned port) |
Using the FortiGate's approach for session differentiation, FortiOS only has to ensure that the assigned port, along with the other four attributes is a unique combination to identify the session. So for example, if Student A simultaneously makes a HTTP(port 80) connection and a HTTPS(port 443) connection the same web server this would create another session and the index in the reply direction would be:
| Attribute | Outgoing Traffic | Returning Traffic |
|---|---|---|
| Source IP address | 10.78.33.97 (internal address) | w.w.w.1 |
| Destination address | w.w.w.1 | u.u.u.1 |
| Protocol | tcp | tcp |
| Source port |
10000 (from original computer)
46372 (assigned by NAT)
| 443 |
| Destination port | 443 | 46372 (FortiGate assigned port) |
These two sessions are different and acceptable because of the different source port numbers on the returning traffic or the destination port depending on the direction of the traffic.
Calculations for possible session numbers
The result of using these four attributes instead of just the one that was originally used is a large increase in the number of possible unique combinations.For those who love math, the maximum number of simultaneous connections that can be supported is:
N x R x P x D x Dp
where:
- N is the number of NAT IP addresses
- R is the port range,
- P is the number of protocols,
- D is the number of unique destination IP addresses
- Dp the number of unique destination ports.
As a rough example let's do some basic calculations
- N - In our existing example we have already stated that there is only one public IP address that is being used by NAT. Realistically, for a university this number would likely be larger, but we're keeping it simple.
N = 1
R - The port range for our example has already been describe and we will keep it the same.
R = 32768
P - While there are a few protocols that are involved in Internet traffic we will limit this calculation just to TCP traffic.
P = 1
D - As mentioned before the number of unique destination addresses is growing larger every day,so figureing out the upper limit of that numbe would be difficult to say the least. Instead we will make the assumption that most of the university students, do to their shared interest and similar demographic will concentrate most of their web browsing to the same sites; sites such as YouTube, Facebook, Google, Twitter, Instagram, Wikipedia etc. This is not even taking into account the fact that many of these popular sites use load balancing and multiple IP addresses. As an arbatrary number let's use the number 25.
D = 25
Dp - To keep things simple it is tempting to limit the destiation port to port 80, the one that many associate with web browsing, but this would not be realistic. the use of HTTPS, port 443 is on the rise. There is also email, DNS, FTP, NTP and a number of other background services that we use without thinking too closely about. Let's keep it small and say ten of them.
Dp = 10
The math on this very conservative calculation is:
1 x 32768 x 1 x 25 x 10 = 8,192,000 possible NAT sessions
When you take into account that the chances of everybody being online at the same time, going only to one of those 25 sites and not millions of others, and using only TCP not UDP or any of the other protocols, it starts to look like this method may provide enough potential unique sessions even for a subnet as large as the one described.
IP Pools
IP Pools are a mechanism that allow sessions leaving the FortiGate Firewall to use NAT. An IP pool defines a single IP address or a range of IP addresses to be used as the source address for the duration of the session. These assigned addresses will be used instead of the IP address assigned to that FortiGate interface.
 | When using IP pools for NATing, there is a limitation that must be taken into account. In order for communication to be successful in both directions, it is normal for the source address in the packet header assigned by the NAT process to be an address that is associated with the interface that the traffic is going through. For example, if traffic is going out an interface with the IP address 172.16.100.1, packets would be NATed so that the source IP address would be 172.16.100.1. This way the returning traffic will be directed to the same interface on the same FortiGate that the traffic left from. Even if the packets are assigned a source address that is associated with another interface on the same FortiGate this can cause issues with asymmetrical routing. It is possible to configure the NATed source IP address to be different than the IP address of the interface but you have to make sure that the routing rules of the surrounding network devices take this unorthodox approach into consideration. |
There are 4 types of IP Pools that can be configured on the FortiGate firewall:
- One-to-One - in this case the only internal address used by the external address is the internal address that it is mapped to.
- Overload - this is the default setting. Internal addresses other than the one designated in the policy can use this address for the purposes of NAT.
- Fixed Port Range - rather than a single address to be used, there is a range of addresses that can be used as the NAT address. These addresses are randomly assigned as the connections are made.
- Port Block Allocation - this setting is used to allocate a block of port numbers for IP pool users. Two variables will also have to be set. The block size can be set from 64 to 4096 and as the name implies describes the number of ports in one block of port numbers. The number of blocks per user determines how many of these blocks will be assigned. This number can range from 1 to 128.
| Be careful when calculating the values of the variables. The maximum number of ports that are available on an address is 65,536. If you chose the maximum value for both variables you will get a number far in excess of the available port numbers. 4096 x 128 = 524,288 |
One of the more common examples is when you have an email server behind your FortiGate firewall and the range of IP addresses assigned to you by your ISP is more than one. If an organization is assigned multiple IP addresses it is normally considered a best practice to assign a specific address other than the one used for the Firewall to the mail server. However, when normal NAT is used the address assigned to the firewall is also assigned to any outbound sessions. Anti-spam services match the source IP address of mail traffic that they receive to the MX record on DNS servers as an indicator for spam. If there is a mismatch the mail may not get through so there is a need to make sure that the NATed address assigned matches the MX record.
You can also use the Central NAT table as a way to configure IP pools.
Source IP address and IP pool address matching when using a range
When the source addresses are translated to an IP pool that is a range of addresses, one of the following three cases may occur:
Scenario 1:
The number of source addresses equals that of IP pool addresses
In this case, the FortiGate unit always matches the IP addressed one to one.
If you enable fixed port in such a case, the FortiGate unit preserves the original source port. This may cause conflicts if more than one security policy uses the same IP pool, or the same IP addresses are used in more than one IP pool.
Scenario 2:
The number of source addresses is more than that of IP pool addresses
In this case, the FortiGate unit translates IP addresses using a wrap-around mechanism. If you enable fixed port in such a case, the FortiGate unit preserves the original source port. But conflicts may occur since users may have different sessions using the same TCP 5 tuples.
Scenario 3:
The number of source addresses is fewer than that of IP pool addresses
In this case, some of the IP pool addresses are used and the rest of them are not be used.
ARP Replies
If a FortiGate firewall interface IP address overlaps with one or more IP pool address ranges, the interface responds to ARP requests for all of the IP addresses in the overlapping IP pools. For example, consider a FortiGate unit with the following IP addresses for the port1 and port2 interfaces:
- port1 IP address: 1.1.1.1/255.255.255.0 (range is 1.1.1.0-1.1.1.255)
- port2 IP address: 2.2.2.2/255.255.255.0 (range is 2.2.2.0-2.2.2.255)
And the following IP pools:
- IP_pool_1: 1.1.1.10-1.1.1.20
- IP_pool_2: 2.2.2.10-2.2.2.20
- IP_pool_3: 2.2.2.30-2.2.2.40
The port1 interface overlap IP range with IP_pool_1 is:
(1.1.1.0-1.1.1.255) and (1.1.1.10-1.1.1.20) = 1.1.1.10-1.1.1.20
The port2 interface overlap IP range with IP_pool_2 is:
(2.2.2.0-2.2.2.255) & (2.2.2.10-2.2.2.20) = 2.2.2.10-2.2.2.20
The port2 interface overlap IP range with IP_pool_3 is:
(2.2.2.0-2.2.2.255) & (2.2.2.30-2.2.2.40) = 2.2.2.30-2.2.2.40
And the result is:
- The port1 interface answers ARP requests for 1.1.1.10-1.1.1.20
- The port2 interface answers ARP requests for 2.2.2.10-2.2.2.20 and for 2.2.2.30-2.2.2.40
Select Enable NAT in a security policy and then select Dynamic IP Pool. Select an IP pool to translate the source address of packets leaving the FortiGate unit to an address randomly selected from the IP pool. Whether or not the external address of an IP Pool will respond to an ARP request can be disabled. You might want to disable the ability to responded to ARP requests so that these address cannot be used as a way into your network or show up on a port scan.
IP pools and zones
Because IP pools are associated with individual interfaces IP pools cannot be set up for a zone. IP pools are connected to individual interfaces.
Fixed Port
Some network configurations do not operate correctly if a NAT policy translates the source port of packets used by the connection. NAT translates source ports to keep track of connections for a particular service.
However, enabling the use of a fixed port means that only one connection can be supported through the firewall for this service. To be able to support multiple connections, add an IP pool, and then select Dynamic IP pool in the policy. The firewall randomly selects an IP address from the IP pool and assigns it to each connection. In this case, the number of connections that the firewall can support is limited by the number of IP addresses in the IP pool.
Match-VIP
The match-vip feature allows the FortiGate unit to log virtual IP traffic that gets implicitly dropped. This feature eliminates the need to create two policies for virtual IPs; one that allows the virtual IP, and the other to get proper log entry for DROP rules.
For example, you have a virtual IP security policy and enabled the match-vip feature; the virtual IP traffic that is not matched by the policy is now caught.
The match-vip feature is available only in the CLI. By default, the feature is disabled.
IP
Internet Protocol (IP) is the primary part of the Network Layer of the OSI Model that is responsible for routing traffic across network boundaries. It is the protocol that is responsible for addressing. IPv4 is probable the version that most people are familiar with and it has been around since 1974. IPv6 is its current successor and due to a shortage of available IPv4 addresses compared to the explosive increase in the number of devices that use IP addresses, IPv6 is rapidly increasing in use.
When IP is chosen as the protocol type the available option to further specify the protocol is the protocol number. This is used to narrow down which protocol within the Internet Protocol Suite and provide a more granular control.
Protocol Number
IP is responsible for more than the address that it is most commonly associated with and there are a number of associated protocols that make up the Network Layer. While there are not 256 of them, the field that identifies them is a numeric value between 0 and 256.
In the Internet Protocol version 4 (IPv4) [RFC791] there is a field called “Protocol” to identify the next level protocol. This is an 8 bit field. In Internet Protocol version 6 (IPv6) [RFC2460], this field is called the “Next Header” field.
Protocol Numbers
| # | Protocol | Protocol's Full Name |
|---|---|---|
| 0 | HOPOPT | IPv6 Hop-by-Hop Option |
| 1 | ICMP | Internet Control Message Protocol |
| 2 | IGMP | Internet Group Management |
| 3 | GGP | Gateway-to-Gateway |
| 4 | IPv4 | IPv4 encapsulation Protocol |
| 5 | ST | Stream |
| 6 | TCP | Transmission Control Protocol |
| 7 | CBT | CBT |
| 8 | EGP | Exterior Gateway Protocol |
| 9 | IGP | Any private interior gateway (used by Cisco for their IGRP) |
| 10 | BBN-RCC-MON | BBN RCC Monitoring |
| 11 | NVP-II | Network Voice Protocol |
| 12 | PUP | PUP |
| 13 | ARGUS | ARGUS |
| 14 | EMCON | EMCON |
| 15 | XNET | Cross Net Debugger |
| 16 | CHAOS | Chaos |
| 17 | UDP | User Datagram Protocol |
| 18 | MUX | Multiplexing |
| 19 | DCN-MEAS | DCN Measurement Subsystems |
| 20 | HMP | Host Monitoring |
| 21 | PRM | Packet Radio Measurement |
| 22 | XNS-IDP | XEROX NS IDP |
| 23 | TRUNK-1 | Trunk-1 |
| 24 | TRUNK-2 | Trunk-2 |
| 25 | LEAF-1 | Leaf-1 |
| 26 | LEAF-2 | Leaf-2 |
| 27 | RDP | Reliable Data Protocol |
| 28 | IRTP | Internet Reliable Transaction |
| 29 | ISO-TP4 | ISO Transport Protocol Class 4 |
| 30 | NETBLT | Bulk Data Transfer Protocol |
| 31 | MFE-NSP | MFE Network Services Protocol |
| 32 | MERIT-INP | MERIT Internodal Protocol |
| 33 | DCCP | Datagram Congestion Control Protocol |
| 34 | 3PC | Third Party Connect Protocol |
| 35 | IDPR | Inter-Domain Policy Routing Protocol |
| 36 | XTP | XTP |
| 37 | DDP | Datagram Delivery Protocol |
| 38 | IDPR-CMTP | IDPR Control Message Transport Proto |
| 39 | TP++ | TP++ Transport Protocol |
| 40 | IL | IL Transport Protocol |
| 41 | IPv6 | IPv6 encapsulation |
| 42 | IPv6 | SDRPSource Demand Routing Protocol |
| 43 | IPv6-Route | Routing Header for IPv6 |
| 44 | IPv6-Frag | Fragment Header for IPv6 |
| 45 | IDRP | Inter-Domain Routing Protocol |
| 46 | RSVP | Reservation Protocol |
| 47 | GRE | General Routing Encapsulation |
| 48 | DSR | Dynamic Source Routing Protocol |
| 49 | BNA | BNA |
| 50 | ESP | Encap Security Payload |
| 51 | AH | Authentication Header |
| 52 | I-NLSP | Integrated Net Layer Security TUBA |
| 53 | SWIPE | IP with Encryption |
| 54 | NARP | NBMA Address Resolution Protocol |
| 55 | MOBILE | IP Mobility |
| 56 | TLSP | Transport Layer Security Protocol using Kryptonet key management |
| 57 | SKIP | SKIP |
| 58 | IPv6-ICMP | ICMP for IPv6 |
| 59 | IPv6-NoNxt | No Next Header for IPv6 |
| 60 | IPv6-Opts | Destination Options for IPv6 |
| 61 | any host internal protocol | |
| 62 | CFTP | CFTP |
| 63 | any local network | |
| 64 | SAT-EXPAK | SATNET and Backroom EXPAK |
| 65 | KRYPTOLAN | Kryptolan |
| 66 | RVD | MIT Remote Virtual Disk Protocol |
| 67 | IPPC | Internet Pluribus Packet Core |
| 68 | any distributed file system | |
| 69 | SAT-MON | SATNET Monitoring |
| 70 | VISA | VISA Protocol |
| 71 | IPCV | Internet Packet Core Utility |
| 72 | CPNX | Computer Protocol Network Executive |
| 73 | CPHB | Computer Protocol Heart Beat |
| 74 | WSN | Wang Span Network |
| 75 | PVP | Packet Video Protocol |
| 76 | BR-SAT-MON | Backroom SATNET Monitoring |
| 77 | SUN-ND | SUN ND PROTOCOL-Temporary |
| 78 | WB-MON | WIDEBAND Monitoring |
| 79 | WB-EXPAK | WIDEBAND EXPAK |
| 80 | ISO-IP | ISO Internet Protocol |
| 81 | VMTP | VMTP |
| 82 | SECURE-VMTP | SECURE-VMTP |
| 83 | VINES | VINES |
| 84 | TTP | TTP |
| 84 | IPTM | Protocol Internet Protocol Traffic |
| 85 | NSFNET-IGP | NSFNET-IGP |
| 86 | DGP | Dissimilar Gateway Protocol |
| 87 | TCF | TCF |
| 88 | EIGRP | EIGRP |
| 89 | OSPFIGP | OSPFIGP |
| 90 | Sprite-RPC | Sprite RPC Protocol |
| 91 | LARP | Locus Address Resolution Protocol |
| 92 | MTP | Multicast Transport Protocol |
| 93 | AX.25 | AX.25 Frames |
| 94 | IPIP | IP-within-IP Encapsulation Protocol |
| 95 | MICP | Mobile Internetworking Control Pro. |
| 96 | SCC-SP | Semaphore Communications Sec. Pro. |
| 97 | ETHERIP | Ethernet-within-IP Encapsulation |
| 98 | ENCAP | Encapsulation Header |
| 99 | any private encryption scheme | |
| 100 | GMTP | GMTP |
| 101 | IFMP | Ipsilon Flow Management Protocol |
| 102 | PNNI | PNNI over IP |
| 103 | PIM | Protocol Independent Multicast |
| 104 | ARIS | ARIS |
| 105 | SCPS | SCPS |
| 106 | QNX | QNX |
| 107 | A/N | Active Networks |
| 108 | IPComp | IP Payload Compression Protocol |
| 109 | SNP | Sitara Networks Protocol |
| 110 | Compaq-Peer | Compaq Peer Protocol |
| 111 | IPX-in-IP | IPX in IP |
| 112 | VRRP | Virtual Router Redundancy Protocol |
| 113 | PGM | PGM Reliable Transport Protocol |
| 114 | any 0-hop protocol | |
| 115 | L2TP | Layer Two Tunneling Protocol |
| 116 | DDX | D-II Data Exchange (DDX) |
| 117 | IATP | Interactive Agent Transfer Protocol |
| 118 | STP | Schedule Transfer Protocol |
| 119 | SRP | SpectraLink Radio Protocol |
| 120 | UTI | UTI |
| 121 | SMP | Simple Message Protocol |
| 122 | SM | SM |
| 123 | PTP | Performance Transparency Protocol |
| 124 | ISIS over IPv4 | |
| 125 | FIRE | |
| 126 | CRTP | Combat Radio Transport Protocol |
| 127 | CRUDP | Combat Radio User Datagram |
| 128 | SSCOPMCE | |
| 129 | IPLT | |
| 130 | SPS | Secure Packet Shield |
| 131 | PIPE | Private IP Encapsulation within IP |
| 132 | SCTP | Stream Control Transmission Protocol |
| 133 | FC | Fibre Channel |
| 134 | RSVP-E2E-IGNORE | |
| 135 | Mobility Header | |
| 136 | UDPLite | |
| 137 | MPLS-in-IP | |
| 138 | manet | |
| 139 | HIP | |
| 140 | Shim6 | |
| 141 | WESP | |
| 142 | ROHC | |
| 143 − 252 | Unassigned | Unassigned |
| 253 | Use for experimentation and testing | |
| 254 | Use for experimentation and testing | |
| 255 | Reserved |
Further information can be found by researching RFC 5237.
Traffic Logging
When you enable logging on a security policy, the FortiGate unit records the scanning process activity that occurs, as well as whether the FortiGate unit allowed or denied the traffic according to the rules stated in the security policy. This information can provide insight into whether a security policy is working properly, as well as if there needs to be any modifications to the security policy, such as adding traffic shaping for better traffic performance.
Depending on what the FortiGate unit has in the way of resourses, there may be advantages in optimizing the amount of logging taking places. This is why in each policy you are given 3 options for the logging:
- No Log - Does not record any log messages about traffic accepted by this policy.
- Log Security Events - records only log messages relating to security events caused by traffic accepted by this policy.
- Log all Sessions - records all log messages relating to all of the traffic accepted by this policy.
Depending on the the model, if the Log all Sessions option is selected there may be 2 additional options. These options are normally available in the GUI on the higher end models such as the FortiGate 600C or larger. - Generate Logs when Session Starts
- Capture Packets
You can also use the CLI to enter the following command to write a log message when a session starts:
config firewall policy
edit <policy-index>
set logtraffic-start
end
Traffic is logged in the traffic log file and provides detailed information that you may not think you need, but do. For example, the traffic log can have information about an application used (web: HTTP.Image), and whether or not the packet was SNAT or DNAT translated. The following is an example of a traffic log message.
2011-04-13
05:23:47
log_id=4
type=traffic
subtype=other
pri=notice
vd=root
status="start"
src="10.41.101.20"
srcname="10.41.101.20"
src_port=58115
dst="172.20.120.100"
dstname="172.20.120.100"
dst_country="N/A"
dst_port=137
tran_ip="N/A"
tran_port=0
tran_sip="10.31.101.41"
tran_sport=58115
service="137/udp"
proto=17
app_type="N/A"
duration=0
rule=1
policyid=1
sent=0
rcvd=0
shaper_drop_sent=0
shaper_drop_rcvd=0
perip_drop=0
src_int="internal"
dst_int="wan1"
SN=97404 app="N/A"
app_cat="N/A"
carrier_ep="N/A"
If you want to know more about logging, see the Logging and Reporting chapter in the FortiOS Handbook. If you want to know more about traffic log messages, see the FortiGate Log Message Reference.
Policy Monitor
Once policies have been configured and enabled it is useful to be able to monitor them. To get an overview about what sort of traffic the policies are processing go to Policy > Monitor > Policy Monitor.
The window is separated into two panes.
Upper Pane
The upper pane displays a horizontal bar graph comparing the Top Policy Usage based on one of the following criteria:
- Active Sessions
- Bytes
- Packets
The criteria that the displayed graph is based on can be selected from the drop down menu in the upper right corner of the pane. The field name is Report By:.
The bars of the graph are interactive to an extent and can be used to drill down for more specific information. If you hover the cursor over the bar of the graph a small popup box will appear displaying more detailed information. If the bar of the graph is selected an entirely new window will be displayed using a vertical bar graph to divide the data that made up the first graph by IP address.
For example if the first graph was reporting usage by active sessions it would include a bar for each of the top policies with a number at the end showing how many sessions were currently going through that policy. If one of the bars of the graph was then selected the new bar graph would show the traffic of that policy separated by either Source Address, Destination Address or Destination Port. As in the other window, the selection for the reported criteria is in the upper right corner of the pane. If the parameter was by source address there would be a bar for each of the IP addresses sending a session through the policy and the end of the bar would show how many sessions.
To go back to the previous window of information in the graphs select the Return link in the upper left of the pane.
Lower Pane
The lower pane contains a spreadsheet of the information that the bar graph will derive their information from. The column headings will include:
- Policy ID
- Source Interface/Zone
- Destination Interface/Zone
- Action
- Active Sessions
- Bytes
- Packets
Fixed Port
Some network configurations do not operate correctly if a NAT policy translates the source port of packets used by the connection. NAT translates source ports to keep track of connections for a particular service.
From the CLI you can enable fixedport when configuring a security policy for NAT policies to prevent source port translation.
config firewall policy
edit <policy-id>
...
set fixedport enable
...
end
However, enabling fixedport means that only one connection can be supported through the firewall for this service. To be able to support multiple connections, add an IP pool, and then select Dynamic IP pool in the policy. The firewall randomly selects an IP address from the IP pool and assigns it to each connection. In this case, the number of connections that the firewall can support is limited by the number of IP addresses in the

Application Delivery control of Proxy and Fire well
XO___++XO DW on --- off real life in electronic

SPST circuit example and real-life example

Battery Backup in which basic function of a diode comes handy acting as a switch(ON when forward biased otherwise off )

Timer circuit diagrams, designs and schematics for timing based applications. Design of timer elements using digital IC chips and other components in it




IPV6 Proxy




Capacitive Proximity Sensor Circuit Diagram Rapid Prototyping Figure Block With Equivalent Resistance Of


Capacitive Proximity Sensor Circuit Diagram Of Clap Operated Remote Fan Switch


Capacitive Proximity Sensor Circuit Diagram Single Dual Wiring



How to make a Light Sensor / Darkness detector circuit on breadboard using LDR and a transistor. This circuit can be used to automatically control and turn on-off lights or any loads depending on the brightness of ambient light, by adding a relay at the output. The sensitivity a.k.a the brightness at which the circuit switches on the load can also be controlled by using a potentiometer.
Components Required:
- 1 LDR (Light Dependent Resistor or Photo-resistor)
- 1 npn Transistor (I used BC547)
- Resistors: 470R, 1K (For Light Sensor), 47K (For Dark Sensor)
- Potentiometer (Only if you need adjustable sensitivity): 10K (For Light Sensor), 100K (For Dark Sensor)
- Breadboard
- Power Supply: (3-12)V
- Few Breadboard connectors
Explanation of Circuit's Working:
The sensing component in this circuit is LDR (short form for Light Dependent Resistor or Photo-Resistor). The resistance of LDR depends on the intensity or brightness of light incident on it and the relation is of inverse proportionality. Which means that when the intensity of light increases, the LDR's resistance reduces and vice versa.
You can visually observe this effect by connecting the LDR in series with an LED and power up the circuit. Now if you reduce the brightness of ambient light, the LDR's resistance increases, resulting in lesser current flowing through the circuit (remember: more the resistance, less the current) and so you will observe that the LED's brightness reduces. Exactly the opposite happens when you increase the brightness of ambient light.
Although this LDR and LED in series circuit is the easiest to make, it has some limitations. Some of them are: you can't control the brightness at which the LED exactly turns on or off. Also, practically we would want the LED to turn on when it is dark and turn off when there's enough light. The maximum load that the circuit can drive is also limited. So for these reasons, we move on to more functional circuit using transistor.
Some transistor basics: For an npn-transistor, the emitter, collector are of n-junction and the base is of p-junction. For the transistor to turn on or to allow current to flow from collector to emitter, the voltage at the base should be above a certain threshold voltage.
We used a resistor in series with the LDR (basically a voltage divider) to convert the change in resistance of the LDR to change in voltage. This change in voltage at the common point between LDR and resistor is used the trigger the transistor by connecting it to base of the transistor.
In the Light Sensor Circuit (first diagram) when the brightness of light increases, the LDR's resistance reduces and so the voltage at the base of transistor increases (because if LDR resistance reduces, the voltage drop(gap) across the LDR, towards positive side decreases). Once this voltage increases above the required threshold voltage at the base, the LED turns on. You can now visualize what happens when you reduce the brightness of ambient light.
In the Dark Sensor Circuit (second diagram) when the LDR's resistance decreases when the intensity of light increases. So the voltage at the base of transistor increases when the brightness of light decreases, and once it gets past the minimum threshold voltage required at the base of transistor, it turns on the LED.
Circuit Diagram:


XO___+XO DW Back Talk Reverse Delay Analysis
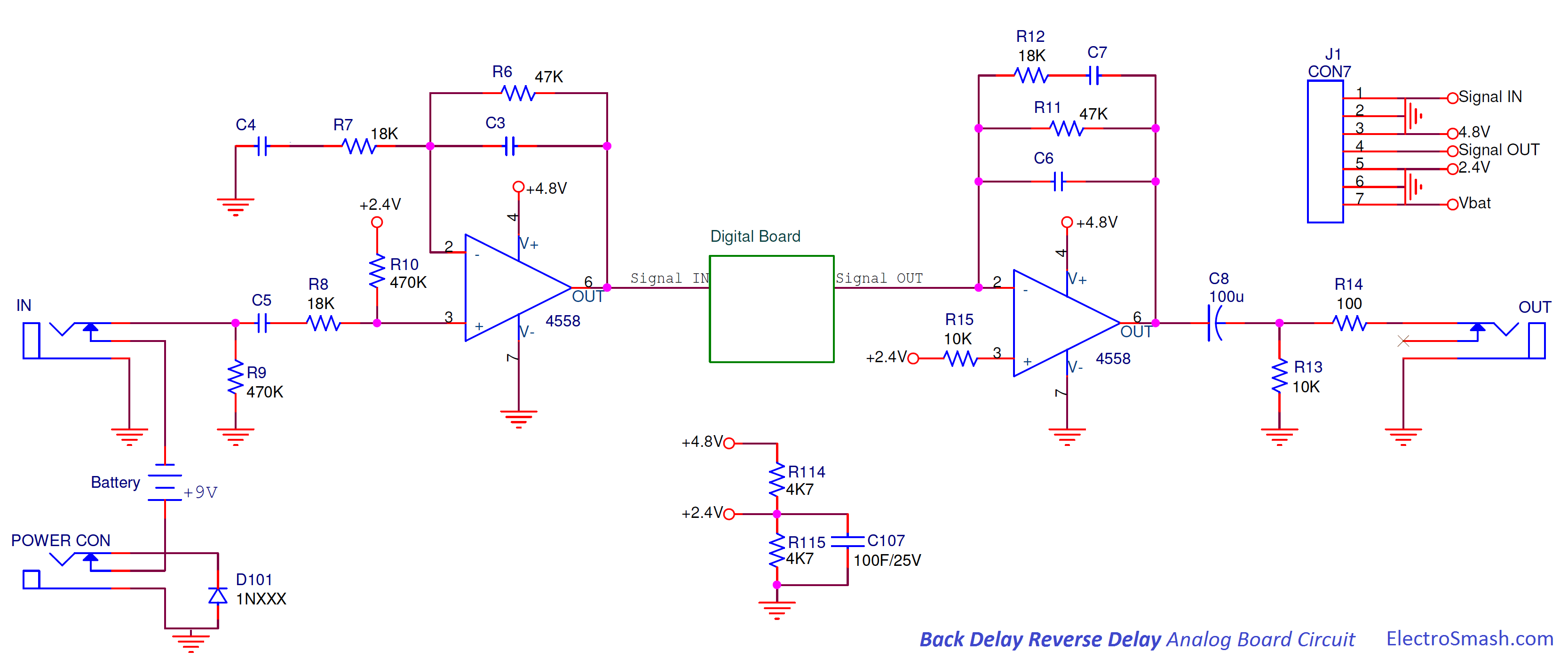
1. The Reverse Delay Effect.
The concept behind reverse delay device is simple: The input signal is passed through a memory buffer, where it is delayed for a short time and then sent reversed to the output.
Mixing the reverse delayed sound with the original signal, the pedal produces a single repeat following the original sound, but feedbacking a percentage of the delayed signal back to the input produces a repeating echo effect, where each subsequent echo is a little quieter than the previous one.
If the feedback gain is more than unity, the echoes will build up in level rather than decaying, resulting in an uncontrollable psychedelic howl.
If the feedback gain is more than unity, the echoes will build up in level rather than decaying, resulting in an uncontrollable psychedelic howl.
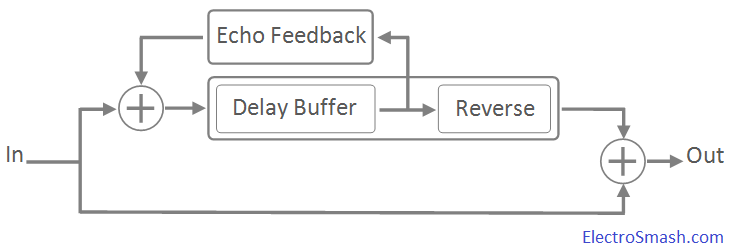 To illustrate the operation, a sawtooth signal is used as a guitar input signal.
To illustrate the operation, a sawtooth signal is used as a guitar input signal.- Original sawtooth input wave.
- In the beginning of the process, the wave is chopped according to the pedal knobs.
- Each of these pieces are reversed and delayed.
- At last, the original blue wave (2) and the reverse delayed green one (3) are blended creating the sound effect.
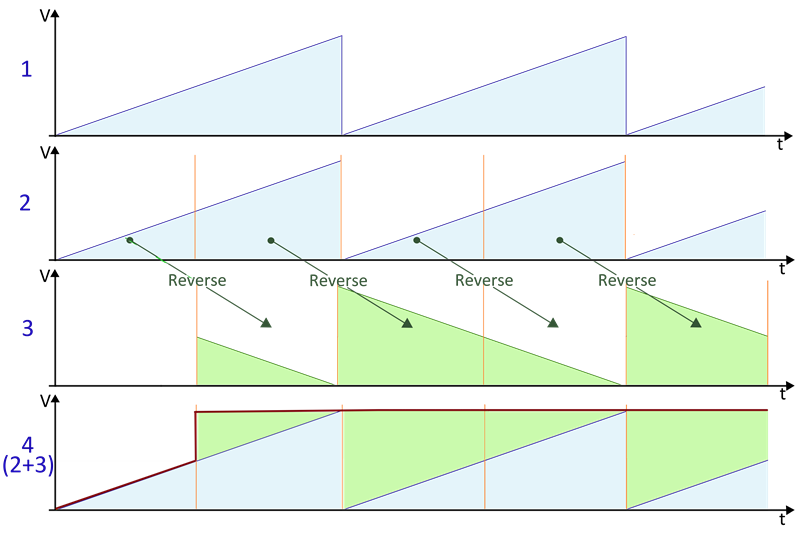
1.1 Reverse Delay Back Talk Control Knobs.
The pedal is commanded by 3 knobs: Mix, Speed, and Repetitions which will adjust the effect sound features:
- Mix: Controls the blend between the original dry signal and the wet processed signal, giving more presence to the genuine input wave or to the effected sound.
- Repetitions: Sets the number of times that the sampled delayed signal will be repeated over the original signal, creating an echo effect and controlling its depth.
- Speed: Adjusts the sample delay window, in other words, the amount of time that the signal is delayed and the duration of the delay. To illustrate this factor, in the below figure the reverse delay effect is applied over two sawtooth signals with a different speed/delay window:
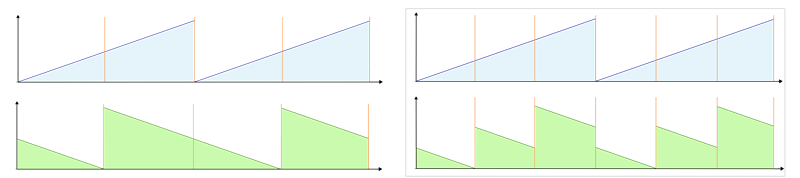
The circuit is implemented in two PCBs: the Analog PCB and the Digital PCB, linked by a 7-pin connector.
The input signal enters into the pedal through the Analog PCB, being buffered and prepared to the digital signal processing in the Digital PCB. After the digital effect is added by the Digital PCB, the signal is sent back to the Analog PCB to be buffered again and be prepared to the output.
The input signal enters into the pedal through the Analog PCB, being buffered and prepared to the digital signal processing in the Digital PCB. After the digital effect is added by the Digital PCB, the signal is sent back to the Analog PCB to be buffered again and be prepared to the output.
2.1 The Analog PCB Circuit.
The small input/output buffer board is a single layer PCB which contains 3 stages: the Voltage Bias, the Input Buffer, and the Output Buffer.
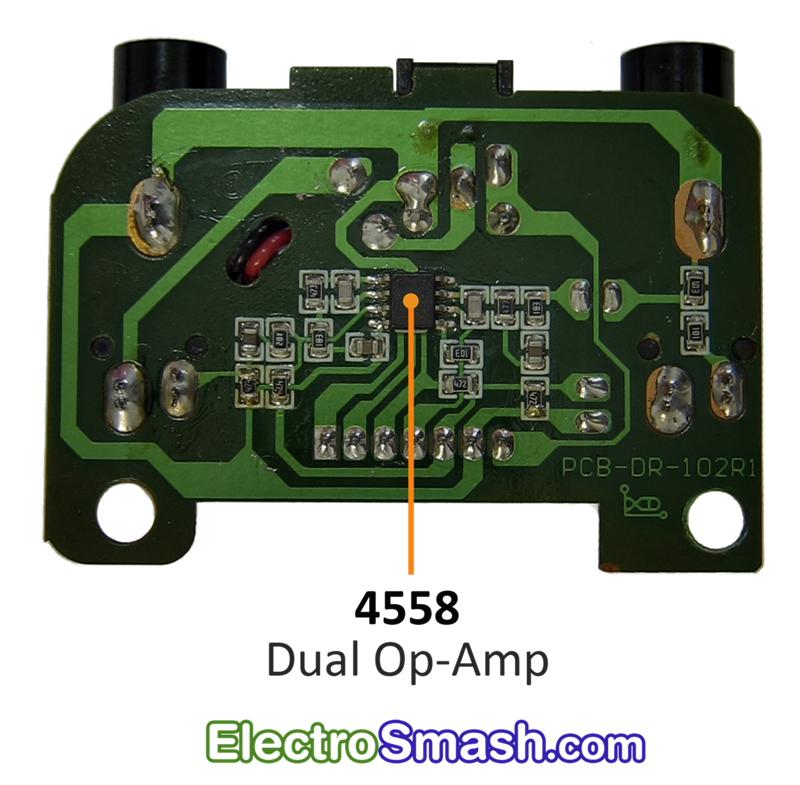 The circuit is based on the famous 4558 dual op-amp IC, one half of it will be used as Input Buffer and the other half as an Output Buffer. The 7-pin connector will send and receive signals between this PCB and the Digital Board.
The circuit is based on the famous 4558 dual op-amp IC, one half of it will be used as Input Buffer and the other half as an Output Buffer. The 7-pin connector will send and receive signals between this PCB and the Digital Board.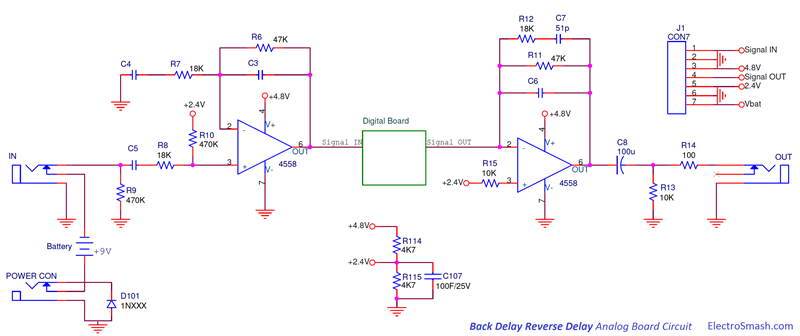
The circuit is based on the famous 4558 dual op-amp IC, one half of it will be used as Input Buffer and the other half as an Output Buffer. The 7-pin connector will send and receive signals between this PCB and the Digital Board.2.1.1 Voltage Bias Block.
The Voltage Bias Block provides the voltage levels to the 4558 dual op-amp and electrical protection against reverse polarity supply.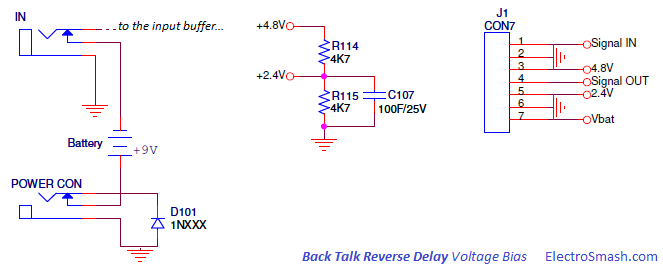
- The resistor divider (R114, R115) generates +2.4 volts from +4.8V. The +2.4V resistors junction is decoupled to ground with a large value electrolytic capacitor C907 (100uF) to remove all ripple from the supply voltage.
- The diode D101 protects the pedal against reverse polarity connections.
- The stereo in jack is used as an on-off switch, switching the battery (-) terminal to ground when the guitar jack is connected.
2.1.2 Input Buffer Stage.
The Input Buffer grants high input impedance, frequency filtering and voltage gain, keeping signal integrity and preparing it to be digitalized.
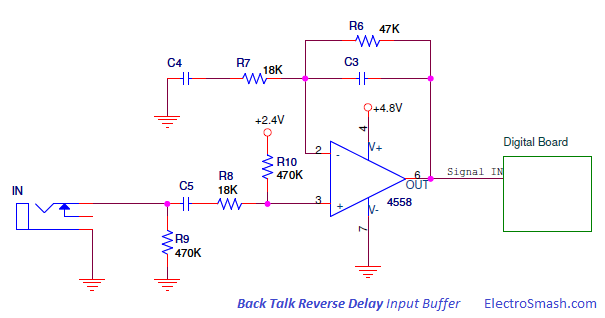
Not considering for the moment the caps C3 and C4, the non-inverting amplifier gain can be calculated as:
Not considering for the moment the caps C3 and C4, the non-inverting amplifier gain can be calculated as:

The capacitors C3 and C4 create a pass-band filter (low pass + high pass) where:
- Low pass = R6C3 network with fc=1/(2πR6C3)
- High pass = R7C4 network with fc=1/(2πR7C4)
This pass-band filter is similar to the non-inverting amp in the Tube Screamer. It will add a subte honky tone but besides this small tone modification, it is important for digital effects to eliminate the excess of bass and treble due to the bandwidth limitation in the analog to digital conversion stage.
- The network C5 R8 R10 and the input impedance of the 4558 (Zin=50MΩ) also creates a high pass filter to remove the DC component from the input line.
- The resistor R9 next to the input jack to ground is a pull-down resistor which avoids popping sounds when the pedal is switched on. The input pull-down resistor becomes the maximum input impedance of the pedal.
2.1.3 Output Buffer Stage.
The Output Buffer procures low output impedance, filtering and some voltage Gain, keeping signal integrity and preparing it to the output.
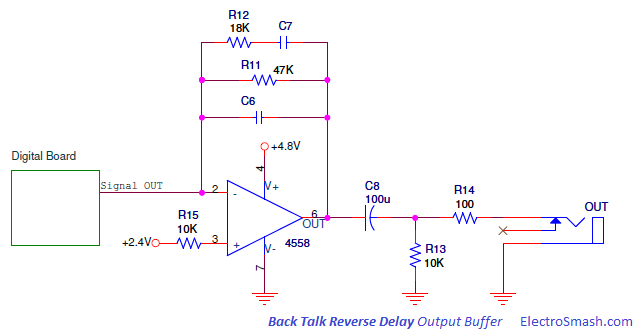
The op amp is in inverting configuration, C6 will smooth high harsh harmonics and C8 is a bass cut filter, muting the excess of bass to be delivered to the next stage.
The op amp is in inverting configuration, C6 will smooth high harsh harmonics and C8 is a bass cut filter, muting the excess of bass to be delivered to the next stage.
The 2-layers PCB can be broken down into simpler blocks: Power Supply stage, Potentiometers & Footswitch ADC block, Audio Codec and Memory Management.
The circuit is based in the 8-bit Atmel microcontroller AT1200S which manages few peripherals. The input signal coming from the Analog Board is primarily digitalized by the PCM3500E Audio Codec and the resulting data is processed by the Micro using the RAM memory to generate the reverse delay effect. Finally, the digital signal is translated back to analog levels using again the PCM3500E Codec. Two linear voltage regulators will grant 5.0 and 3.6 of voltage supply for the parts.
The circuit is based in the 8-bit Atmel microcontroller AT1200S which manages few peripherals. The input signal coming from the Analog Board is primarily digitalized by the PCM3500E Audio Codec and the resulting data is processed by the Micro using the RAM memory to generate the reverse delay effect. Finally, the digital signal is translated back to analog levels using again the PCM3500E Codec. Two linear voltage regulators will grant 5.0 and 3.6 of voltage supply for the parts.
2.2.1 Power Supply Stage.
The Power Supply Stage is made up of two Holtek voltage regulators, they will provide voltage supply to all stages in the pedal.
- The IC5 HT7550 is a three-terminal 5V@100mA low dropout CMOS linear voltage regulator, supplying 5.0 volts.
- The 9V battery primary voltage source and the 5.0V output are decoupled to ground with several capacitors C9, C8, C29 (4.7uF elec.)C30 (4.7uF elec.) and C5 (100uF elec) to remove all ripple from supply voltage.
- The R14C41 network generates +4.8V Slow supply, which is used only by the 4558 Dual Op-Amp and the HC4066 Analog Switch, grants a smooth supply ramp due capacitor C41 charge/discharge time:
Time Charge/Discharge = 5*R14*C41 = 5*100Ω*10uF = 5ms
- The IC4 HT7136 is a three-terminal 3.6V@30mA low dropout CMOS linear voltage regulator, supplying 3.6 volts only to the Audio Codec.
- The 9V battery primary voltage source and the 3.6V output are decoupled to ground with several capacitors C7, C10, and C6 (100uF elec.) to remove all ripple from supply voltage.
2.2.2 Power On Reset Circuit.
It is important to keep under control the system at start-up estate. Otherwise, the microcontroller may initially operate in an unpredictable fashion.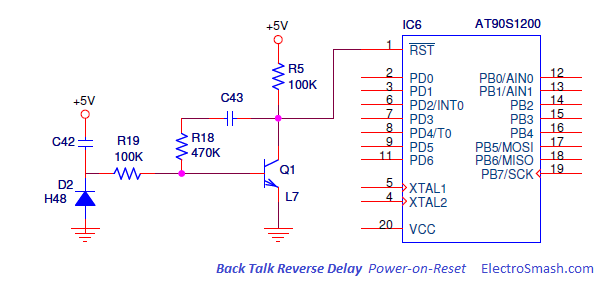
The Power-On-Reset circuit asserts a reset signal whenever Vcc supply falls below a reset threshold. The reset time-out period can be adjusted using C42. Reset remains asserted for an interval programmed by C42, after Vcc has risen obove the threshold voltage.
2.2.3 Potentiometers & Footswitch ADC Block.
The VR3 Mix, VR1 Speed, VR2 Repetitions 3K3 potentiometers and the pedal footswitch SW1 are read by the microcontroler through an Analog to Digital Converter IC7 TLC0834C.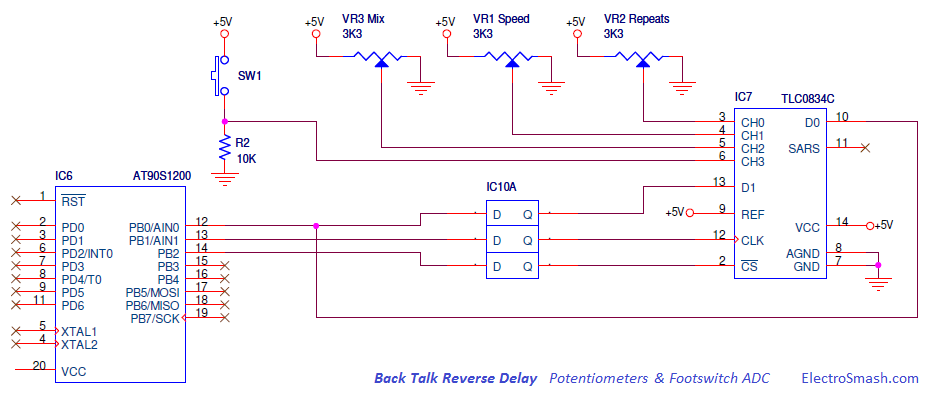
The microcontroler does not have enough embedded ADCs to read all the analog levels from the potentiometers and the footswitch, so as to do it and save the maximum resources, the Texas Instruments TLC0834C ADC is used. The result of these measures are sent in a single serial line to the microcontroller to be processed.
- D-Latches from IC10 HC373 multiplex the port B of the micro, keeping these lines accessible for other purposes at the same time.
2.2.4 Audio Codec.
The Audio Codec is a single chip that encodes the guitar analog input as a digital serial signal to be taken by the microcontroller. It also decodes the processed digital signals from the microcontroller back into analog. So, the Codec contains both an Analog-to-digital converter (ADC) and Digital-to-analog converter (DAC) running off the same clock at 11.286 MHz.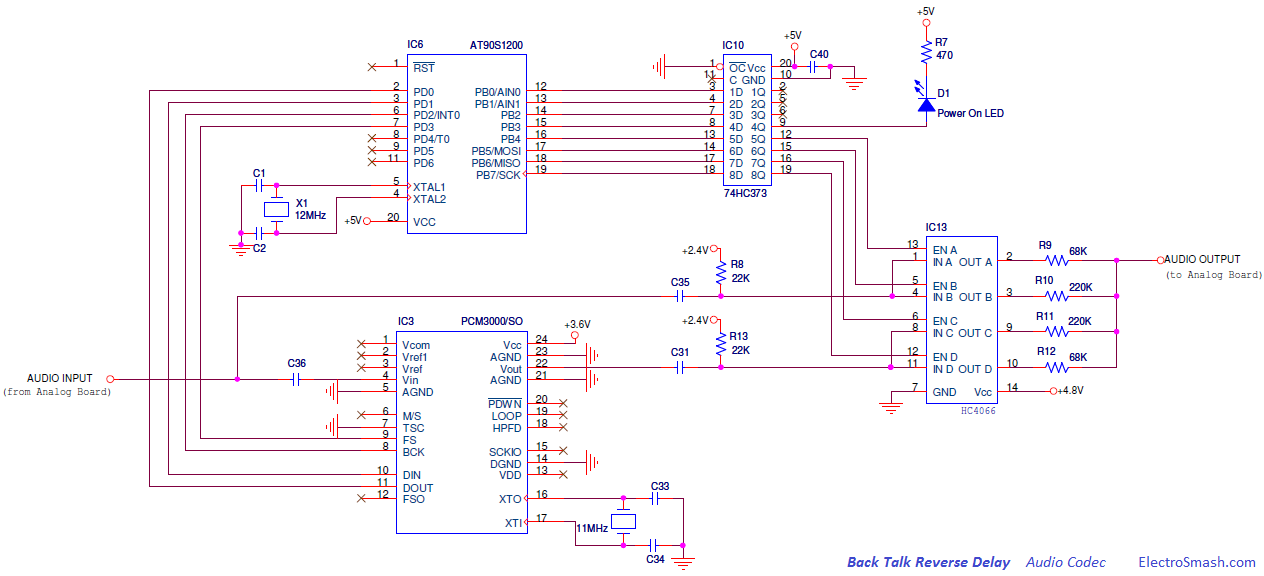
The PCM3500E by Burr-Brown contains 16-bit Delta Sigma ADC and DAC, with a sampling frequency of 22.05KHz (11.286/512). The chip also includes anti-aliasing filter, digital high-pass filter for DC blocking, and output low-pass filter to enhance performance.
The dry input signal is encoded or digitalized by the ADC block of the PCM3500 and sent in serial mode to the micro. The microcontroller manage and modify the digitalized signal adding the back delay effect and finally the wet signal is translated back to analog using the DAC block of the PCM3500.
- Using the Analog Switch HC4066 commanded by the microcontroller, the input signal can skip all the digital signal processing and go straight to the output when the pedal is in off/bypass mode.
- The Power on diode D1 is turned on when the push footswitch is pressed, showing whether the effect is active or not.
2.3 Memory Management.
All delay based pedals need some mechanism to store the audio in order to play it later as a delayed version. This method can be magnetic tape in old pure analog effects, capacitors in bucket brigade delay devices or just RAM memory in pure digital pedals.
The two ISS ram chips supply 8-bits of 32K memory each one, these parts can be associated as 32K of 16-bits memory. The Audio Codec works at 16-bits with a sampling period of 22.05KHz, with this speed, the memory system is able to store 32K/22.05KHz = 1.45 seconds of delay.
In the Back Talk pedal, the main bottleneck in the hardware design is the way to manage two 28 pined memory chips with a limited free lines. To do so, 16 d-type latches are needed to extend the number of available lines multiplexing the port B of the micro.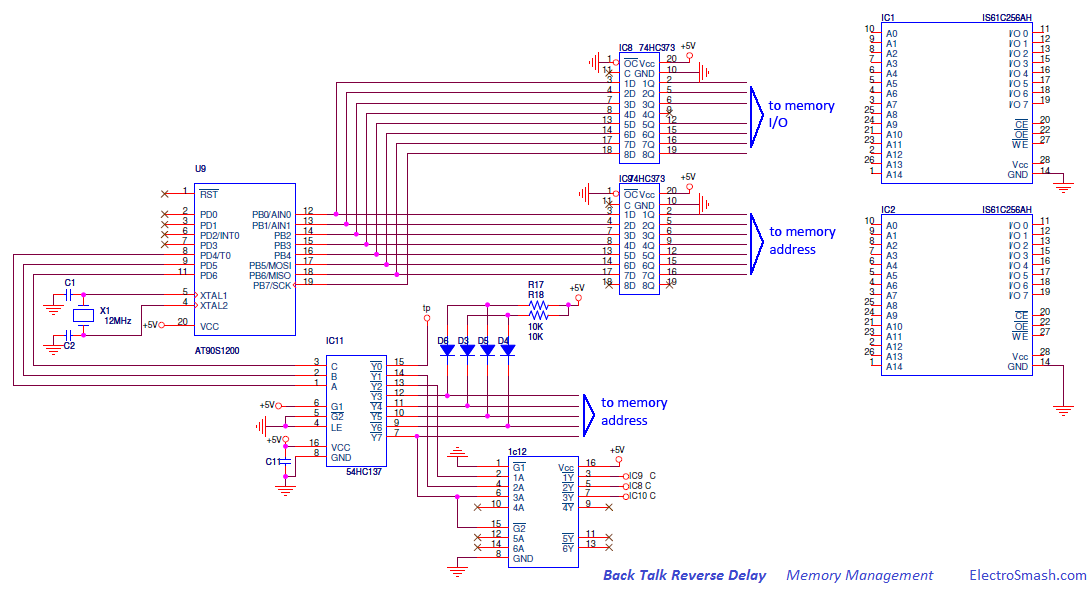
The Microcontroler receives the digitalized guitar signal from the PCM3500 Audio Codec in serial mode. Then, the data serial string is processed and sent in parallel to the RAM memory through the HC373 D-latches; the IC9 D-Latch is used to drive the address lines and the IC8 manage the memory I/O lines.
Depending on the user potentiometers (mix, speed, repetitions) the micro will apply different adjustments in the feedback, deep of memory buffer and mixing algorithm.
- The HC137 3-to-8 Line Decoder is in charge of enable the latches and also address the memory extending the number of available lines. The diodes D3, D4, D5 and D6 are used to adjust levels between parts.
- The IC12 HC368 Hex inverting buffers adapt the levels to negative logic to engage ICs.
3. Back Talk Reverse Delay Clon.
After understanding the circuit and Danelectro approach for this pedal, it can be concluded that the reverse engineering clone is pretty discouraging. Despite the relatively complex PCB layout and all surface montage devices, some of then obsoletes, the git of the pedal remains in the source code of the microcontroller which is not available.
The hardware design indicates that the program code must be complex as well; the serial data encryption and decryption for the Audio Codec and the ADC, the 24 latches, 2 memories and decoder management for real time signal processing is not trivial.
Anyway, is a good learning exercise to see how the big ones design DSP pedals, so you can for sure gain some ideas for you own designs, good luck!
4. Resources.
Danelectro pedals in Wikipedia.
Pulldown Resistors by AMZFX.
Pulldown Resistors vs Input Impedance by AMZFX.
Sequencer Delay Masterclass in Sound on Sound.
Practical Modeling of Bucket-Brigade-Device CircitsCircits by C. Raffel & J. Smith.
Pulldown Resistors by AMZFX.
Pulldown Resistors vs Input Impedance by AMZFX.
Sequencer Delay Masterclass in Sound on Sound.
Practical Modeling of Bucket-Brigade-Device CircitsCircits by C. Raffel & J. Smith.
4.1 Back Talk Reverse Delay Datasheets.
IC1, IC2, IS61C256AH 32Kx8 CMOS High Speed Static RAM Memory.
IC3, PCM3500E 16bit Mono audio Codec / 16bit Delta Sigma ADC/DAC.
IC4, HT7136 30mA 3.6V voltage regulator.
IC5, HT7550 100mA 5.0V voltage regulator.
IC6, AT90S1200 8bit Microcontroler 1K Flash memory.
IC7, TLC0834C Analog to Digital converter with serial control.
IC8, IC9, IC10, HC373 Octal Transparent D-type Latches with 3-state outputs.
IC11, HC137 3-to-8 Line Decoder Demultiplexer with Address Latches.
IC12, HC368 Hex inverting buffers and line drivers with 3-state output.
IC13, HC4066 Quad Analog Switch.
IC3, PCM3500E 16bit Mono audio Codec / 16bit Delta Sigma ADC/DAC.
IC4, HT7136 30mA 3.6V voltage regulator.
IC5, HT7550 100mA 5.0V voltage regulator.
IC6, AT90S1200 8bit Microcontroler 1K Flash memory.
IC7, TLC0834C Analog to Digital converter with serial control.
IC8, IC9, IC10, HC373 Octal Transparent D-type Latches with 3-state outputs.
IC11, HC137 3-to-8 Line Decoder Demultiplexer with Address Latches.
IC12, HC368 Hex inverting buffers and line drivers with 3-state output.
IC13, HC4066 Quad Analog Switch.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
e- The retreat of time for e- DIREW on Cyberspace clock countdown
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++